

1 引言
Poisson-Nernst-Planck 方程, 简称为 PNP 方程, 可用来描述生物分子系统的电扩散反应过程, 并且该模型已经被广泛的应用于电化学、半导体、生物膜通道等领域[1]. 由于 PNP 方程是一个非线性的耦合系统, 常需要利用解耦方法进行求解, 而 Gummel 迭代是一种广泛应用于求解 PNP 方程的解耦方法. 对于实际 PNP 问题, 通常需要利用松弛参数才能保证 Gummel 迭代收敛. 而松弛参数的取值对 Gummel 迭代的收敛效果影响较大, 传统的 Gummel 迭代法都是按照经验来给定松弛参数取值, 然而, 按照经验取值一般不是较优松弛参数, 可能造成 PNP 方程迭代时间很长, 迭代速度很慢.
近年来机器学习技术被引入到各种模型的数值计算中, 通过预测出较优参数, 来加速数值解的收敛, 降低数值模拟中的计算成本. 比如 Mukerji 等人[2] 利用随机森林回归加速多相多孔介质流的求解. Jiang 等人[3] 引入了高斯过程回归 (GPR) 来预测交替方向隐式方法 (ADI) 中的参数, 以提高求解的效率和准确性. Uyan[4] 使用机器学习方法来预测水下传感器网络参数, 提高水下传感器网络的性能和可靠性. Sudhir[5] 使用人工神经网络 (ANN) 和递归神经网络 (RNN) 模型来预测车轮接触参数, 来减少脱轨倾向、车轮磨损和能耗. 我们注意到最近也出现了少量利用机器学习方法求解 PNP 方程的工作, 如文献 [6] 利用接口神经网络方法 (INNs) 求解 PNP 方程, 加速方程收敛和提高数值精度. 但是该文主要侧重于利用机器学习算法求解, 而不是用于预测参数. 据我们所知, 目前还没有利用机器学习来预测 PNP 方程迭代算法参数的相关工作. 本文针对一类 PNP 方程, 利用 GPR 方法对 Gummel 迭代的松弛参数进行预测, 得到较优参数, 提高 Gummel 迭代的收敛效率. 首先, 针对 PNP 方程的 Gummel 迭代设计了 GPR 方法. 其次, 利用 Box-Cox 转换算法, 对 GPR 的训练集进行处理, 使其接近高斯分布, 提高 GPR 方法的准确性. 然后基于 GPR 方法及 Box-Cox 转换算法给出一种新的 Gummel 算法. 数值实验表明: 这一新算法与经典的 Gummel 算法相比, 在收敛阶相同的情况下, 计算效率更高.
2 PNP 方程及有限元离散
本文考虑一种在半导体领域中的 PNP 方程[7]
其中静电势
其中,
2.1 弱形式及有限元离散
设
则方程 (2.1)-(2.3) 的变分形式为: 寻找
区域
其中, 方程 (2.1)-(2.3) 的标准有限元离散如下 寻找
2.2 Gummel 迭代
PNP 方程是一个强耦合、强非线性的偏微分方程组, 仅在极少数情形下能找到它的解析解. 由于 PNP 方程由两个以上的偏微分方程组成, 一般来说, 在大规模问题的应用中, 使用解耦方法求解比直接求解更方便, 并且数值实现更容易和高效. 目前用于求解 PNP 方程的主要解耦方法是 Gummel 迭代. Gummel 迭代不仅具有快速求解、较好的收敛性和稳定性, 而且可以根据实际需求灵活地调整迭代次数和收敛准则, 以达到所需的数值解精度, 其具体过程见算法 1.

算法 1 中的
3 高斯过程回归
本节, 首先参考文献 [9] 的工作设计了针对 PNP 方程的 Gummel 迭代的 GPR 算法. 然后利用 Box-Cox 转换方法, 对 GPR 的训练集进行预处理. 最后我们给出基于 GPR 方法的新 Gummel 迭代算法.
3.1 PNP 方程 Gummel 迭代的 GPR 算法
高斯过程是指多变量高斯随机变量到无限 (可数或连续) 指数集的自然推广. GPR 是一种灵活的非参数回归方法, 对数据的分布假设较少, 它可以适应各种形式的数据, 并且在没有明确的函数形式假设下进行建模.
设有一组训练集
其中
给定新的输入样本
其中协方差矩阵
列向量和行向量
在这里核函数
其中
利用条件概率可求出新输入 Gummel 迭代时间
综上, 对于测试集中的输出松弛参数
具体的 PNP 方程的 Gummel 迭代的 GPR 算法如下
3.2 Box-Cox 转换
对于 PNP 方程的输入样本
文献 [11] 指出经过 Box-Cox 变换得到的
下面给出具体的 PNP 方程的 Box-Cox 转换算法
3.3 基于 GPR 方法的新 Gummel 迭代算法
下面基于算法 2 和算法 3, 给出基于 GPR 方法选取松弛参数新 Gummel 迭代算法


4 数值实验
为验证新 Gummel 算法的有效性, 本文选取一个三维稳态 PNP 模型, 利用 GPR 方法选取 PNP 方程 Gummel 迭代的较优参数, 并与经典的 Gummel 算法进行比较. 实验环境为个人电脑, CPU 为 2.10GHz, 内存为 32GB, 采用 MATLAB 语言编写计算程序, 所有计算结果均来自同一实验环境.
算例 4.1 考虑方程 (2.1)-(2.3), 其求解区域
其中,
4.1 无量纲化
本文方程 (2.1)-(2.3) 对应的参数数值及符号如下表所示
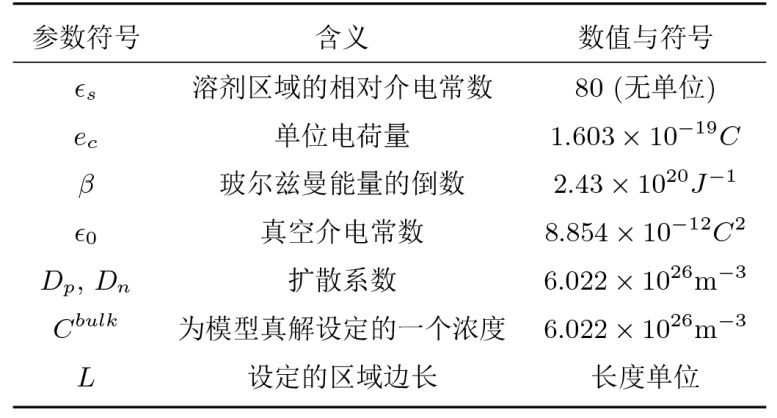
通过无量纲化将方程 (2.1)-(2.3) 转化为 (4.1) 来进行求解.
其中当求解区域为
4.2 数值结果

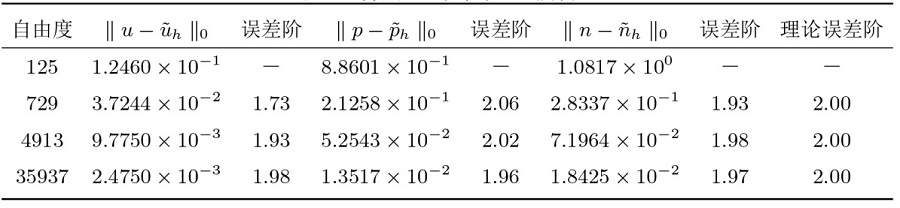
其次比较经典 Gummel 迭代算法 1 与算法 4 的计算效率. 下面图1 中的 (a) 和 (b) 分别给出了算法 4 与算法 1 迭代步数与 CPU 时间, 其中“GPR”(红色-o-线) 表示算法 4 的 Gummel 迭代步数或 CPU 时间, 0.1 到 0.9 为算法 1 中
图1
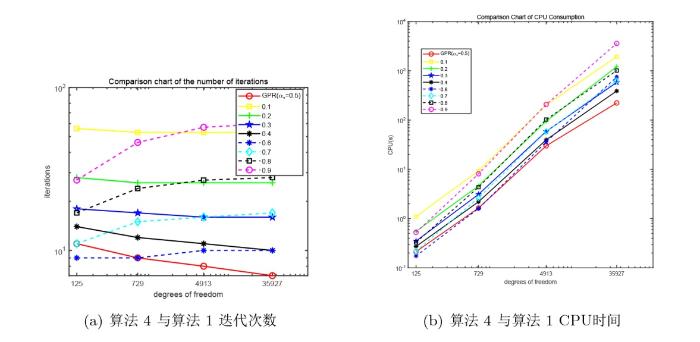
图1 的结果表明, 算法 4 与算法 1 的其他松弛参数取值相比, 在相同的自由度下迭代次数和 CPU 的时间更少, 说明了新 Gummel 算法的有效性. 注意到算法 4 虽然包含算法 2 的训练时间, 但是由于松弛参数
最后, 表3 给出了算法 4 在不同的网格尺度下的迭代次数及 CPU 时间. 结果表明, 随着

5 结论
我们研究了利用高斯过程回归方法对 PNP 方程中 Gummel 迭代的松弛参数进行选取, 获得一个较优的松弛参数. 通过对经典的 Gummel 迭代的松弛参数取不同取值进行测试表明, 基于 GPR 方法的新 Gummel 迭代算法, 在 PNP 方程迭代求解过程中, 迭代次数更少, 迭代时间更短.
参考文献
Poisson-Nernst-Planck equations for simulating biomolecular diffusion-reaction processes I: Finite element solutions

In this paper we developed accurate finite element methods for solving 3-D Poisson-Nernst-Planck (PNP) equations with singular permanent charges for electrodiffusion in solvated biomolecular systems. The electrostatic Poisson equation was defined in the biomolecules and in the solvent, while the Nernst-Planck equation was defined only in the solvent. We applied a stable regularization scheme to remove the singular component of the electrostatic potential induced by the permanent charges inside biomolecules, and formulated regular, well-posed PNP equations. An inexact-Newton method was used to solve the coupled nonlinear elliptic equations for the steady problems; while an Adams-Bashforth-Crank-Nicolson method was devised for time integration for the unsteady electrodiffusion. We numerically investigated the conditioning of the stiffness matrices for the finite element approximations of the two formulations of the Nernst-Planck equation, and theoretically proved that the transformed formulation is always associated with an ill-conditioned stiffness matrix. We also studied the electroneutrality of the solution and its relation with the boundary conditions on the molecular surface, and concluded that a large net charge concentration is always present near the molecular surface due to the presence of multiple species of charged particles in the solution. The numerical methods are shown to be accurate and stable by various test problems, and are applicable to real large-scale biophysical electrodiffusion problems.
Machine learning acceleration for nonlinear solvers applied to multiphase porous media flow
DOI:10.1016/j.cma.2021.113989 URL [本文引用: 1]
A General alternating-direction implicit framework with Gaussian process regression parameter prediction for large sparse linear systems
Machine Learning Approaches for Underwater Sensor Network Parameter Prediction
Prediction of rail-wheel contact parameters for a metro coach using machine learning
INN: Interfaced neural networks as an accessible meshless approach for solving interface PDE problems
A stabilized finite element method for the Poisson-Nernst-Planck equations in three-dimensional ion channel simulations
Superconvergent gradient recovery for nonlinear Poisson-Nernst-Planck equations with applications to the ion channel problem
Gaussian processes for machine learning
Gaussian processes (GPs) are natural generalisations of multivariate Gaussian random variables to infinite (countably or continuous) index sets. GPs have been applied in a large number of fields to a diverse range of ends, and very many deep theoretical analyses of various properties are available. This paper gives an introduction to Gaussian processes on a fairly elementary level with special emphasis on characteristics relevant in machine learning. It draws explicit connections to branches such as spline smoothing models and support vector machines in which similar ideas have been investigated. Gaussian process models are routinely used to solve hard machine learning problems. They are attractive because of their flexible non-parametric nature and computational simplicity. Treated within a Bayesian framework, very powerful statistical methods can be implemented which offer valid estimates of uncertainties in our predictions and generic model selection procedures cast as nonlinear optimization problems. Their main drawback of heavy computational scaling has recently been alleviated by the introduction of generic sparse approximations.13,78,31 The mathematical literature on GPs is large and often uses deep concepts which are not required to fully understand most machine learning applications. In this tutorial paper, we aim to present characteristics of GPs relevant to machine learning and to show up precise connections to other "kernel machines" popular in the community. Our focus is on a simple presentation, but references to more detailed sources are provided.
An analysis of transformations
An error analysis for the finite element approximation to the steady-state Poisson-Nernst-Planck equations

{kind=link}
{kind=link}