


引言
磁共振成像(magnetic resonance imaging,MRI)是一种广泛应用于临床的医学成像方式[1],但存在k-空间数据采集时间过长的缺陷.导致磁共振图像可能因患者的运动和生理运动(如心脏搏动、呼吸活动和胃肠道蠕动)而出现明显的伪影.
压缩感知(compressed sensing,CS)[2]-MRI技术能以低于奈奎斯特采样率的频率对k-空间数据进行欠采样,从而加快成像速度.针对CS-MRI的图像重建方法利用了磁共振图像的稀疏性构建重建模型,通过非线性优化或迭代算法实现图像的重建[3].常用的稀疏变换有全变分(total variation,TV)[4,5]、离散余弦变换[6]、小波变换[7⇓-9]和字典学习[10,11]等.此外,也有学者们融合磁共振图像的稀疏性和低秩性构建CS-MRI重建模型[12,13].但由于一般的稀疏或低秩变换难以精确捕捉组织器官的复杂细节纹理,且非线性优化求解通常涉及多次迭代计算,导致重建时间相对较长,而且不适当的超参数设置将产生过度平滑或不自然的重建图像,因而获得较为满意的CS-MRI重建图像还存在一定困难.
随着深度学习的高速发展,许多基于深度学习的算法已经广泛应用于基于CS-MRI的图像重建中[14⇓-16].目前,深度学习框架下的磁共振图像重建大致采用“端到端映射”(end-to-end mapping)和“基于模型展开”(model-based unrolling)两类方法.“端到端映射”方法直接借助各种不同的深度网络(如结构简单的全卷积神经网络Unet[17]、多尺度残差网络[18]、生成对抗网络[19]等),利用海量数据离线学习“含伪影噪声的欠采样图像”和“参考图像”之间、“欠采样k-空间数据”和“全采样k-空间数据”之间的非线性映射关系,得到参数优化的重建网络.“基于模型展开”的方法则将基于CS-MRI模型的迭代求解展开为深度神经网络计算,如ADMM-Net[20]、ISTA-Net[21]和IFR-Net[22]等,每一个迭代步骤对应于一个神经网络模块,迭代次数对应于网络层数,模型的正则化参数和各种稀疏变换等超参数则成为网络的参数,使得深度网络具有可解释性.这些开创性的工作显示了深度学习在基于CS-MRI的图像重建方面的巨大潜力.
鉴于Unet网络具有使用小样本数据集也能够取得很好的网络模型训练效果的优势,本文以Unet网络为框架,并做出如下改进:(1)将多尺度残差模块(multi-scale residual convolution module,MRCM)引入Unet网络的编码结构中,这样能够更加充分地提取图像的特征信息,并且有利于网络训练时梯度的反向传播;(2)在网络的跳层拼接部分使用卷积块注意模块(convolutional block attention module,CBAM),增强模型对细节纹理的关注并且抑制伪影噪声,提出了一种基于注意力机制的多尺度残差U型网络模型(attention multi-scale residual Unet,AttMRes-Unet).本文提出的网络模型很好地恢复了图像细节,减少了重建图像中的混叠伪影,提高了重建图像的质量.
1 理论部分
1.1 基于CS-MRI的图像重建模型
CS理论通过欠采样k-空间数据缩短数据采集时间,其欠采样模型可以表示为:
其中y∈Cm,为欠采样后的k-空间数据;x∈Rn(m≤n),为待恢复的磁共振图像;FΩ∈Cm×n,代表傅里叶欠采样算子;ε代表噪声.C为复数域,R为实数域,m与n代表不同的维度.
传统的CS-MRI重建方法利用磁共振图像的稀疏性或低秩性等先验信息,通过非线性优化求解如(2)式所示的重建模型,从y中重建出图像x:
其中,\varphi (x)为图像的稀疏性或低秩性表示函数,可利用TV、小波变换或奇异值分解加以实现;{{\lambda }_{1}}为拉格朗日系数,权衡保真项\frac{1}{2}\left\| y-{{F}_{\Omega }}x \right\|_{2}^{2}和稀疏(或低秩)信息间的权重.
端对端的深度学习模型则是通过构建深度神经网络模型建立y与x之间的非线性函数,从而实现图像x的重建.
1.2 基于Unet网络的MRI重建
图1
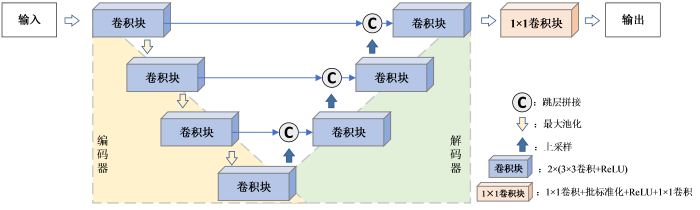
然而对于细节特征丰富的磁共振图像,编码器中的普通卷积不能很好地提取图像的纹理信息,并且浅层特征与深层特征存在着较大的语义差异[27],直接使用跳层拼接可能会使重建图像存在较多的伪影与噪声.因此,本文在Unet网络的架构基础上进行了改进,以便提升网络重建磁共振图像的性能.
1.3 基于注意力机制的多尺度残差Unet网络
本文提出的基于AttMRes-Unet网络的重建模型如图2所示,对数据集中欠采样的k-空间数据进行零填充后得到零填充图像,输入至AttMRes-Unet网络得到相应的重建图像.在编码器部分,引入残差机制,在实现深度提取特征的同时避免网络退化和梯度消失;并引入多尺度卷积的策略,将残差学习由单一路径卷积扩展成多路径多尺度卷积,增加网络宽度,丰富网络的特征提取能力,从而构建出MRCM;在解码器部分,为了能更好地恢复图像的纹理细节,在跳层拼接部分引入CBAM注意力模块,对编码器得到的各层次特征依据其重要性实现不同程度的加权,加强网络模型对图像细节特征的学习,提高重建图像的质量.如图2中所示,在编码器部分包含4个MRCM,在跳层拼接部分采用了3个CBAM.输入图像第一次经过MRCM运算后通道数从1升至16,之后每经过一次MRCM运算,特征图的通道数加倍,即4个MRCM的输出通道分别为16、32、64、128.与经典Unet网络的最大池化保持一致,使用池化核大小为2×2、步长为2的最大池化操作提取最显著特征并实现特征图大小的减半,从而将特征图由从扁平状转换为小而密的立体图;在解码部分,各层均采用最邻近插值法将特征图大小加倍,并通过3×3的卷积运算使特征图通道数减半,从而实现上采样操作;为避免上采样造成的特征信息损失,将上采样之后的特征图与来自于编码器的CBAM加权后的特征图进行跳层拼接.经过3次上采样操作以后,特征图最终恢复到与输入图像相同的大小.
图2
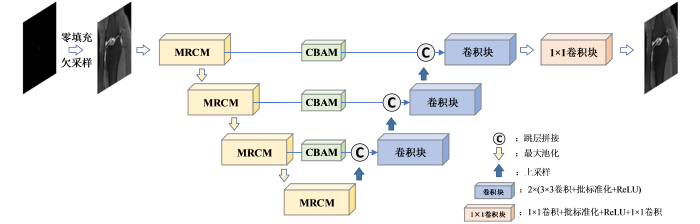
图2
基于AttMRes-Unet网络的重建模型
Fig. 2
Reconstruction model based on AttMRes-Unet network
1.3.1 MRCM
MRCM的结构如图3所示.对于当前模块的输入x,在多尺度卷积分块中,首先通过步长为1,无填充的1×1卷积,然后再通过包含3×3与5×5的两个卷积分支的运算提取出不同感受野的特征,得到尺寸大小相同的特征图.其中,使用3×3卷积学习相应的细节纹理信息,卷积核的步长为1,填充为1;而具有5×5大小感受野的卷积核更适合提取结构特征信息,其步长为1,填充为2.填充方式均选择零填充.为有效地利用不同尺度的特征信息,执行特征通道上的拼接,经批标准化(batch normalization,BN)运算后得到特征输出F(x).在实际的临床应用中,不同人体组织对应的磁共振图像包含的重要特征部分尺寸大小不同,与单尺度的卷积相比,多尺度卷积在不增加网络深度和不占用大量计算资源的同时使用不同尺寸的卷积核提取不同尺度的特征,兼顾了细节与结构特征的提取与学习,更利于图像的重建.
图3
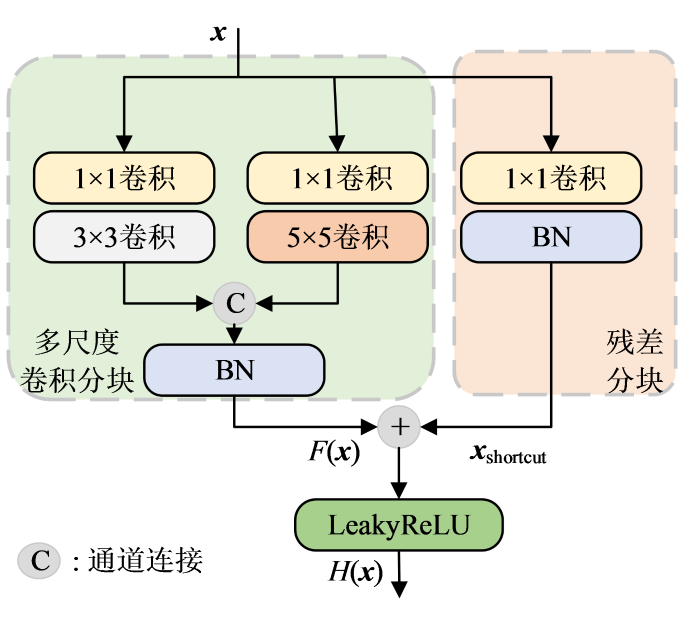
考虑到LeakyReLU函数在特征值为负数时对其赋予很小的斜率,解决了ReLU函数存在的“神经坏死”问题,更有利于网络训练.因此本文在MRCM中使用LeakyReLU函数作为激活函数,其负半轴斜率为0.001,由此得到多尺度残差块的输出H(x),可表示为:
其中,{{x}_{shortcut}}表示输入x经过残差分块后得到的输出.
1.3.2 CBAM
通过解码器得到的浅层特征包含较多图像的细粒度信息(如纹理、边缘等),随着网络层数的加深,解码器提取到的更多是抽象的语义信息而忽略了细节信息.为防止重要细节纹理信息的丢失,本文在跳层拼接部分引入融合通道注意力机制与空间注意力机制的CBAM,以强调细节信息,并去除冗杂的信息,从而使解码器充分利用浅层特征从而提高重建精度.
图4
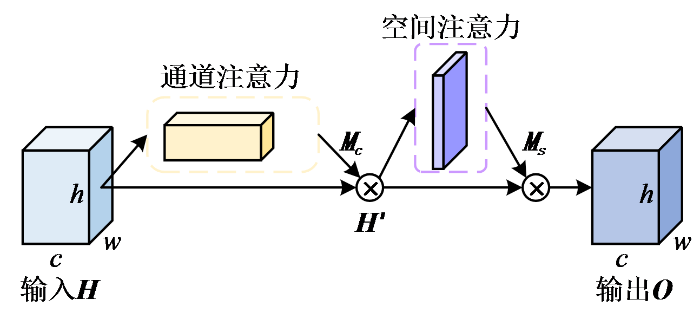
CBAM在通道与空间两个维度上依次生成注意力图,并将相对应的输入与注意特征图加权之后得到输出,表达式如(4)式和(5)式所示:
其中H为输入特征,{{M}_{\text{c}}}为通道模块权重,{{H}^{\prime }}为H与{{M}_{\text{c}}}加权后所得的特征图,{{M}_{\text{s}}}为空间模块权重,O为输出特征,\otimes 表示对应元素依次相乘.
通道注意力机制对特征图的每个通道的重要性进行判断,并对其进行权重分配,权重越大表示该通道的特征越重要,其结构如图5所示.图中,⊕表示按位相加.通道注意力分别通过全局最大池化与全局平均池化对输入特征H的空间维度进行压缩,然后通过具有一层隐藏层的多层感知器(multilayer perceptron,MLP)进行映射,最后再经过Sigmoid函数得到相应的通道权重,表达式为:
图5
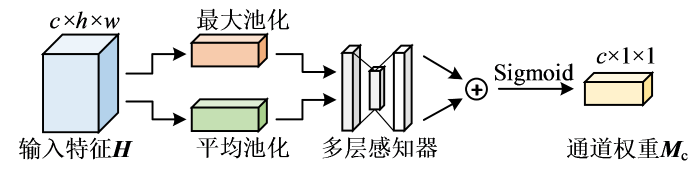
其中,MaxPool(∙)为池化核大小与步长都为2的最大池化,AvgPool(∙)为池化核大小与步长都为2的平均池化,MLP(∙)为多层感知器.
空间注意力机制对特征图中值得注意的位置信息进行关注.如图6所示,空间注意力对输入特征{{H}^{\prime }}先后执行全局平均池化与全局最大池化,然后对通道拼接后的特征图进行7×7的卷积,最后经过Sigmoid函数激活获得归一化的空间权重{{M}_{\text{s}}},表达式为:
图6
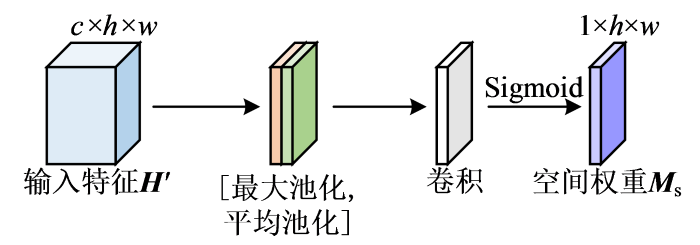
其中,\text{concat}(\cdot )为通道拼接,{{\operatorname{conv}}^{7\times 7}}(\cdot )为7×7卷积.
1.3.3 损失函数
本文使用平均绝对值误差(mean absolute error,MAE)作为损失函数,公式如式(8)所示:
其中,y代表真实的磁共振图像,\hat{y}代表相应的重建图像,n代表每轮训练迭代时的图像数量.
3 实验部分
3.1 数据集
本文使用公开的fastMRI数据集[30] 的单线圈采集的人体膝盖的k-空间数据与对应的全采样图像进行实验.该数据集包含了973个卷作为训练集(共41 877个切片),199个卷作为验证集(共7 135个切片).该数据集原始k-空间数据序列大小为640×372,考虑到实际应用中,笛卡尔采样所需硬件条件较低,采样轨迹容易实现且快速灵活[32],因此本文使用笛卡尔采样(图7),在一定的加速因子下完成k-空间数据的欠采样.加速因子与欠采样率成反比,如当加速因子为4时,欠采样率为1/4=25%.将欠采样的k-空间数据进行零填充并执行傅里叶反变换得到磁共振图像,并以中心裁剪的方式获得统一的320×320像素图像作为网络输入,进行图像重建.
图7

3.2 实验参数设置
本文实验的硬件配置使用NVIDIA GeForce RTX 3060 GPU(12 GB显存)的Windows操作系统,编程语言为Python,所有实验均在Tensorflow框架的keras平台环境下进行.网络选择Adam优化器更新网络参数,其指数衰减率参数默认为β1=0.9与β2=0.999,设置初始学习率为0.001,网络迭代次数为100.
3.3 评价指标
为了定量评价算法的重建效果,本文采用峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structure similarity index measurement,SSIM)作为评价指标.其中,PSNR反映重建图像与全采样图像的一致性,SSIM用于评价重建图像与全采样图像之间的相似程度,计算方式如(9)式和(10)式所示:
其中,x代表全采样图像,\hat{x}代表重建图像,\max (x)代表图像的最大像素值,μ代表图像像素的均值,σ代表图像的像素方差,cov代表两图像素协方差,{{c}_{i}}为常数,{{c}_{1}}={{({{k}_{1}}L)}^{2}},{{c}_{2}}={{({{k}_{2}}L)}^{2}},{{c}_{3}}={{c}_{2}}/2,根据经验常取{{k}_{1}}=0.01,{{k}_{2}}=0.03,L为图像像素值的动态范围.
同时使用网络参数量、网络训练时间与单个切片的重建时间对网络模型进行评价.
4 结果与讨论
4.1 网络模型对比
首先,对各个网络在训练集上的损失值变化进行比较.为了呈现良好的对比效果,以网络损失值的均方根值为纵坐标,迭代次数为横坐标,绘制网络训练的收敛曲线.以加速因子为4为例,5个网络训练的收敛曲线如图8所示,加速因子为2和3时的收敛曲线如图S1和S2所示.可以看出,AttMRes-Unet网络的损失收敛最快,在相同学习率下损失减少的最多,说明网络的拟合效果最好.DC-WCNN网络也能较好的收敛,但是得到的损失值高于AttMRes-Unet网络.其余3个网络的损失值较大,可解释为迭代次数较少,网络对本训练集不能呈现较好的拟合效果.
图8
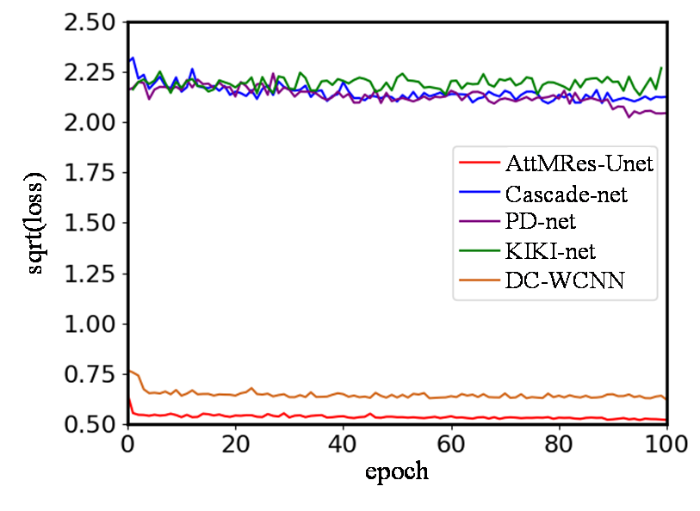
图8
加速因子为4时各个网络在训练集上的收敛曲线
Fig. 8
Convergence curves of each network on the training set when the acceleration factor is 4
当加速因子为2、3、4时,5种网络在验证集上的平均PSNR和SSIM如表1所列.各个模型的网络参数量、训练时间与单个切片的重建时间如表2所示.KIKI-net参数量最大,重建的各项指标均为最低,其原因在于过多的级联导致了网络的过拟合.PD-net的参数量远少于AttMRes-Unet网络,但PD-net需要在k-空间与图像域中交替更新,导致网络训练的时间最长,重建时间超过AttMRes-Unet的23倍.Cascade-net参数量较小,训练时间和重建时间较少,重建质量略优于KIKI-net,但仍低于PD-net、DC-WCNN与AttMRes-Unet. DC-WCNN的网络参数量、训练时间与重建时间均高于AttMRes-Unet,而图像的重建质量均略低于AttMRes-Unet网络.总的来说,AttMRes-Unet在重建质量(在不同加速因子下重建得到的图像都具有更高的PSNR与SSIM)、训练时间与重建时间上相较于其他四个网络具有明显的优势,体现了良好的应用性能.选取不同样本的两张膝盖全采样图像作为参考图像,5种网络模型在加速因子为4下得到的重建图像与相应误差图像如图9所示,加速因子为2、3下得到的重建图像与相应误差图像如图S3和S4所示.相比于其他模型,AttMRes-Unet网络的重建图像细节纹理特征最为清晰,对应差值图像像素分布均匀,轮廓最模糊.
表1 5种网络模型重建图像的平均性能
Table 1
| 网络模型 | PSNR | SSIM | |||||
|---|---|---|---|---|---|---|---|
| ×2 | ×3 | ×4 | ×2 | ×3 | ×4 | ||
| PD-net | 32.5438±1.0981 | 30.9821±1.1230 | 30.6958±1.0923 | 0.7736±0.0812 | 0.6802±0.0800 | 0.6345±0.0813 | |
| Cascade-net | 31.5583±1.1120 | 30.1253±1.096 | 29.8148±1.0220 | 0.7651±0.0795 | 0.6752±0.0820 | 0.6340±0.0760 | |
| KIKI-net | 30.7728±1.4592 | 28.6321±1.3201 | 29.7129±1.5329 | 0.7532±0.0821 | 0.6457±0.0832 | 0.6274±0.0846 | |
| DC-WCNN | 32.8576±1.0786 | 30.9972±1.2356 | 30.7214±1.0643 | 0.7821±0.0831 | 0.6853±0.0801 | 0.6399±0.0842 | |
| AttMRes-Unet | 33.2185±1.2759 | 31.7255±1.1794 | 30.9175±1.2376 | 0.7862±0.0862 | 0.6972±0.0859 | 0.6497±0.0865 | |
表2 5种网络模型的网络参数、训练时间与重建时间对比
Table 2
| 网络模型 | 参数量 | 训练时间/s | 重建时间/ms |
|---|---|---|---|
| PD-net | 318280 | 9024 | 487.5 |
| Cascade-net | 424570 | 3597 | 70.1 |
| KIKI-net | 890504 | 6302 | 186.8 |
| DC-WCNN | 534080 | 4809 | 32.9 |
| AttMRes-Unet | 404714 | 2301 | 21.1 |
图9
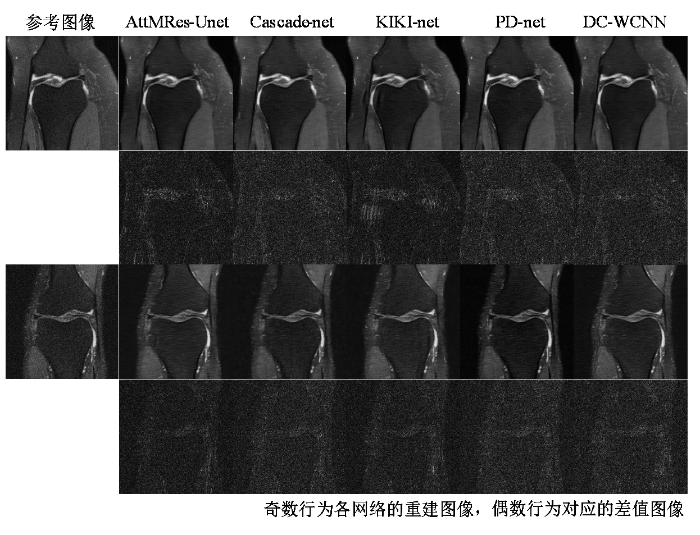
图9
加速因子为4时的对比实验重建效果对比
Fig. 9
Reconstruction results of different networks in comparative experiments when the acceleration factor is 4
4.2 消融实验
为了分析验证本文在Unet网络架构中引入的各个模块对磁共振图像重建质量提升的有效性,分别使用Unet、仅有MRCM模块的MRes-Unet、仅有CBAM块的Att-Unet、包含通道注意力与MRCM模块的CAMRes-Unet、包含空间注意力与MRCM模块的SAMRes-Unet,与本文所提出的AttMRes-Unet网络进行消融实验.加速因子为4时,6个网络在训练集上的收敛曲线如图10所示;加速因子为2、3时,6个网络在训练集上的收敛曲线如图S5、S6所示.其中,AttMRes-Unet网络的损失曲线收敛最快并稳定下降.
图10
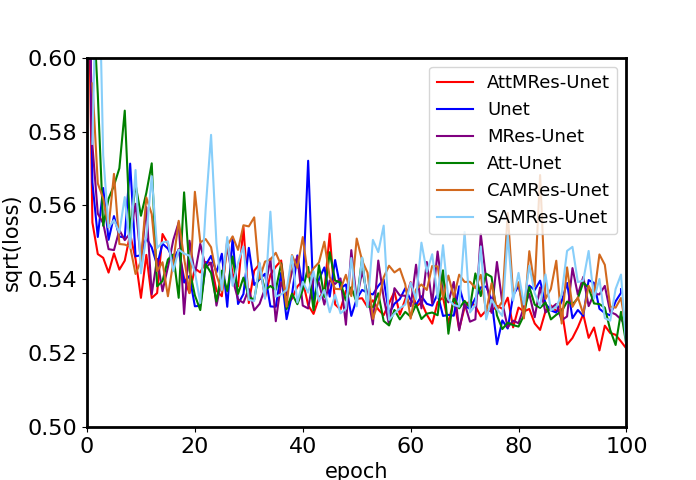
图10
加速因子为4时消融实验收敛曲线
Fig. 10
Convergence curves of ablation experiments when the acceleration factor is 4
表3列出了不同加速因子下各种网络的平均性能,从表中看出,Att-Unet、MRes-Unet、CAMRes-Unet、SAMRes-Unet与AttMRes-Unet的大部分指标均高于Unet.在MRes-Unet网络的基础上再单独增加通道注意力或空间注意力机制均提升了重建图像的质量.在所有网络中,AttMRes-Unet网络重建图像具有最高的PSNR与SSIM.由此可以得出,在Unet基础网络中增加MRCM模块与CBAM块都能有效地提高重建精度.加速因子为4时,各个网络对两个不同样本的膝盖图像的重建可视化效果如图11所示,加速因子为2、3时,各个网络对两个不同样本的膝盖图像的重建可视化效果如图S7、S8所示.AttMRes-Unet网络的重建图像视觉效果更加清晰,细节方面恢复的更好,对应的差值图中轮廓最模糊,与参考图像的差异最小.
表3 消融实验网络模型的平均性能
Table 3
| 网络模型 | PSNR | SSIM | |||||
|---|---|---|---|---|---|---|---|
| ×2 | ×3 | ×4 | ×2 | ×3 | ×4 | ||
| Unet | 32.5193±1.0901 | 31.3347±1.0899 | 30.8267±1.0921 | 0.7771±0.0761 | 0.6829±0.0770 | 0.6475±0.0769 | |
| Att-Unet | 32.9367±1.1096 | 31.5930±1.2019 | 30.9052±1.1099 | 0.7777±0.0799 | 0.6887±0.0811 | 0.6485±0.0787 | |
| MRes-Unet | 33.0847±0.9998 | 31.6665±1.0621 | 30.9085±1.2260 | 0.7849±0.0814 | 0.6959±0.0816 | 0.6445±0.0813 | |
| SAMRes-Unet | 33.1018±1.3921 | 31.6770±1.2998 | 30.9095±1.2975 | 0.7852±0.0824 | 0.6953±0.0827 | 0.6466±0.0825 | |
| CAMRes-Unet | 33.1115±1.3001 | 31.6801±1.2645 | 30.9106±1.2301 | 0.7856±0.0831 | 0.6960±0.0829 | 0.6476±0.0833 | |
| AttMRes-Unet | 33.2185±1.2759 | 31.7255±1.1794 | 30.9175±1.2376 | 0.7862±0.0862 | 0.6972±0.0859 | 0.6497±0.0865 | |
图11

图11
加速因子为4时的消融实验重建效果对比
Fig. 11
Reconstruction results of different networks in ablation experiments when the acceleration factor is 4
各个网络的网络参数量、训练时间与重建时间如表4所列,相较于Unet,Att-Unet中增加的CBAM模块带来了网络参数的少量增长,因此网络的训练时间与重建时间略长于Unet;而MRes-Unet、SAMRes-Unet、CAMRes-Unet与AttMRes-Unet中MRCM模块的1×1卷积则大量减少了网络参数,因此各个网络的训练时间均少于Unet网络,但重建时间均长于Unet.
表4 消融实验网络模型的参数量、训练时间与重建时间
Table 4
| 网络模型 | 参数量 | 训练时间/s | 重建时间/ms |
|---|---|---|---|
| Unet | 485065 | 2498 | 19.4 |
| Att-Unet | 490730 | 2506 | 20.6 |
| MRes-Unet | 399049 | 2240 | 19.9 |
| SAMRes-Unet | 399058 | 2253 | 20.1 |
| CAMRes-Unet | 404705 | 2289 | 20.2 |
| AttMRes-Unet | 404714 | 2301 | 21.1 |
5 结论
本文提出了一种融合注意力机制的多尺度残差Unet网络的磁共振图像重建算法,该算法以Unet为基础网络架构,在编码部分引入多尺度残差模块代替普通卷积,防止网络梯度消失的同时增强特征提取能力;在跳层拼接部分使用了CBAM块,使得图像的有用信息得到充分的强调,恢复图像细节的同时减少了混叠伪影.实验结果表明,在磁共振图像重建上,AttMRes-Unet网络模型具有不错的性能,重建出的图像细节纹理清晰,并且所消耗的时间远低于其他算法,具有实用性.
利益冲突
无
附件材料(可在《波谱学杂志》官网 http://magres.wipm.ac.cn 浏览该论文网页版获取)
图S1 加速因子为2时各个网络在训练集上的收敛曲线
图S2 加速因子为3时各个网络在训练集上的收敛曲线
图S3 加速因子为2时对比实验重建效果对比
图S4 加速因子为3时对比实验重建效果对比
图S5 加速因子为2时消融实验收敛曲线
图S6 加速因子为3时消融实验收敛曲线
图S7 加速因子为2时消融实验重建效果对比
图S8 加速因子为3时消融实验重建效果对比
参考文献
Accelerating T1ρ dispersion imaging with multiple relaxation signal compensation
[J].
基于多弛豫信号补偿的快速磁共振T1ρ散布成像
[J].
Compressed sensing
[J].DOI:10.1109/TIT.2006.871582 URL [本文引用: 1]
Sparse MRI: the application of compressed sensing for rapid MR imaging
[J].
DOI:10.1002/mrm.21391
PMID:17969013
[本文引用: 1]

The sparsity which is implicit in MR images is exploited to significantly undersample k-space. Some MR images such as angiograms are already sparse in the pixel representation; other, more complicated images have a sparse representation in some transform domain-for example, in terms of spatial finite-differences or their wavelet coefficients. According to the recently developed mathematical theory of compressed-sensing, images with a sparse representation can be recovered from randomly undersampled k-space data, provided an appropriate nonlinear recovery scheme is used. Intuitively, artifacts due to random undersampling add as noise-like interference. In the sparse transform domain the significant coefficients stand out above the interference. A nonlinear thresholding scheme can recover the sparse coefficients, effectively recovering the image itself. In this article, practical incoherent undersampling schemes are developed and analyzed by means of their aliasing interference. Incoherence is introduced by pseudo-random variable-density undersampling of phase-encodes. The reconstruction is performed by minimizing the l(1) norm of a transformed image, subject to data fidelity constraints. Examples demonstrate improved spatial resolution and accelerated acquisition for multislice fast spin-echo brain imaging and 3D contrast enhanced angiography.(c) 2007 Wiley-Liss, Inc.
Multiple regularization based MRI reconstruction
[J].DOI:10.1016/j.sigpro.2013.11.001 URL [本文引用: 1]
Compressed sensing MRI using singular value decomposition based sparsity basis
[C]//
Efficient MR image reconstruction for compressed MR imaging
[J].
DOI:10.1016/j.media.2011.06.001
PMID:21742542
[本文引用: 1]
In this paper, we propose an efficient algorithm for MR image reconstruction. The algorithm minimizes a linear combination of three terms corresponding to a least square data fitting, total variation (TV) and L1 norm regularization. This has been shown to be very powerful for the MR image reconstruction. First, we decompose the original problem into L1 and TV norm regularization subproblems respectively. Then, these two subproblems are efficiently solved by existing techniques. Finally, the reconstructed image is obtained from the weighted average of solutions from two subproblems in an iterative framework. We compare the proposed algorithm with previous methods in term of the reconstruction accuracy and computation complexity. Numerous experiments demonstrate the superior performance of the proposed algorithm for compressed MR image reconstruction.Copyright © 2011 Elsevier B.V. All rights reserved.
An efficient algorithm for compressed MR imaging using total variation and wavelets
[C]//
A novel low-rank model for MRI using theredundant wavelet tight frame
[J].
MR image reconstruction from highly undersampled k-space data by dictionary learning
[J].DOI:10.1109/TMI.2010.2090538 URL [本文引用: 1]
Enhancing MR image reconstruction using block dictionary learning
[J].
DOI:10.1109/ACCESS.2019.2949917
[本文引用: 1]
While representing a class of signals in term of sparsifying transform, it is better to use a adapted learned dictionary instead of using a predefined dictionary as proposed in the recent literature. With this improved method, one can represent the sparsest representation for the given set of signals. In order to ease the approximation, atoms of the learned dictionary can further be grouped together to make blocks inside the dictionary that act as a union of small number of subspaces. The block structure of a dictionary can be learned by exploiting the latent structure of the desired signals. Such type of block dictionary leads to block sparse representation of the given signals which can be good for reconstruction of the medical images. In this article, we suggest a framework for MRI reconstruction based upon block sparsifying transform (dictionary). Our technique develops automatic detection of underlying block structure of MR images given maximum block sizes. This is done by iteratively alternating between updating the block structure of the sparsifying transform (dictionary) and block-sparse representation of the MR images. Empirically it is shown that blocksparse representation performs better for recovery of the given MR image with minimum errors.
Combined sparsifying transforms for compressed sensing MRI
[J].DOI:10.1049/el.2010.1845 URL [本文引用: 1]
Second order total generalized variation (tgv) for MRI
[J].
DOI:10.1002/mrm.22595
PMID:21264937
[本文引用: 1]
Total variation was recently introduced in many different magnetic resonance imaging applications. The assumption of total variation is that images consist of areas, which are piecewise constant. However, in many practical magnetic resonance imaging situations, this assumption is not valid due to the inhomogeneities of the exciting B1 field and the receive coils. This work introduces the new concept of total generalized variation for magnetic resonance imaging, a new mathematical framework, which is a generalization of the total variation theory and which eliminates these restrictions. Two important applications are considered in this article, image denoising and image reconstruction from undersampled radial data sets with multiple coils. Apart from simulations, experimental results from in vivo measurements are presented where total generalized variation yielded improved image quality over conventional total variation in all cases.Copyright © 2010 Wiley-Liss, Inc.
Compressed sensing MRI by integrating deep denoiser and weighted schatten P-norm minimization
[J].DOI:10.1109/LSP.2021.3122338 URL [本文引用: 1]
Accelerating CS-MRI reconstruction with fine-tuning wasserstein generative adversarial network
[J].DOI:10.1109/Access.6287639 URL [本文引用: 1]
A modified generative adversarial network using spatial and channel-wise attention for CS-MRI reconstruction
[J].DOI:10.1109/ACCESS.2021.3086839 URL [本文引用: 1]
U-net: convolutional networks for biomedical image segmentation
[C]//
A compressed sensing algorithm based on multi-scale residual reconstruction network
[J].
基于多尺度残差网络的压缩感知重构算法
[J].
Super-resolution reconstruction of MRI based on DNGAN
[J].
基于DNGAN的磁共振图像超分辨率重建算法
[J].
Plug-and-Play ADMM for image restoration: fixed-point convergence and applications
[J].
ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing
[C]//
IFR-Net: Iterative feature refinement network for compressed sensing MRI
[J].
EMED-UNet: An efficient multi-encoder-decoder based UNet for chest X-ray segmentation
[C]//
CRF-EfficientUNet: An improved UNet framework for polyp segmentation in colonoscopy images with combined asymmetric loss function and CRF-RNN layer
[J].DOI:10.1109/ACCESS.2021.3129480 URL [本文引用: 1]
Benchmarking MRI reconstruction neural networks on large public datasets
[J].
DOI:10.3390/app10051816
URL
[本文引用: 1]
Deep learning is starting to offer promising results for reconstruction in Magnetic Resonance Imaging (MRI). A lot of networks are being developed, but the comparisons remain hard because the frameworks used are not the same among studies, the networks are not properly re-trained, and the datasets used are not the same among comparisons. The recent release of a public dataset, fastMRI, consisting of raw k-space data, encouraged us to write a consistent benchmark of several deep neural networks for MR image reconstruction. This paper shows the results obtained for this benchmark, allowing to compare the networks, and links the open source implementation of all these networks in Keras. The main finding of this benchmark is that it is beneficial to perform more iterations between the image and the measurement spaces compared to having a deeper per-space network.
Dual-encoder-U-net for fast MRI reconstruction
[C]//
UNet++: Redesigning skip connections to exploit multiscale features in image segmentation
[J].DOI:10.1109/TMI.42 URL [本文引用: 1]
Deep residual learning for image recognition
[C]//
fastMRI: An open dataset and benchmarks for accelerated MRI
[J].
3D Dynamic MRI with Homotopic l0 Minimization Reconstruction
[J].
基于同伦l0范数最小化重建的三维动态磁共振成像
[J].
Model learning: Primal dual networks for fastMR imaging
[C]//
A deep cascade of convolutional neural networks for MR image reconstruction
[C]//
KIKI-net: cross-domain convolutional neural networks for reconstructing undersampled magnetic resonance images
[J].
DOI:10.1002/mrm.27201
PMID:29624729
[本文引用: 1]
To demonstrate accurate MR image reconstruction from undersampled k-space data using cross-domain convolutional neural networks (CNNs) METHODS: Cross-domain CNNs consist of 3 components: (1) a deep CNN operating on the k-space (KCNN), (2) a deep CNN operating on an image domain (ICNN), and (3) an interleaved data consistency operations. These components are alternately applied, and each CNN is trained to minimize the loss between the reconstructed and corresponding fully sampled k-spaces. The final reconstructed image is obtained by forward-propagating the undersampled k-space data through the entire network.Performances of K-net (KCNN with inverse Fourier transform), I-net (ICNN with interleaved data consistency), and various combinations of the 2 different networks were tested. The test results indicated that K-net and I-net have different advantages/disadvantages in terms of tissue-structure restoration. Consequently, the combination of K-net and I-net is superior to single-domain CNNs. Three MR data sets, the T fluid-attenuated inversion recovery (T FLAIR) set from the Alzheimer's Disease Neuroimaging Initiative and 2 data sets acquired at our local institute (T FLAIR and T weighted), were used to evaluate the performance of 7 conventional reconstruction algorithms and the proposed cross-domain CNNs, which hereafter is referred to as KIKI-net. KIKI-net outperforms conventional algorithms with mean improvements of 2.29 dB in peak SNR and 0.031 in structure similarity.KIKI-net exhibits superior performance over state-of-the-art conventional algorithms in terms of restoring tissue structures and removing aliasing artifacts. The results demonstrate that KIKI-net is applicable up to a reduction factor of 3 to 4 based on variable-density Cartesian undersampling.© 2018 International Society for Magnetic Resonance in Medicine.
DC-WCNN: A deep cascade of wavelet based convolutional neural networks for MR image reconstruction
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}