

1 引言
考虑如下无约束优化问题
其中函数
其中
近些年, 为寻求数值效果好且有收敛性的共轭梯度法, 许多学者对上述四种著名方法进行改进. 例如, 为取得 HS 方法理论上的相关性质, Yao 等[6] 给出一个改进
结果表明, 强 Wolfe 线搜索下对应的 YWH 方法能产生下降方向并具有全局收敛性. Zhang[7]对 YWH 方法稍作调整, 有
最近, Zhu 等[9]借助重启条件, 引入如下两个共轭参数
和
其形式上亦可视为
EHS-RD1 搜索方向.
其中参数
搜索方向.
其中参数
为简便, 在弱 Wolfe 线搜索 (1.4) 产生步长
下面给出共轭梯度法收敛性分析中常用假设 (A1)-(A2) 及 Zoutendijk 条件[24].
(A1)
(A2)
引理1.1[24] 设假设 (A1)-(A2) 成立, 考虑迭代点
证 根据弱 Wolfe 线搜索 (1.4) 第一个不等式, 搜索方向的下降条件及假设 (A1) 知, 数列
此联立线搜索 (1.4) 第二个不等式, 有
上式结合线搜索 (1.4) 第一个不等式, 得
其中
从而结论成立.
该文其余部分组织如下: 第 2 节和第 3 节分别给出 EHS-RD1 方法和 EHS-RD2 方法的下降性及收敛性结果; 第 4 节使用无约束优化问题进行模拟测试, 以验证 EHS-RD1 方法和 EHS-RD2 方法的数值有效性.
2 EHS-RD1 方法
引理2.1 由 EHS-RD1 方法产生的搜索方向有下降性. 并且当
证 数学归纳法. 当
(i) 当
因此
上式联立
(ii) 若
证毕.
定理2.1 设假设 (A1)-(A2) 成立, 迭代点
证 反证法, 设结论不成立, 则存在
(i) 若
(ii) 若
两边再同除以
(iii) 若
又因
联立 (i)-(iii), 得
即
3 EHS-RD2 方法
引理3.1 EHS-RD2 搜索方向有充分下降性, 即
证 数学归纳法. 当
当
(i) 若
进一步, 得
(ii) 若
从而, 有
定理3.1 设假设 (A1)-(A2) 成立, 迭代点
证 反证法, 设结论不成立, 则存在
(i) 若
(ii) 若
两边再同除以
另一方面, 利用
结合
和
成立, 于是
进而, 由上式和 (3.1) 式得
(iii) 若
又由于
联立上述 (i)-(iii) 得
于是
4 数值试验
该节进行两组试验分别验证 EHS-RD1 方法和 EHS-RD2 方法的数值性能. 所有测试均在弱 Wolfe 线搜索 (1.4) 下进行, 其参数选取与文献[9] 保持一致, 即
数值试验结果对迭代次数 (Itr), 函数计算次数 (NF), 梯度计算次数 (NG), CPU 计算时间 (Tcpu) 及方法停止时梯度值
图1
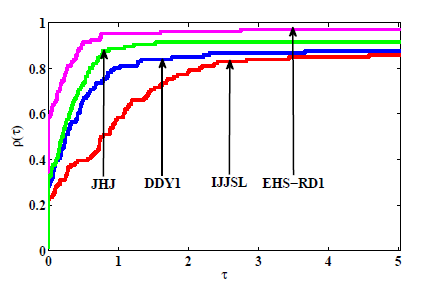
图2
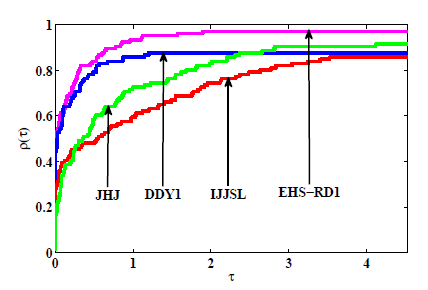
图3
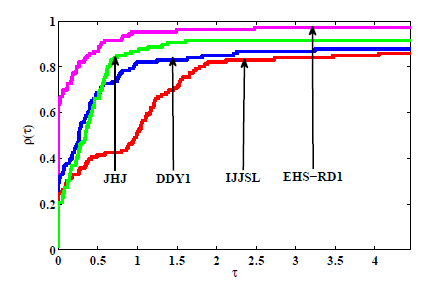
图4
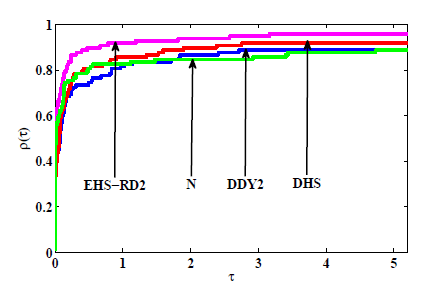
图5
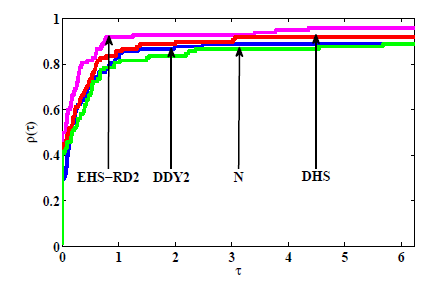
图6
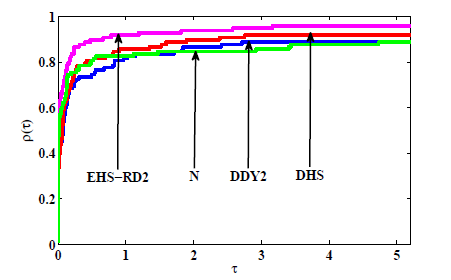
图7
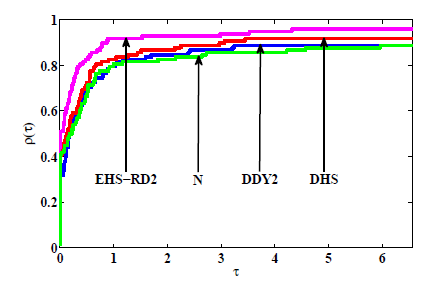
图8
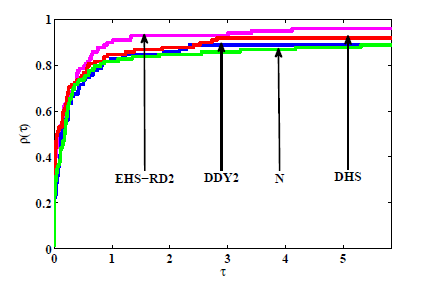
参考文献
Methods of conjugate gradients for solving linear systems
DOI:10.6028/jres.049.044 URL [本文引用: 1]
Function minimization by conjugate gradients
Note sur la convergence de méthodes de directions conjuées
The conjugate gradient method in extremal problems. USSR Computational Mathematics and
A nonlinear conjugate gradient method with a strong global convergence property
DOI:10.1137/S1052623497318992 URL [本文引用: 1]
A note about WYL's conjugate gradient method and its application
DOI:10.1016/j.amc.2007.02.094 URL [本文引用: 3]
An improved Wei-Yao-Liu nonlinear conjugate gradient method for optimization computation
DOI:10.1016/j.amc.2009.08.016 URL [本文引用: 2]
Wolfe 线搜索下一个新的全局收敛共轭梯度法
A new globally convergent conjugate gradient method with Wolfe line search
Two modified DY conjugate gradient methods for unconstrained optimization problems
An improved Polak-Ribière-Polyak conjugate gradient method with an efficient restart direction
DOI:10.1007/s40314-020-01383-5 [本文引用: 3]
A modified self-scaling memoryless Broyden-Fletcher-Goldfarb-Shanno method for unconstrained optimization
DOI:10.1007/s10957-014-0528-4 URL [本文引用: 2]
A hybrid conjugate gradient method with descent property for unconstrained optimization
DOI:10.1016/j.apm.2014.08.008 URL [本文引用: 3]
Another improved Wei-Yao-Liu nonlinear conjugate gradient method with sufficient descent property
DOI:10.1016/j.amc.2011.12.091 URL [本文引用: 1]
Wolfe 线搜索下一个全局收敛的混合共轭梯度法
DOI:10.12286/jssx.2012.1.103
[本文引用: 2]

对无约束优化问题, 本文给出了一个新的混合共轭梯度法公式. 在标准Wolfe非精确线搜索下,证明了由新公式所产生的算法具有下降性和全局收敛性, 并对算法进行了数值试验, 其结果表明该算法是有效的.
A new globally convergent mixed conjugate gradient method with Wolfe line search
DOI:10.12286/jssx.2012.1.103
[本文引用: 2]
对无约束优化问题, 本文给出了一个新的混合共轭梯度法公式. 在标准Wolfe非精确线搜索下,证明了由新公式所产生的算法具有下降性和全局收敛性, 并对算法进行了数值试验, 其结果表明该算法是有效的.
一个充分下降的谱三项共轭梯度法
DOI:10.12387/C2020073
[本文引用: 1]
谱三项共轭梯度法作为共轭梯度法的一种重要推广,在求解大规模无约束优化问题方面具有较好的理论特征与数值效果.本文运用强Wolfe非精确线搜索条件设计产生一个新的谱参数,结合修正Polak-Ribiére-Polyak共轭参数计算公式建立了一个Polak-Ribiére-Polyak型谱三项共轭梯度算法.新算法无论采用何种线搜索条件求步长,每步迭代均满足充分下降条件.在常规假设条件下,采用强Wolfe非精确线搜索条件产生步长,证明了算法的强收敛性.最后,对新算法与现有数值效果较好的共轭梯度法进行比对试验,并采用性能图对数值结果进行直观展示,结果表明新算法是有效的.
A spectral three-term conjugate gradient method with sufficient descent property
DOI:10.12387/C2020073
[本文引用: 1]
谱三项共轭梯度法作为共轭梯度法的一种重要推广,在求解大规模无约束优化问题方面具有较好的理论特征与数值效果.本文运用强Wolfe非精确线搜索条件设计产生一个新的谱参数,结合修正Polak-Ribiére-Polyak共轭参数计算公式建立了一个Polak-Ribiére-Polyak型谱三项共轭梯度算法.新算法无论采用何种线搜索条件求步长,每步迭代均满足充分下降条件.在常规假设条件下,采用强Wolfe非精确线搜索条件产生步长,证明了算法的强收敛性.最后,对新算法与现有数值效果较好的共轭梯度法进行比对试验,并采用性能图对数值结果进行直观展示,结果表明新算法是有效的.
Improved Fletcher-Reeves and Dai-Yuan conjugate gradient methods with the strong Wolfe line search
DOI:10.1016/j.cam.2018.09.012 URL [本文引用: 1]
Two sufficient descent three-term conjugate gradient methods for unconstrained optimization problems with applications in compressive sensing
DOI:10.1007/s12190-021-01589-8 [本文引用: 1]
A new family of hybrid three-term conjugate gradient methods with applications in image restoration
DOI:10.1007/s11075-022-01258-2 [本文引用: 1]
一个改进的 WYL 型三项共轭梯度法
An modified three-term WYL conjugate gradient method
强 Wolfe 线搜索下的修正 PRP 和 HS 共轭梯度法
Improved PRP and HS conjugate gradient methods with strong Wolfe line search
一个带重启步的改进 PRP 型谱共轭梯度法
An improved PRP type spectral conjugate gradient method with restart steps
基于非单调线搜索的 HS-DY 形共轭梯度方法及在图像恢复中的应用
A modified HS-DY-type method with nonmonotone line search for image restoration and unconstrained optimization problems
A hybrid conjugate gradient algorithm for nonconvex functions and its applications in image restoration problems
CUTEr and SifDec: A constrained and unconstrained testing environment, revisited
DOI:10.1145/962437.962439
URL
[本文引用: 2]
The initial release of CUTE, a widely used testing environment for optimization software, was described by Bongartz, et al. [1995]. A new version, now known as CUTEr, is presented. Features include reorganisation of the environment to allow simultaneous multi-platform installation, new tools for, and interfaces to, optimization packages, and a considerably simplified and entirely automated installation procedure for unix systems. The environment is fully backward compatible with its predecessor, and offers support for Fortran 90/95 and a general C/C++ Application Programming Interface. The SIF decoder, formerly a part of CUTE, has become a separate tool, easily callable by various packages. It features simple extensions to the SIF test problem format and the generation of files suited to automatic differentiation packages.
Testing unconstrained optimization software
DOI:10.1145/355934.355936 URL [本文引用: 2]
An unconstrained optimization test functions collection
Benchmarking optimization software with performance profiles
DOI:10.1007/s101070100263 URL [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}