1 引言
网络数据是指用有向图或者无向图作为一种通用语言的数据, 在生活中也很普遍, 例如新冠病毒传播网络、基因网络、金融网络、交通网络、通话网络等. 对于网络数据的分析, 过去的研究主要是集中在对于网络结构的分析上. 对此, 学者们提出了许多模型来描述网络结构, 最初是对空间结构进行描述, 因而对于网络模型的构建是建立在空间模型的基础上. Ord[19 ] 提出了空间自回归 (SAR) 模型, 它研究了空间结构对于用户所产生的影响. 基于 SAR 模型, Anselin[1 ] 提出了空间杜宾模型, 该模型考虑了协变量与误差项的相关性, 之后相继提出了空间误差模型与 SAR 组合模型, LeSage 和 Pace[15 ] 从空间数据出发, 给出了更一般的空间自回归模型, 将上述模型都包含其中.
为了研究网络结构对于用户所带来的影响, 基于 SAR 模型, Chen 等[5 ] 提出了网络自回归 (NAR) 模型. 随后, Zhu 等[26 ] 考虑了大规模社交网络中 NAR 模型, 并给出了 NAR 模型的平稳性. 已有的文献大多都假设 NAR 模型中各种节点之间是不存在差别的, 很少对节点的异质性进行考虑. 为了弱化这一假设, Malikov 和 Sun[18 ] 提出一种灵活的半参数 SAR 模型, 允许空间自回归参数在单元间变化, 从而允许变量识别特定社区的空间依赖性. Zhu 和 Pan[25 ] 基于 NAR 模型, 建立了分组 NAR 模型, 将网络个体划分不同的组, 不同组的 NAR 模型具有不同的参数; Chen 等[4 ] 提出了社区 NAR 模型, 基于拥有 N K
但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率.
在实际中, 不止存在双模网络数据, 还存在大量的三模网络数据, 即一个网络中存在三种类型的节点, 同类型节点不直接相连, 不同类型的节点之间才可以直接相连, Everett 和 Borgatti[8 ] 在文中提到过三模数据, 并指出了一个犯罪行为按受害者分类可以构成三模网络数据集. Fan[20 ] 在文中提到了一个三模数据, 即学生-话题- 知识网络, 包括三种数据类型: 学生、讨论话题、知识术语. 此外还存在其他三模数据, 如: 第三方平台中商家、顾客、配送员所构成的网络, 校园评价系统中学生、老师、家长所构成的网络等. 因此, 本文基于 Huang 等[12 ] 所提出的双模 NAR 模型进行拓展, 考虑了三模 NAR 模型.
本文在第 2 节给出了三模网络的定义以及其向量表达形式, 并给出模型的可逆性以及参数可识别性条件, 进而研究了 QMLE 和基于 BLP 的 LSE 两种估计方法以及估计量的大样本性质. 第 3 节主要进行了数值模拟, 首先介绍了三模网络数据的生成方法, 同时考虑了参数、权重矩阵、误差分布的不同设置, 进而考虑了两种估计方法并计算效率, 同时与双模 NAR 模型的结论进行了对比, 第 4 节中利用模型对不同年龄段的电影评分网络际数据进行了拟合. 第 5 节对本文进行了总结, 并进行了展望.
2 大规模三模网络自回归模型
三模网络是指在一个无向网络结构中, 存在三种类型不同的节点, 同种类型的节点之间不存在边, 只有不同类型的节点之间才有边相连从而产生联系, 且不存在自环与多重边. 三模网络的例子很多, 例如, 在第三方外卖平台上, 存在三种类型的节点, 类型 I 的节点表示顾客, 类型 II 的节点表示商家, 类型 III 的节点表示配送员. 一条边存在表示如果三者之间任意两者进行了评论或反馈, 在第三方平台上无论顾客之间、商家之间、配送员之间、个人本身是不能够进行评价的, 因而同种类型的节点是不直接相连的. 因此, 该网络可以看作是一个三模网络. 下面, 我们对三模网络结构进行一些限制与定义:
假设在一个三模网络中, 共有 N n 1 n 2 n 3 N = n 1 + n 2 + n 3 . 为了计算简单, 我们假定:lim c_1 c_2 n_1 n_2 n_3 A_{kl}=(a_{i_ki_l})\in \mathbb{R}^{n_k\times n_l}, {1\leqslant i_k \leqslant n_k} {1\leqslant i_l \leqslant n_l} {1\leqslant k\ne l \leqslant 3} . 若(a_{i_ki_l})=1 i_k i_l (a_{i_ki_l})=0 i_k i_l A=[\textbf{0}_{n_1\times n_1},A_{12},A_{13}; A_{21},\textbf{0}_{n_2\times n_2},A_{23};A_{31},A_{32},\textbf{0}_{n_3\times n_3}]\in \mathbb{R}^{N\times N}.
为了更好地刻画网络中各个节点的相邻程度, 构建权重矩阵. 定义 W_{kl}=(w_{kl,i_ki_l})=(a_{i_ki_l}/d_{i_k}) d_{i_k}=\sum\limits_{m=1}^{N} a_{i_km} k [13 ] 对权重矩阵进行了更加详细的描述与证明. 我们之后的模拟结果也说明了针对权重矩阵的不同生成方式, 模拟表现较好. 首先采用行标准化的方式对邻接矩阵进行标准化, 得到W=[\textbf{0}_{n_1\times n_1},W_{12},W_{13}; W_{21},\textbf{0}_{n_2\times n_2},W_{23};W_{31},W_{32},\textbf{0}_{n_3\times n_3}]\in \mathbb{R}^{N\times N}.
每一个类型的节点 i_1 ( {1\leqslant i_1 \leqslant n_1} ) , i_2 ( {1\leqslant i_2 \leqslant n_2} ) 或 i_3 ( {1\leqslant i_3 \leqslant n_3} ) 分别对应一个响应变量 Y_{1,i_1}, Y_{2,i_2} Y_{3,i_3} Y_1=(Y_{1,1},\cdots,Y_{1,n_1})^T, Y_2=(Y_{2,1},\cdots,Y_{2,n_2})^T Y_3=(Y_{3,1},\cdots,Y_{3,n_3})^T . 为了增强响应变量的解释能力, 我们借助 LeSage 和 Pace[15 ] 中对于不同类型的响应节点引入不同的外生协变量, 分别将类型 I、II 和 III 节点的外生变量定义如下: X_1=(X_{1,1}^T, \cdots,X_{1,n_1}^T)^T\in \mathbb{R}^{n_1\times p_1} X_2=(X_{2,1}^T,\cdots,X_{2,n_2}^T)^T\in \mathbb{R}^{n_2\times p_2} X_3=(X_{3,1}^T,\cdots,X_{3,n_3}^T)^T\in \mathbb{R}^{n_3\times p_3} X_{i,j} Y_{i,j} p_i 14 ,24 ], 我们假定 X_1 X_2 X_3
\begin{matrix}Y_1&=\rho_{12}W_{12}Y_2+\rho_{13}W_{13}Y_3+X_{1}\beta_1+\varepsilon_1,Y_2=\rho_{21}W_{21}Y_1+\rho_{23}W_{23}Y_3+X_{2}\beta_2+\varepsilon_2,\nonumber\\Y_3&=\rho_{31}W_{31}Y_1+\rho_{32}W_{32}Y_2+X_{3}\beta_3+\varepsilon_3,\end{matrix}
(2.1)
其中假定 \varepsilon_1 \varepsilon_2 \varepsilon_3 {\rm Cov}(\varepsilon_1)=\sigma_1^{2}{\bf I}_{n_1} {\rm Cov}(\varepsilon_2)=\sigma_2^{2}{\bf I}_{n_2} {\rm Cov}(\varepsilon_3)=\sigma_3^{2}{\bf I}_{n_3} \textbf{I}_n\in \mathbb{R}^{n\times n}(n=n_1,n_2,n_3) \rho_{kl}({1\leqslant k\ne l \leqslant 3}) \rho_{12} \rho_{13} \rho_{21} \rho_{23} \rho_{31} \rho_{31} [17 ] 和 Cohen-Cole 等[6 ] , \beta_1 \beta_2 \beta_3
2.1 参数空间
观察式(2.1), 发现模型的参数是较多的, 容易产生过度参数化的问题. 因此为了更好地识别模型参数空间, 将三模 NAR 模型写成向量的形式. 定义以下变量
\begin{align*} Y_{N\times 1}=\begin{pmatrix} Y_1 \\ Y_2\\ Y_3 \end{pmatrix}, \beta_{p\times 1}=\begin{pmatrix} \beta_1 \\ \beta_2\\ \beta_3 \end{pmatrix}, \varepsilon_{N\times 1}=\begin{pmatrix} \varepsilon_1 \\ \varepsilon_2\\ \varepsilon_3 \end{pmatrix}, \textbf{X}_{N\times p}=\begin{pmatrix} X_1& \textbf{0}_{n_1\times p_2}& \textbf{0}_{n_1\times p_3}\\ \textbf{0}_{n_2\times p_1}&X_2& \textbf{0}_{n_2\times p_3}\\ \textbf{0}_{n_3\times p_1}& \textbf{0}_{n_3\times p_2}&X_3 \end{pmatrix}, \end{align*}
其中 p=p_1+p_2+p_3
\begin{equation} Y=\begin{pmatrix} \textbf{0}_{n_1\times n_1} & \rho_{12}W_{12} & \rho_{13}W_{13} \\ \rho_{21}W_{21} & \textbf{0}_{n_2\times n_2}& \rho_{23}W_{23}\\\rho_{31}W_{31}& \rho_{32}W_{32}& \textbf{0}_{n_3\times n_3} \end{pmatrix}Y+\textbf{X}\beta+\varepsilon \equiv\textbf{W}_{\rho}Y+\textbf{X}\beta+\varepsilon. \end{equation}
(2.2)
因此得到: Y=(\textbf{I}_{N}-\textbf{W}_{\rho})^{-1}(\textbf{X}\beta+\varepsilon) \textbf{I}_{N}-\textbf{W}_{\rho} Y
引理 2.1 假定 |\rho_{12}|+|\rho_{13}|< 1 |\rho_{21}|+|\rho_{23}|<1 |\rho_{31}|+|\rho_{32}|< 1 \textbf{I}_{N}-\textbf{W}_{\rho}
证 根据 Seber[21 ] , 为了确保 \textbf{I}_{N}-\textbf{W}_{\rho} |\lambda_{1}(\textbf{W}_{\rho})|<1 \lambda_{j}(W) W \in \mathbb{R}^{N \times N} j |\lambda_{1}(W)| \geq |\lambda_{2}(W)| \geq \cdots \geq |\lambda_{N}(W)| . 根据 Gerschgorin 圆盘定理, 若 \textbf{W}_{\rho} \lambda_{1}(W)
|\lambda_1-0| \leqslant |\rho_{12}|n_2'(n_2+n_3)^{-1}+|\rho_{13}|n_3'(n_2+n_3)^{-1}\leqslant|\rho_{12}|+|\rho_{13}|, |\lambda_2-0| \leqslant |\rho_{21}|n_1'(n_1+n_3)^{-1}+|\rho_{23}|n_3'(n_1+n_3)^{-1}\leqslant|\rho_{21}|+|\rho_{23}|,|\lambda_3-0| \leqslant |\rho_{31}|n_1'(n_1+n_2)^{-1}+|\rho_{32}|n_2'(n_1+n_2)^{-1}\leqslant|\rho_{31}|+|\rho_{32}|,
其中, 0 \leqslant n_1'\leqslant n_1 0 \leqslant n_2'\leqslant n_2 0 \leqslant n_3'\leqslant n_3 n_1',n_2',n_3' |\lambda_1| \leqslant|\rho_{12}|+|\rho_{13}|< 1,|\lambda_2| \leqslant|\rho_{21}|+|\rho_{23}|< 1,|\lambda_3| \leqslant|\rho_{31}|+|\rho_{32}|< 1.
在上述条件下, \textbf{I}_{N}-\textbf{W}_{\rho} \Sigma_e=[\sigma_1^2\textbf{I}_{n_1},\textbf{0}_{n_1\times n_2},\textbf{0}_{n_1\times n_3};\textbf{0}_{n_2\times n_1},\sigma_2^2\textbf{I}_{n_2},\textbf{0}_{n_2\times n_3};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},\sigma_3^2\textbf{I}_{n_3}]. Y \Sigma=(\textbf{I}_{N}-\textbf{W}_{\rho})^{-1}\Sigma_e(\textbf{I}_{N}-\textbf{W}_{\rho}^T)^{-1} . 对于三模 NAR 模型(2.1), 基于参数的值, 将上述参数空间分为以下 7 种情况: 6 向关系、\cdots
假定所有交叉影响效应中仅有 2 个为 0, 其余非 0. 例如, 先假定 \rho_{12}= 0 \rho_{13}=0 \rho_{21}\ne0 \rho_{23}\ne0 \rho_{31}\ne0 \rho_{32}\ne0 \rho_{12}\ne 0 \rho_{13}=0 \rho_{21}=0 \rho_{23}\ne0 \rho_{31}\ne0 \rho_{32}\ne0 \rho_{13} \rho_{21} W_{13}Y_{3} \varepsilon_1 W_{21}Y_{1} \varepsilon_2
总之, 三模 NAR 模型可以很好地识别在三模网络中各个节点之间的关系, 并将关系分为了 7 种类别.
2.2 拟极大似然估计与性质
定义 S=\textbf{I}_{N}-\textbf{W}_{\rho} \theta=(\rho_{12},\rho_{13},\rho_{21},\rho_{23},\rho_{31},\rho_{32},\beta^T,\sigma_1^2,\sigma_2^2,\sigma_3^2)^T\in \mathbb{R}^{p+9 } . 参考 Huang 等[12 ] , 拟极大似然函数写为
\begin{matrix} l(\theta)=\ln|S|-\frac{1}{2}\ln|\Sigma_{e}|-\frac{1}{2}(SY-\textbf{X}\beta)^T\Sigma_{e}^{-1}(SY-\textbf{X}\beta). \end{matrix}
(2.3)
那么, \hat{\theta}_M=\arg\max_{\theta}l(\theta) l(\theta)
为了利用 BFGS 算法进行求解, 需要建立对于 l(\theta) S^{-1}=(\mathbb{A}_{ij}),
利用 \frac{\partial |\textbf{A}|}{\partial t}=|\textbf{A}|\rm{tr}(\textbf{A}^{-1}\frac{\partial \textbf{A}}{\partial t}) |S| \rho_{j_1j_2} 1 \leq j_1\neq j_2 \leq 3 {\rm tr}
\begin{align*} \frac{\partial |S|}{\partial \rho_{j_1j_2}}&=-|S|{\rm tr}(\mathbb{A}_{j_2j_1}W_{j_1j_2}), \frac{\partial l(\theta)}{\partial \rho_{j_1j_2}}=-{\rm tr}(\mathbb{A}_{j_2j_1}W_{j_1j_2})+\sigma_{j_1}^{-2}Y_{j_2}^TW_{j_1j_2}^T\varepsilon_{j_1},\\ \frac{\partial l(\theta)}{\partial \beta}&=\textbf{X}^T\Sigma_e^{-1}(SY-\textbf{X}\beta)+2^{-1}\textbf{X}^T\Sigma_e^{-1}(SY-\textbf{X}\beta)+2^{-1}\varepsilon\Sigma_e^{-1}\textbf{X},\\ \frac{\partial l(\theta)}{\partial \sigma_1^2}&=-\frac{n_1(\sigma_1^2)^{n_1-1}(\sigma_2^2)^{n_2}(\sigma_3^2)^{n_3}}{2|\Sigma_e|}+\frac{\varepsilon_1^T\varepsilon_1}{2(\sigma_1^2)^2},\\ \frac{\partial l(\theta)}{\partial \sigma_2^2}&=-\frac{n_2(\sigma_2^2)^{n_2-1}(\sigma_1^2)^{n_1}(\sigma_3^2)^{n_3}}{2|\Sigma_e|}+\frac{\varepsilon_2^T\varepsilon_2}{2(\sigma_2^2)^2},\\ \frac{\partial l(\theta)}{\partial \sigma_3^2}&=-\frac{n_3(\sigma_3^2)^{n_3-1}(\sigma_1^2)^{n_1}(\sigma_2^2)^{n_2}}{2|\Sigma_e|}+\frac{\varepsilon_3^T\varepsilon_3}{2(\sigma_3^2)^2}. \end{align*}
为了建立 QMLE 估计的相合性与渐近正态性, 根据 Huang 等[12 ] 针对双模 NAR 模型计算得到的拟极大似然函数的一阶导数与二阶导数形式, 整理得到了三模 NAR 模型的拟极大似然函数的一阶导数与二阶导数形式, 结果如下
\begin{align*} & \dot{l}_{j_1j_2}^{\rho}(\theta)=Y^T\mathbb{W}_{j_1j_2}^T\Sigma_e^{-1}\varepsilon-{\rm tr}(S^{-1}\mathbb{W}_{j_1j_2})=\widetilde{\varepsilon}^TG_{j_1j_2}^{\rho}\widetilde{\varepsilon}+\widetilde{\varepsilon}^TU_{j_1j_2}^{\rho}-C_{j_1j_2}^{\rho}, \\ & \dot{l}_{\beta}(\theta)=\textbf{X}^T\Sigma_E^T\varepsilon=L^T\widetilde{\varepsilon},\ \dot{l}_{\sigma_k}(\theta)=2^{-1}(-n_k\sigma_k^{-2}+\sigma_k{-4}\varepsilon^T\Lambda_k\varepsilon)=\widetilde{\varepsilon}^TG_{\sigma_k}\widetilde{\varepsilon}+C_{\sigma_k},\\ & \ddot{l}_{j_1j_2}\overset{\text{def}}{=}\frac{\partial^2 l(\theta)}{\partial \rho_{j_1j_2}^2}=-{\rm tr}(G_{j_1j_2}^{\rho2})-Y^T\mathbb{W}_{j_1j_2}^T\Sigma_e^{-1}\mathbb{W}_{j_1j_2}Y,\\ & \ddot{l}_{j_1j_2k_1k_2}\overset{\text{def}}{=}\frac{\partial^2 l(\theta)}{\partial \rho_{j_1j_2}\partial \rho_{k_1k_2}}=-{\rm tr}(G_{j_1j_2}^{\rho}G_{k_1k_2}^{\rho}),\ \ddot{l}_{\beta\beta}\overset{\text{def}}{=}\frac{\partial^2 l(\theta)}{\partial \beta\partial \beta^T}=-L^TL=\textbf{X}\Sigma_e^{-1}\textbf{X},\\ & \ddot{l}_{\sigma_k\sigma_k}\overset{\text{def}}{=}\frac{\partial^2 l(\theta)}{\partial \sigma_k^2}=2^{-1}n_k\sigma_k^{-4}-\sigma_k^{-6}(SY-\textbf{X}\beta)^T\Lambda_k(SY-\textbf{X}\beta),\\ & \ddot{l}_{\beta,j_1j_2}\overset{\text{def}}{=}\frac{\partial^2 l(\theta)}{\partial \beta \partial \rho_{j_1j_2}}=-Y^T\mathbb{W}_{j_1j_2}\Sigma_e^{-1}\textbf{X},\\ & \ddot{l}_{\sigma_k,j_1j_2}\overset{\text{def}}{=}\frac{\partial^2 l(\theta)}{\partial \sigma_k \partial \rho_{j_1j_2}}=-\sigma_k^{-4}Y^T\mathbb{W}_{j_1j_2}\Lambda_k(SY-\textbf{X}\beta), \end{align*}
其中, 1 \leq j_1\neq j_2 \leq 3 1 \leq k_1\neq k_2 \leq 3 C_{\sigma_k}=-2^{-1}n_k\sigma_k^{-2} C_{j_1j_2}^{\rho}=-{\rm tr}(\mathbb{W}_{j_1}{j_2}S^{-1}) \widetilde{\varepsilon}=\Omega_e^{\frac{1}{2}}\varepsilon . 部分符号的表达式见附录 1.
基于大规模网络自回归模型的假设, 为建立 QMLE 的渐近正态性, 需满足
(1.1) 连通性: 将包含类型 I、II 和 III 三种类型节点的 N W \pi=(\pi_i)^T\in \mathbb{R}^N, \pi_i \ge 0, \Sigma_{i}\pi_i=1 \textbf{W}^T\pi=\pi . 进一步假设下列条件存在: \Sigma_{i}^N\pi_i^2=O(N^{-\frac{1}{2}-\delta}), 0 < \delta \leq \frac{1}{2} .
(1.2) 均匀性: 定义对称矩阵 \textbf{W*}=\textbf{W}+\textbf{W}^T \textbf{W*} |\lambda_1(\textbf{W*})| =O(\log N) .
(2) 噪声项: 定义 \widetilde{\varepsilon}=\Omega_e^{\frac{1}{2}}\varepsilon=(\widetilde{\varepsilon}_1, \widetilde{\varepsilon}_2,\cdots, \widetilde{\varepsilon}_N)^T \in \mathbb{R}^N \Omega_e=\Sigma_e^{-1} . 假设 E(\widetilde{\varepsilon_i}^3)=\kappa_3, E(\widetilde{\varepsilon_i}^4)=\kappa_4, c_{\varepsilon_0}=E(\widetilde{\varepsilon_i}^2-1)^4, 1 \leq i \leq N \kappa_3,\kappa_4,c_{\varepsilon_0}
(3) 协变量: 对于任何一个向量 x \in \mathbb{R}^p ||x||=1 \lim\limits_{N \to +\infty}\frac{||\textbf{X}x||^2}{N}=O(1) \textbf{X} x ||x||=(|x_1|^2+|x_2|^2+\cdots +|x_p|^2)^{1/2} .
(4) 弱大数定律: 假定在三模网络中, 当 N \to \infty
\begin{align*} & \frac{{\rm tr}(G_{j_1j_2}^\rho G_{k_1k_2}^\rho)}{N} \to \kappa_{j_1j_2,k_1k_2}^a, \frac{{\rm tr} (G_{j_1j_2}^\rho)^2}{N} \to \kappa_{j_1j_2}^a, \frac{{\rm tr}(G_{j_1j_2}^{\rho} {G_{j_1j_2}^{\rho}}^T)}{N} \to \kappa_{j_1j_2}^b,\\ & \frac{{U_{j_1j_2}^\rho}^T U_{j_1j_2}^\rho}{N} \to \kappa_{j_1j_2}^c,\ \frac{L^TL}{N} \to \kappa_\beta,\ \frac{{U_{j_1j_2}^\rho}^TL}{N} \to \kappa_{\beta,j_1j_2},\ \frac{2{\rm tr}(G_{j_1j_2}^\rho G_{\sigma_k})}{N} \to k_{\rho\sigma,k,j_1j_2},\\ & \frac{(\kappa_4-3){\rm tr}({\rm diag}{(G_{j_1j_2}^\rho)}^2)+2\kappa_3 {{\textbf{1}_N}}^T{\rm diag}({G_{j_1j_2}}^\rho)U_{j_1j_2}}{N} \to \Delta_{\rho,j_1j_2},\\ & \frac{\kappa_3{{\textbf{1}_N}}^T {\rm diag}({G_{j_1j_2}}^\rho)L}{N} \to \Delta_{\rho\beta,j_1j_2},\\ & \frac{(\kappa_4-3){\rm tr}({\rm diag}{(G_{j_1j_2}^\rho)}\Lambda_k)+\kappa_3 {{\textbf{1}_N}}^T\Lambda U_{j_1j_2}}{N} \to \Delta_{\rho\sigma,k,j_1j_2}, \ \frac{\kappa_3{{\textbf{1}_N}}^T\Lambda_k L}{2N\sigma_k^2} \to \Delta_{\beta\sigma,k}. \end{align*}
定理 2.1 假设上述条件 (1)-(4) 均满足, 同时假设参数是可识别的, 那么可得到 QMLE 的渐近正态性, 当 N \to \infty \sqrt{N}(\hat{\theta}_M-\theta) \overset{\text{d}}{\to} N(\textbf{0}_{p+9},(\Sigma_{2}^M)^{-1}\Sigma_{1}^{M}(\Sigma_{2}^M)^{-1}), \overset{\text{d}}{\to} \Sigma_{1}^{M} \Sigma_{2}^{M}
定理 2.1 的证明借鉴了 Huang 等[12 ] 在双模 NAR 模型 QMLE 渐近正态性证明中得到的结论:\sqrt{N}(\hat{\theta}_M-\theta)=\{-\frac{\ddot{l}(\theta^*)}{N}\}^{-1}\{\frac{\dot{l}(\theta)}{\sqrt{N}}\} \theta^* \theta \hat{\theta}_M
-\frac{\ddot{l}(\theta^*)}{N}\overset{p}{\to} \Sigma_{2}^M,\frac{\dot{l}(\theta)}{\sqrt{N}} \overset{d}{\to} N(\textbf{0}_{p+9},\Sigma_{1}^{M}),
其中, \overset{p}{\to}
Huang 等[12 ] 指出了对于计算 |\textbf{I}_N-W_{\rho}| O(N^3) |\textbf{I}_N-W_{\rho}|
2.3 最小二乘估计与性质
采用拟极大似然法进行参数估计的时候, 需要计算 \textbf{I}_{N}-\textbf{W}_{\rho} N [22 ] 所提出的 BLP, Huang[11 ] 提出了一种基于 BLP 的最小二乘估计方法. 定义 \tilde{Y}_i=Y_i-\mu_i \tilde{Y}_{(-i)}=Y_{(-i)}-\mu_{(-i)} \mu_i=E(Y_i) Y_{(-i)}=\{Y_j:j\ne i,1 \leqslant j \leqslant N\} \mu_{(-i)}=E(Y_{(-i)}) . 在给定\tilde{Y}_{(-i)} \tilde{Y}_i \mathcal{N}_1 \mathcal{N}_2 \mathcal{N}_3
引理 2.2 如果 j_1,j_2,j_3 \in \{1,2,3\},i\in N_j,j_1 \neq j_2 \neq j_3 \tilde{Y}_{(-i)} \tilde{Y}_i
该引理的证明见附录 3. 考虑基于 \tilde{Y}_i \gamma=(\rho_{12},\rho_{13},\rho_{21},\rho_{23},\rho_{31},\rho_{32},\beta^T)^T\in \mathbb{R}^{p+6},
\begin{equation}Q(\gamma)=\Sigma_i[\tilde{Y}_i-\mathcal{F}\{\tilde{Y}_{(i)}|\tilde{Y}_{(-i)}\}]^2.\end{equation}
(2.4)
定义 \Omega=S^T\Sigma_{e}^{-1}S m=\{{\rm diag}(\Omega)\}^{-1} Y_c=\{\mathcal{F}\{\tilde{Y}_{(i)}|\tilde{Y}_{(-i)}\},i=1,2,\cdots,N\} {\rm diag}(A) A 12 ]得到的结论, 可以得到:Y_c=-m(\Omega-m^{-1})(Y-u), u=E(Y)=S^{-1}\textbf{X}\beta . 因此, 最小二乘目标函数可以构造为
\begin{equation}Q(\gamma)=\parallel\tilde{Y}-Y_c\parallel^2=\parallel mS^T\Sigma_{e}^{-1}(SY-\textbf{X}\beta)\parallel^2,\end{equation}
(2.5)
其中 \tilde{Y}=\{Y_i-\mu_i,1\leqslant i \leqslant N\} [12 ] 已经给出了基于双模 NAR 形式的(2.4)和(2.5)式的证明, 在三模 NAR 模型中, 形式并未发生改变, 证明思路类似, 此处省略细节. 那么, \hat{\gamma}_M=\arg\min_{\gamma}Q(\gamma)\in \mathbb{R}^{p+ 6 } . Huang[11 ] 所提出的基于 BLP 的最小二乘估计, 在计算的过程中并未涉及到对于大规模矩阵的行列式计算, 其次, 虽然涉及到了矩阵的逆, 即 m \Sigma_e m \Sigma_e Q(\gamma) Q(\gamma)
为了利用 BFGS 算法进行求解, 需要建立对于 Q(\gamma) Q(\gamma)
\begin{align*}Q(\gamma)=\parallel mS^T\Sigma_{e}^{-1}(SY-\textbf{X}\beta)\parallel^2=(mS^T\Sigma_e(SY-\textbf{X}\beta))^T(mS^T\Sigma_e(SY-\textbf{X}\beta))=F^TF,\end{align*}
其中, F=mS^T\Sigma_e(SY-\textbf{X}\beta) Q(\gamma)
\begin{align*} m=\{{\rm diag}(\Omega)\}^{-1} =\begin{pmatrix} m_1 & * & *\\ * & m_2 & *\\ * & * & m_3 \end{pmatrix}, \end{align*}
\begin{align*} & m_1=\{\hbox{diag}\{\sigma_1^{-2}\textbf{I}_{n_1}+\sigma_2^{-2}\rho_{21}^2W_{21}^TW_{21}+\sigma_3^{-2}\rho_{31}^2W_{31}^TW_{31}\}\}^{-1}, \\ & m_2=\{\hbox{diag}\{\sigma_2^{-2}\textbf{I}_{n_1}+\sigma_1^{-2}\rho_{12}^2W_{12}^TW_{12}+\sigma_3^{-2}\rho_{32}^2W_{32}^TW_{32}\}\}^{-1},\\ & m_3=\{\hbox{diag}\{\sigma_3^{-2}\textbf{I}_{n_1}+\sigma_1^{-2}\rho_{13}^2W_{13}^TW_{13}+\sigma_2^{-2}\rho_{23}^2W_{23}^TW_{23}\}\}^{-1}, \end{align*}
因而通过计算可以得到 Q(\gamma)
根据 Huang 等[12 ] 针对双模 NAR 模型整理的 Q(\gamma) 的一阶与二阶导数形式, 整理得到三模 NAR 模型的最小二乘估计的导数形式, 首先定义如下指标:\widetilde{S}=\Sigma_e^{-1}S=\Omega_eS , M_1=m\widetilde{S}^T\Sigma_e^{1/2} , M_{2,j_1j_2}=(\frac{\partial m}{\partial \rho_{j_1j_2}}\widetilde{S}^T+m\frac{\partial \widetilde{S}^T}{\partial \rho_{j_1j_2}}+m\widetilde{S}^T\frac{\partial S}{\partial \rho_{j_1j_2}}S^{-1})\Sigma_e^{1/2} , M_{3,j_1j_2}=m\widetilde{S}^T\frac{\partial S}{\partial \rho_{j_1j_2}}S^{-1} , J_{1,j_1j_2}=M_{3,j_1j_2}\textbf{X}\beta , M_{j_1j_2}=M_1^TM_{2,j_1j_2}, J_{j_1j_2}=M_1^TJ_{1,j_1j_2} , H=-2(m\widetilde{S}^T\textbf{X})^TM_1 .从而可以得到最小二乘估计函数的一阶导数与二阶导数形式
\begin{align*} & \dot{Q}_{j_1j_2}^{\rho}\overset{\text{def}}{=}\frac{\partial Q(\gamma)}{\partial \rho_{j_1j_2}}=2\widetilde{\varepsilon}^TM_{j_1j_2}\widetilde{\varepsilon}+2\widetilde{\varepsilon}^TJ_{j_1j_2},\\ & \dot{Q_{\beta}}\overset{\text{def}}{=}\frac{\partial Q(\gamma)}{\partial \beta}=H\widetilde{\varepsilon},\ \ddot{Q_{\beta}}\overset{\text{def}}{=}\frac{\partial^2 Q(\gamma)}{\partial \beta\partial \beta^T}=2\textbf{X}^T\widetilde{S}m^2\widetilde{S}^T\textbf{X},\\ & \ddot{Q}_{\beta,j_1j_2}^{\rho}\overset{\text{def}}{=}\frac{\partial^2 Q(\gamma)}{\partial \beta\partial \rho_{j_1j_2}} =-2\textbf{X}^T(\frac{\partial \widetilde{S}}{\partial \rho_{j_1j_2}}m^2\widetilde{S}^T+\widetilde{S}m\frac{\partial m}{\partial \rho_{j_1j_2}}\widetilde{S}^T)\Sigma_e^{1/2}\widetilde{\varepsilon}\\ & \hskip 3.5cm -2(m\widetilde{S}^T\textbf{X})^TM_{2,j_1j_2}\widetilde{\varepsilon}-2(m\widetilde{S}^T\textbf{X})^T\\ &J_{1,j_1j_2}, \ddot{Q}_{j_1j_2,k_1k_2}^{\rho}\overset{\text{def}}{=}\frac{\partial^2 Q(\gamma)}{\partial \rho_{j_1j_2}\partial \rho_{k_1k_2}} =2(\widetilde{\varepsilon}^TM_{2,k_1k_2}^T+J_{1,k_1k_2}^T)(M_{2,j_1j_2}\widetilde{\varepsilon}+J_{1,j_1j_2}^T)\\ & \hskip 5.6cm +2F^T\frac{\partial^2 F}{\partial \rho_{j_1j_2}\partial \rho_{k_1k_2}}. \end{align*}
为了建立 LSE 估计的渐近正态性, 首先需要参数的可识别性. 利用 Yang 和 Lee[24 ] SAR 模型参数可识别性的方法计算最小二乘目标函数的期望, 从而建立参数的可识别性.
首先, 定义一些参数真值: \gamma_0=(\rho_{0,12},\rho_{0,13},\rho_{0,21},\rho_{0,23},\rho_{0,31},\rho_{0,32},\beta_0^T)^T \sigma_1^2,\sigma_2^2,\sigma_3^2 . 那么, 真实的误差项协方差矩阵可以用\Sigma_{e0} S_0=\textbf{I}_N-W_{\rho_0},\Sigma_0=S_0^{-1}\Sigma_{\rho_0}(S_0^T)^{-1}, W_{\rho_0} W_{\rho}
定义 \mathbb{Q}(\gamma)=E(Q(\gamma)) [12 ] 得到的关于 Q(\gamma) \mathbb{Q}(\gamma)=||mS^T(\Sigma_e^{-1}\otimes\textbf{I})(SS_0^{-1}(\textbf{I}_p\otimes\textbf{X})\beta_0-(\textbf{I}_p\otimes\textbf{X})\beta||^2+{\rm tr}(m\Omega\Sigma_0\Omega m), \otimes \mathbb{Q}(\gamma)=||m\widetilde{S}^T(SS_0^{-1}\textbf{X}\beta_0-\textbf{X}\beta||^2+{\rm tr}(m\Omega\Sigma_0\Omega m).
根据 White[23 ] 的结论, 上式表明:\liminf\limits_{n \to \infty}\min\limits_{\theta \in \bar{B}_{\epsilon}(\theta_0)}\frac{\mathbb{Q}(\gamma)-\mathbb{Q}(\gamma_0)}{N} > 0, \bar{B}_{\epsilon}(\theta_0) \theta_0 \epsilon
(5) 参数可识别条件: 假定在三模网络中 \lim\limits_{N \to +\infty}N^{-1}(\widetilde{\mathbb{X}}^T\widetilde{\mathbb{X}})
\mathbb{X}_1=\mathbb{W}_{12}S_0^{-1}\textbf{X}\beta_0,\mathbb{X}_2=\mathbb{W}_{13}S_0^{-1}\textbf{X}\beta_0,\mathbb{X}_3=\mathbb{W}_{21}S_0^{-1}\textbf{X}\beta_0,\mathbb{X}_4=\mathbb{W}_{23}S_0^{-1}\textbf{X}\beta_0,\mathbb{X}_5=\mathbb{W}_{31}S_0^{-1}\textbf{X}\beta_0,
\mathbb{X}_6=\mathbb{W}_{32}S_0^{-1}\textbf{X}\beta_0,\mathbb{X}=(\mathbb{X}_1,\mathbb{X}_2,\mathbb{X}_3,\mathbb{X}_4,\mathbb{X}_5,\mathbb{X}_6) \in \mathbb{R}^{N \times 6},\widetilde{\mathbb{X}}=(\mathbb{X},\textbf{X}) \in \mathbb{R}^{N \times (6+p)}.
该假设与 NAR 中常用参数可识别性假设基本一致, 在此不进行证明. 但是观察该假设发现: \widetilde{\mathbb{X}} \beta
引理 2.3 如果条件 (5) 满足, 那么存在 \delta > 0
\underset{{\max\{ |\rho_{12}|+|\rho_{13}|,|\rho_{21}|+|\rho_{23}|,|\rho_{31}|+|\rho_{32}|\} \le 1-\delta} }{\min} {\lambda_{\min}(SS^T)}\geq c,
其中, \lambda_{\min}(*) c
如果参数可识别条件满足, 引理 2.3 表明在参数空间 \{(\rho_{12},\rho_{13},\rho_{21},\rho_{23},\rho_{31},\rho_{32}):\max\{ |\rho_{12}| +|\rho_{13}|,|\rho_{21}|+|\rho_{23}|,|\rho_{31}|+|\rho_{32}|\} \le 1-\delta\} \textbf{I} W W^T W^TW
(6) 弱大数定律: 假定在三模网络中, 当 N \to \infty
\begin{align*} &2N^{-1}(m\widetilde{S}^T\textbf{X})^TJ_{1,j_1j_2} \to \kappa_{\beta,j_1j_2}^{**},\\ & 4N^{-1}[{\rm tr}\{{\rm diag}(M_{j_1j_2}){\rm diag}(M_{k_1k_2})\}(\kappa_4-3)+{\rm tr}(M_{j_1j_2}M_{k_1k_2}^T) +{\rm tr}(M_{j_1j_2}M_{k_1k_2})\\ & +J_{j_1j_2}^TJ_{k_1k_2}+\kappa_3\textbf{1}_N^T{\rm diag}(M_{j_1j_2})J_{k_1k_2}+\kappa_3\textbf{1}_N^T{\rm diag}(M_{k_1k_2})J_{j_1j_2}] \to \kappa_{j_1j_2,k_1k_2}^*,\\ &4N^{-1}(m\widetilde{S}^T\textbf{X})^TM_1M_1^T(m\widetilde{S}^T\textbf{X}) \to \kappa_{\beta}^*, 2N^{-1}\{HJ_{j_1j_2}+\kappa_3H{\rm diag}(M_{j_1j_2})\textbf{1}_N\} \to \kappa_{\beta,j_1j_2}^*,\\ &N^{-1}\{{\rm tr}(M_{2,j_1j_2}^TM_{2,k_1k_2})+J_{1,j_1j_2}^TJ_{1,k_1k_2}\} \to \kappa_{j_1j_2,k_1k_2}^{**}, 2N^{-1}(m\widetilde{S}^T\textbf{X})^T(m\widetilde{S}^T\textbf{X}) \to \kappa_{\beta}^{**}, \end{align*}
其中, \textbf{1}_N N
定理 2.2 假设上述条件 (1)-(3)、(5)-(6) 均满足, 那么可以得到 LSE 估计参数的渐近正态性, 当 N \to \infty \sqrt{N}(\hat{\gamma}_L-\gamma) \overset{d}{\to} N(\textbf{0}_{p+6},(\Sigma_{2}^L)^{-1}\Sigma_{1}^{L}(\Sigma_{2}^L)^{-1}), \Sigma_1^L \Sigma_2^L
定理 2.2 的证明借鉴了 Huang 等[12 ] 在双模 NAR 模型中 LSE 方法渐近正态性证明中得到的结论:\sqrt{N}(\hat{\gamma}-\gamma)=\{-\frac{\ddot{Q}(\gamma)}{N}\}^{-1}\{\frac{\dot{Q}(\gamma)}{\sqrt{N}}\} \theta^* \theta \hat{\theta}_M
-\frac{\ddot{Q}(\gamma)}{N}\overset{p}{\to} \Sigma_{2}^L, \quad \frac{\dot{Q}(\gamma)}{\sqrt{N}} \overset{d}{\to} N(\textbf{0}_{p+6},\Sigma_{1}^{L}).
3 数值模拟
本文模拟所使用的电脑的处理器为 12th Gen Intel(R) Core(TM) i7-12700H 2.30 GHz, 该处理器是基于 x64 的 64 位操作系统.
3.1 生成数据
为了说明三模 NAR 模型在有限样本下的表现, 利用 MATLAB 从多方面进行模型的估计与验证. 在每一次模拟中, 首先需要生成邻接矩阵 A N n_1=\frac{5}{12}N,n_2=\frac{4}{12}N,n_3=\frac{3}{12}N. A_{21}\in \mathbb{R}^{n_2\times n_1}
步骤 1 生成 n_2 E_i(1 \leqslant i\leqslant n_2) [E_i]
步骤 2 对于类型 II 的每一个节点 i(1 \leqslant i\leqslant n_2) d_i=\min([E_i],n_1) d_i
通过上述步骤可以得到 A_{21} A_{31} A_{32} A_{12}=A_{21}^T A_{13}=A_{31}^T A_{23}=A_{32}^T A_{12} A_{13} A_{23} A=(a_{ij})\in \mathbb{R}^{N\times N} . 为了简化计算过程同时减少参数, 假定三种类型的节点拥有相同的外生变量, 即 p_1=p_2=p_3=1 p=3 \textbf{X} \textbf{0}_N \textbf{I}_N
邻接矩阵 给定邻接矩阵 A W . 在行标准化的情形下, 我们定义W_{12} W_{13} W_{21} W_{23} W_{31} W_{32} A 13 ]中的方法, 通过 A A W .
情况 1 \rho_{12}=\rho_{21}=\rho_{31}=\rho_{32}=0.3 \rho_{13}=\rho_{23}=0.2
情况 2 \rho_{12}=\rho_{21}=\rho_{31}=\rho_{32}=0.3 \rho_{13}=0 \rho_{23}=0.2
情况 3 \rho_{21}=\rho_{31}=\rho_{32}=0.3 \rho_{12}=\rho_{13}=0 \rho_{23}=0.2
情况 4 \rho_{31}=\rho_{32}=0.3 \rho_{12}=\rho_{13}=\rho_{21}=0 \rho_{23}=0.2
情况 5 \rho_{31}=0.3 \rho_{12}=\rho_{13}=\rho_{21}=\rho_{32}=0 \rho_{23}=0.2
情况 6 \rho_{12}=\rho_{13}=\rho_{21}=\rho_{31}=\rho_{32}=0 \rho_{23}=0.2
情况 7 \rho_{12}=\rho_{13}=\rho_{21}=\rho_{23}=\rho_{31}=\rho_{32}=0 .
在这 7 种情况下, 为简化计算过程, 我们将外生变量的系数均设置为 \beta=(0.3,0.5,0.7)^T .
噪声分布 我们考虑了不同类型的噪声分布. 首先, 我们考虑了对于同一类型的所有节点的误差有相同的方差. 特别地, 此时又考虑了方差相同时误差项的两种分布情况: (1) 正态分布: 令 \varepsilon_{1,i_{1}}(1\leqslant i_1\leqslant n_1) \varepsilon_{2,i_{2}}(1\leqslant i_2\leqslant n_2) \varepsilon_{3,i_{3}}(1\leqslant i_3\leqslant n_3) N(0,\sigma_1^2) N(0,\sigma_2^2) N(0,\sigma_3^2) \varepsilon_{1,i_{1}}(1\leqslant i_1\leqslant n_1) \varepsilon_{2,i_{2}}(1\leqslant i_2\leqslant n_2) \varepsilon_{3,i_{3}}(1\leqslant i_3\leqslant n_3) \lambda_1 \lambda_2 \lambda_3 1/\lambda_1 1/\lambda_2 1/\lambda_3 .
所有的误差项都经过了中心化处理. 具体考虑两种情形: (1) 同类型节点的误差标准差相同: 假定 \sigma_1^2=0.75 \sigma_2^2=1 \sigma_3^2=1.25 \lambda_1=0.75 \lambda_2=1 \lambda_3=1.25 j_1(1 \leqslant j_1 \leqslant 3) i \varepsilon_{j_1,i} \sigma_{j_1,i}^2(1 \leqslant i \leqslant n_{j_1}) U(0.5,1.5)
3.2 模拟表现
我们考虑了不同大小的网络规模, N=2000,3000,4000 . 对每一次模拟, 设置重复次数为 M=50 m (1\leqslant m\leqslant M) \hat{\rho}^{(m)} m \rho \rho \hat{SE}^{(m)} CI^{(m)} \%
\begin{align*} & \hat{SE}=\frac{\sum\limits_{m}\hat{SE}^{(m)}}{M},\ SE^*=\sqrt{\frac{\sum\limits_{m}(\hat{\rho}^{(m)}-\bar{\rho})^2}{M}},\ \hbox{RMSE}=\sqrt{\frac{\sum\limits_m(\hat{\rho}^{(m)}-\rho)^2}{M}},\\ &CI^{(m)}=(\hat{\rho}^{(m)}-z_{0.975}\hat{SE}^{(m)},\hat{\rho}^{(m)}+z_{0.975}\hat{SE}^{(m)}),\ \hbox{CP}=\frac{1}{M}\sum\limits_mI(\rho\in CI^{(m)}), \end{align*}
其中, z_{\alpha} \alpha I(\cdot)
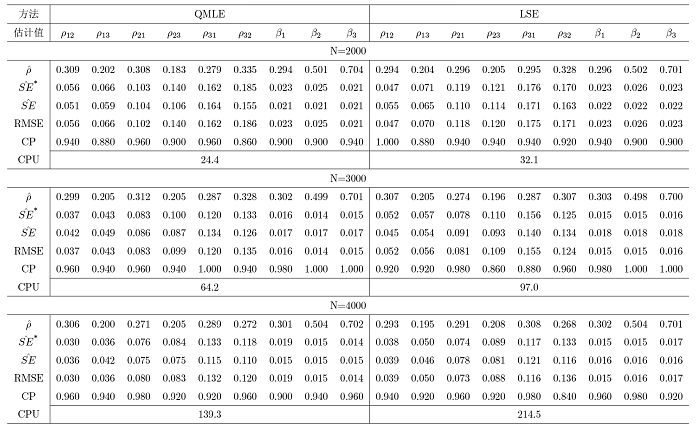
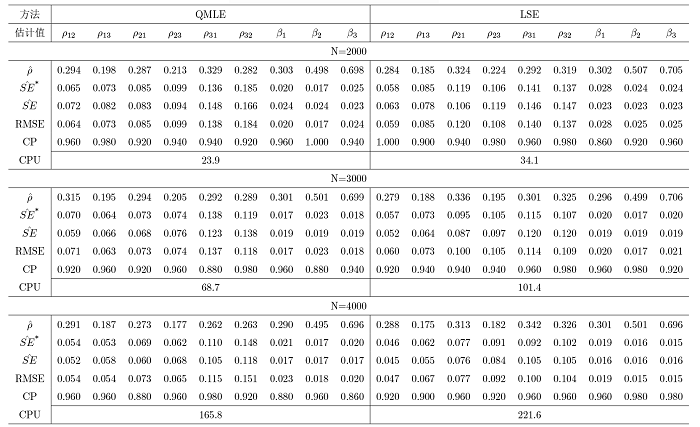
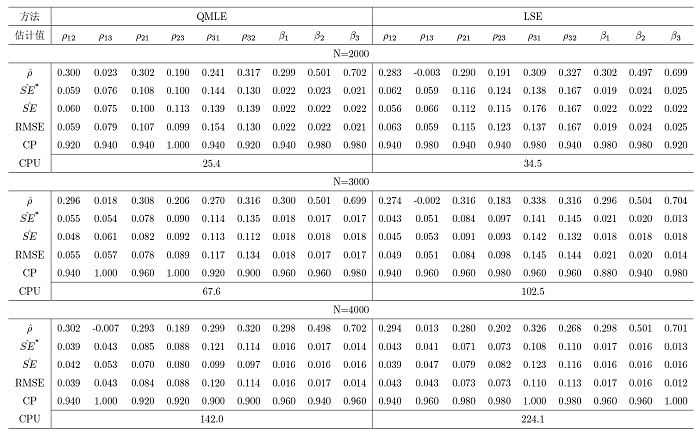
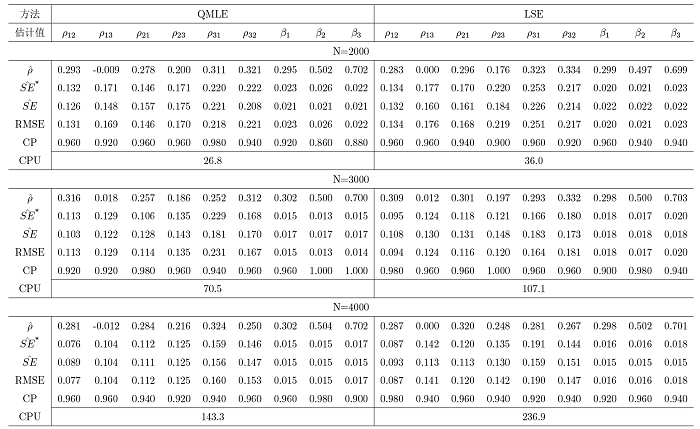
其他参数的 \hat{SE} SE^*
表1 展示了权重矩阵采用行标准化的方式获得, 同类型节点的误差项来自相同方差的正态分布时的 1 种情形; 表2 展示了权重矩阵采用行标准化的方式获得, 同类型节点的误差项来自相同方差的指数分布时的 1 种情形; 表 3 展示了权重矩阵采用行标准化的方式获得, 同类型节点的误差项来自不同方差的正态分布时的 1 种情形; 表 4 展示了权重矩阵采用特征值标准化的方式获得, 同类型节点的误差项来自相同方差的正态分布时的 1 种情形; 对于每种设置下的其余 6 种情况, 本文均进行了模拟验证, 由于篇幅限制, 结果不再列出, 同时对于模拟的结果均进行了记录, 以及验证了每一组实验的所有参数估计结果是否满足模型的可识别性条件, 发现所有实验的参数估计结果均满足模型的可识别性条件, 进而验证了模型可识别性条件的合理性.
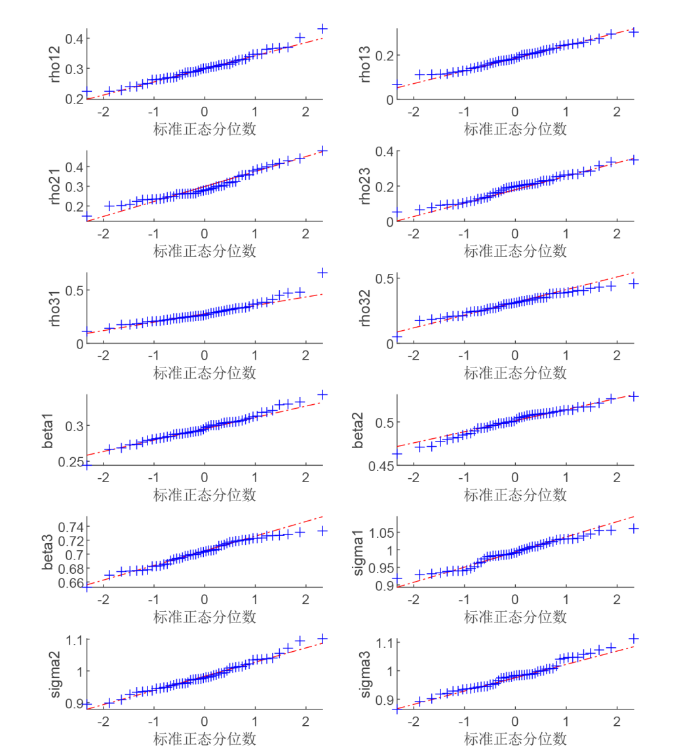
为了验证参数的渐近正态性, 本文绘制了 QQ 图, 由于篇幅的限制, 本文仅展示了表 1 中 N=4000 \theta 图1 所示.
图1
图1
表1 中 N=4000
观察发现, 模拟结果在不同的交叉效应设置下是相似的, 并得到如下结论: (1) 对于所有规模的网络而言, 两种方法的参数估计值与真值都十分接近; (2) 随着网络规模 N \hat{SE}^* \hat{SE}
通过结论表明了真实的标准差可以通过上一章节中推导出的 QMLE 与 LSE 两种方法的理论标准差来进行近似代替, 同时当网络的规模更大时, 估计效果更好, 因为此时可以更好地减少模型中存在的内生性影响.
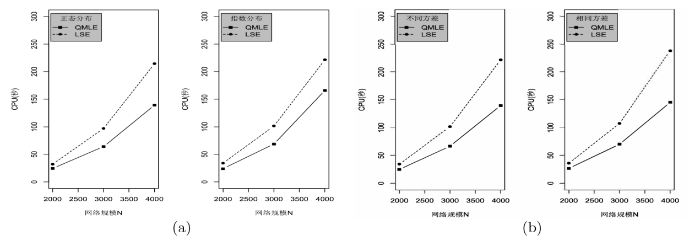
为了比较 QMLE 与 LSE 两种方法的计算效率, 图2 展示了表 1 和表 2 中两种估计方法以及相应理论标准差的平均计算时间. 通过结果, 我们可以得到如下结论: (1) 在三模 NAR 模型中, LSE 方法的计算效率比 QMLE 的计算效率差, 这与两种方法的效率的常见情况一致, 但这与双模网络自回归模型中两种估计方法的结论截然相反, 可能的原因是估计量的计算细节的不同, 比如, 二维 NAR 模型中 QMLE 与 LSE 方法的计算均采用了牛顿法, 而三维 NAR 模型中由于参数过多, QMLE 与 LSE 方法若使用牛顿法会因为 Hessian 非正定而使得牛顿法失效, 所以均采用了拟牛顿法的 BFGS 算法; (2) 随着网络规模 N
图2
图2
(a) 情况 1, 权重矩阵采用行标准化的方式, 同类型节点的误差项来自同一标准差的分布, 考虑了误差项的两种分布——正态分布与指数分布. (b) 情况 1, 权重矩阵采用行标准化的方式, 同类型节点的误差项均来自于不同方差的正态分布; 权重矩阵采用特征值标准化的方式获得, 同类型节点的误差项来自相同方差的正态分布.
由于我们在记录平均计算时间的过程中既考虑了参数的估计过程, 又同时考虑了相应参数理论标准差的计算过程, 使得 QMLE 的计算效率有了一定的优势, 这也是由于采用 LSE 方法计算参数与理论标准差的过程中, 虽然避免了计算大型矩阵行列式的值, 但涉及到的矩阵形式、矩阵的逆等的形式更为复杂, 从而产生了这样的结果.
4 实例分析
在本节, 通过考虑不同年龄段的电影评分数据, 我们讨论了三模 NAR 模型的应用. 我们对数据集构建了网络结构, 利用三模 NAR 模型的两种估计方法 QMLE 和 LSE 进行了参数估计, 并记录了两种方法的计算时间.
为了表明三模 NAR 模型的可应用性, 我们将此模型应用于 CSDN 公开的电影评分数据, 通过 2619 名 30 岁以下的观影者与 3421 名 30 岁以上的观影者对 90 年代 3883 部国外电影的评分数据构建了网络.
在这个数据中, 30 岁以下的观影者是类型 I 的节点, 30 岁以上的观影者为类型 II 的节点, 被评分的电影是类型 III 的节点, Y_1 Y_2 Y_3 N
n_1=2619, n_2=3421, n_3=3883, N=n_1+n_2+n_3=9923.
对于原始网络数据, 我们首先去除了多重边, 进而通过两种类型的观影者与电影间的评分关系构建邻接矩阵为 A=(a_{ij}) k a_{kj}=1 j k a_{kj}=0 . 在三模 NAR 模型中, 要求网络尽可能稀疏, 本网络中, 网络密度为
N^{-1}(N-1)^{-1}\sum\limits_{i=1}^{N}\sum\limits_{j=1}^{N} a_{ij}=0.0188\%,
在此网络中, 由于不同年龄段的观影者之间不进行评分, 即不同年龄段的节点之间不存在边, 因而在该网络模型中邻接矩阵 A_{12} A_{21} W_{12} W_{21}
Y_1=\rho_{13}W_{13}Y_3+X_{1}\beta_1+\varepsilon_1,Y_2=\rho_{23}W_{23}Y_3+X_{2}\beta_2+\varepsilon_2,Y_3=\rho_{31}W_{31}Y_1+\rho_{32}W_{32}Y_2+\varepsilon_3,
其中, (X_1,X_2,0)^T X_1 X_2 X_1=1 X_1=2 .
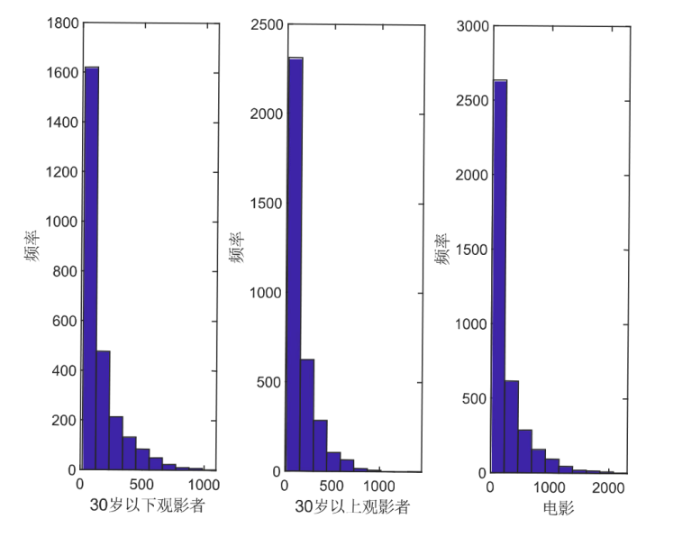
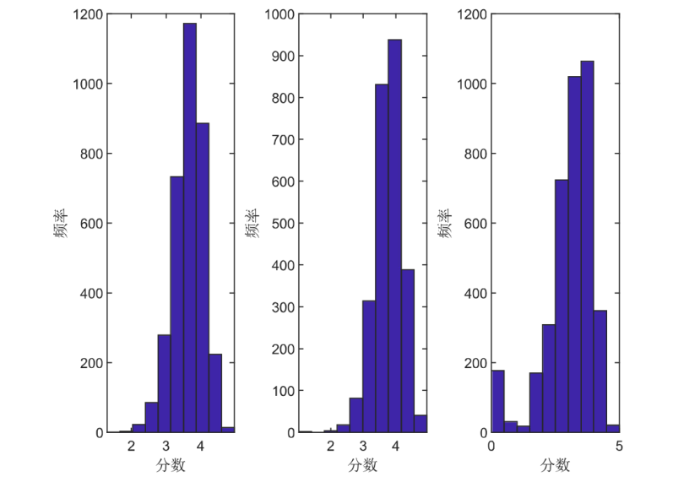
为了进一步研究该网络的结构, 我们计算了每一个类型节点的度, 即每一个类型观影者评价电影的数量或电影受到评分的数量. 例如, 类型 I 节点的度可以定义为每一位 30 岁以下的观影者所评价电影的数量, 类型 II 节点的度可以类似定义为每一位 30 岁以上的观影者所评价电影的数量, 类型 III 节点的度可以定义为每一部电影所收到的评分的数量. 三种类型节点的度的直方图通过图3 展示. 观察图3 , 发现大多数节点的度都在 1000 以下, 同时 30 岁以上观影者对于 90 年代电影的评分数目相较于 30 岁以下观影者对于电影的评分数目而言更为活跃. 为了更直观展现三种类型节点的分数水平, 绘制了直方图, 如图4 所示.观察图4 , 发现 30 岁以上观影者给电影的分数比 30 岁以下观影者给电影的分数较高, 说明了 30 岁以下观影者对于影片的要求较高; 而电影的分数大多集中在 4 分左右, 也不乏存在一些吸引力不高的电影使得观影者对此评分为 0.
图3
图3
(左图) 30 岁以下观影者在评价网络中的度; (中图) 30 岁以上观影者在评价网络中的度; (右图) 电影在评价网络中的度
图4
图4
(左图) 30 岁以下观影者的评分; (中图) 30 岁以上观影者的评分; (右图) 电影的评分
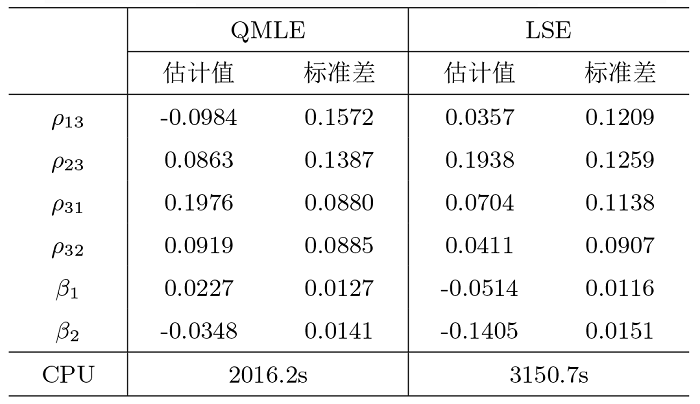
最后, 我们分别对该三模 NAR 模型用 QMLE 和 LSE 两种方法进行了拟合, 并记录了参数估计的时间, 如表5 所示. 结果显示了对三模 NAR 模型参数估计时利用 QMLE 与 LSE 两种方法的可靠性, 电影评分数据明显受到了性别的影响, 通过 CPU 的记录, 进一步验证在三模 NAR 模型中 QMLE 方法的估计效率优于 LSE 估计方法.
5 结论与展望
本文在双模 NAR 模型的基础上, 进一步研究了三模 NAR 模型. 该模型考虑了在一个十分稀疏的社交网络中, 存在三种类型节点的情况下, 对于自回归模型参数估计及其性能评估的影响. 在本文中, 我们首先介绍了一些网络、自回归模型等相关知识, 进而提出了三模 NAR 模型的定义及表示形式, 然后证明了其可逆性及参数可识别性. 在参数估计方面, 采用了 QMLE 与基于 BLP 的 LSE 两种估计方法, 并给出了估计量的渐近正态性与相合性, 数值结果表明两种估计方法的估计效果都比较好, 但 QMLE 的运算时间更快一些, 其运算时间的结论与两模 NAR 模型中的结论形成了差异.
本文中, 考虑的三模网络要求同类型的节点之间不能够相连, 但在实际网络中, 三种类型节点构成的网络也会允许同类型的节点之间产生联系, 我们可以对三模 NAR 模型进行泛化, 引入同类型节点的影响效应, 从而使得模型更加适应实际数据. 同时, 在研究三模 NAR 模型的过程中, 本文假设了三种类型的节点数目 n_1 n_2 n_3 n_1 n_2 n_3
附录
附录1 2.2 节的一些符号
\begin{align*} & \mathbb{A}=\begin{pmatrix} \textbf{I}_{n_1} & -\rho_{12}W_{12}\\ -\rho_{21}W_{21} & \textbf{I}_{n_2} \end{pmatrix}, \mathbb{A}^{-1}= \begin{pmatrix} a_{11} & a_{12}\\ a_{21} & a_{22} \end{pmatrix},\\ &a_{22}=(\textbf{I}_{n_2}-\rho_{21}\rho_{12}W_{21}W_{12})^{-1}, a_{11}=\textbf{I}_{n_1}+\rho_{12}\rho_{21}W_{12}a_{22}W_{21},\\ &a_{12}=\rho_{12}W_{12}a_{22}, a_{21}=\rho_{21}a_{22}W_{21},\\ & \mathbb{A}_{33}=(\textbf{I}_{n_3}\!-\!\rho_{31}\rho_{13}W_{31}a_{11}W_{13} \!-\!\rho_{13}\rho_{32}W_{32}a_{21}W_{13}\!-\!\rho_{23}\rho_{31}W_{31}a_{12}W_{23} \!-\!\rho_{23}\rho_{32}W_{32}a_{22}W_{23})^{-1},\\ & \mathbb{A}_{11}=a_{11}+(\rho_{13}a_{11}W_{13}+\rho_{23}a_{12}W_{23})\mathbb{A}_{33}(\rho_{31}W_{31}a_{11}+\rho_{32}W_{32}a_{21}),\\ & \mathbb{A}_{12}=a_{12}+(\rho_{13}a_{11}W_{13}+\rho_{23}a_{12}W_{23})\mathbb{A}_{33}(\rho_{31}W_{31}a_{12}+\rho_{32}W_{32}a_{22}),\\ & \mathbb{A}_{13}=(\rho_{13}a_{11}W_{13}+\rho_{23}a_{12}W_{23})A_{33}, \mathbb{A}_{32}=A_{33}(\rho_{31}W_{31}a_{12}+\rho_{32}W_{23}a_{22}),\\ & \mathbb{A}_{21}=a_{21}+(\rho_{13}a_{21}W_{13}+\rho_{23}a_{22}W_{23})\mathbb{A}_{33}(\rho_{31}W_{31}a_{11}+\rho_{32}W_{32}a_{21}),\\ & \mathbb{A}_{22}=a_{22}+(\rho_{13}a_{21}W_{13}+\rho_{23}a_{22}W_{23})\mathbb{A}_{33}(\rho_{31}W_{31}a_{12}+\rho_{32}W_{32}a_{22}),\\ & \mathbb{A}_{23}=(\rho_{13}a_{21}W_{13}+\rho_{23}a_{22}W_{23})A_{33}, \mathbb{A}_{31}=A_{33}(\rho_{31}W_{31}a_{11}+\rho_{32}W_{23}a_{21}).\\ & \textbf{W}=[\textbf{0}_{n_1\times n_1},W_{12},W_{13};W_{21},\textbf{0}_{n_2\times n_2},W_{23};W_{31},W_{32},\textbf{0}_{n_3\times n_3}],\\ & \mathbb{W}_{12}=[\textbf{0}_{n_1\times n_1},W_{12},\textbf{0}_{n_1\times n_3};\textbf{0}_{n_2\times n_1},\textbf{0}_{n_2\times n_2},\textbf{0}_{n_2\times n_3};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},\textbf{0}_{n_3\times n_3}],\\ & \mathbb{W}_{13}=[\textbf{0}_{n_1\times n_1},\textbf{0}_{n_1\times n_2},W_{13};\textbf{0}_{n_2\times n_1},\textbf{0}_{n_2\times n_2},\textbf{0}_{n_2\times n_3};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},\textbf{0}_{n_3\times n_3}],\\ & \mathbb{W}_{21}=[\textbf{0}_{n_1\times n_1},\textbf{0}_{n_1\times n_2},\textbf{0}_{n_1\times n_3};W_{21},\textbf{0}_{n_2\times n_2},\textbf{0}_{n_2\times n_3};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},\textbf{0}_{n_3\times n_3}],\\ & \mathbb{W}_{23}=[\textbf{0}_{n_1\times n_1},\textbf{0}_{n_1\times n_2},\textbf{0}_{n_1\times n_3};\textbf{0}_{n_2\times n_1},\textbf{0}_{n_2\times n_2},W_{23};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},\textbf{0}_{n_3\times n_3}],\\ & \mathbb{W}_{31}=[\textbf{0}_{n_1\times n_1},\textbf{0}_{n_1\times n_2},\textbf{0}_{n_1\times n_3};\textbf{0}_{n_2\times n_1},\textbf{0}_{n_2\times n_2},\textbf{0}_{n_2\times n_3};W_{31},\textbf{0}_{n_3\times n_2},\textbf{0}_{n_3\times n_3}],\\ & \mathbb{W}_{32}=[\textbf{0}_{n_1\times n_1},\textbf{0}_{n_1\times n_2},\textbf{0}_{n_1\times n_3};\textbf{0}_{n_2\times n_1},\textbf{0}_{n_2\times n_2},\textbf{0}_{n_2\times n_3};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},W_{32}],\\ & \Lambda_1=[I_{n_1},\textbf{0}_{n_1\times n_2},\textbf{0}_{n_1\times n_3};\textbf{0}_{n_2\times n_1},\textbf{0}_{n_2\times n_2},\textbf{0}_{n_2\times n_3};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},\textbf{0}_{n_3\times n_3}],\\ & \Lambda_2=[\textbf{0}_{n_1\times n_1},\textbf{0}_{n_1\times n_2},\textbf{0}_{n_1\times n_3};\textbf{0}_{n_2\times n_1},I_{n_2},\textbf{0}_{n_2\times n_3};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},\textbf{0}_{n_3\times n_3}],\\ & \Lambda_3=[\textbf{0}_{n_1\times n_1},\textbf{0}_{n_1\times n_2},\textbf{0}_{n_1\times n_3};\textbf{0}_{n_2\times n_1},\textbf{0}_{n_2\times n_2},\textbf{0}_{n_2\times n_3};\textbf{0}_{n_3\times n_1},\textbf{0}_{n_3\times n_2},I_{n_3}],\\ &G_{j_1j_2}^{\rho}=\Omega_e^{1/2}\mathbb{W}_{j_1j_2}S^{-1}\Sigma_e^{1/2},\ U_{j_1j_2}^{\rho}=G_{j_1j_2}^{\rho}\Omega_e^{1/2}\textbf{X}\beta, L=\Omega_e^{1/2}\textbf{X},\ G_{\sigma_k}=-(2\sigma_k^2)^{-1}\Lambda_k, \end{align*}
其中, \Omega_e=\Sigma_e^{-1} 1 \leq j_1\neq j_2 \leq 3,1 \leq k \leq 3 .
附录 2 2.2 节 \Sigma_{1}^{M} \Sigma_{2}^{M}
\Sigma_{2}^{M}=\begin{pmatrix} \Sigma_{2\rho}^{M} & \Sigma_{2\rho\beta}^{M} & \Sigma_{2\rho\sigma}^{M} \\ \Sigma_{2\rho\beta}^{MT} & \Sigma_{2\beta}^{M}& \textbf{0}_{p \times 3}\\ \Sigma_{2\rho\sigma}^{MT} & \textbf{0}_{3 \times p}& \sigma_{2\sigma}^M \end{pmatrix}, \Sigma_{1}^{M}=\Sigma_{2}^{M}+\begin{pmatrix} \Delta_{\rho} & \Delta_{\rho\beta} & \Delta_{\rho\sigma}\\ \Delta_{\rho\beta}^T & \textbf{0}_{p \times p} & \Delta_{\beta\sigma} \\ \Delta_{\rho\beta}^T & \Delta_{\beta\sigma} ^T & \Delta_{\sigma} \end{pmatrix},
\begin{align*} & \Sigma_{2\rho}^M= \begin{pmatrix} \kappa_{12} & \kappa_{12,13}^a & \kappa_{12,21}^a & \kappa_{12,23}^a & \kappa_{12,31}^a & \kappa_{12,32}^a \\ \kappa_{13,12}^a & \kappa_{13} & \kappa_{13,21}^a & \kappa_{13,23}^a & \kappa_{13,31}^a& \kappa_{13,32}^a \\ \kappa_{21,12}^a & \kappa_{21,13}^a & \kappa_{21} & \kappa_{21,23}^a & \kappa_{21,31}^a & \kappa_{21,32}^a\\ \kappa_{23,12}^a & \kappa_{23,13}^a & \kappa_{23,21}^a & \kappa_{23} & \kappa_{23,31}^a & \kappa_{23,32}^a \\ \kappa_{31,12}^a & \kappa_{31,13}^a & \kappa_{31,21}^a & \kappa_{31,23}^a & \kappa_{31} & \kappa_{31,32}^a \\ \kappa_{32,12}^a & \kappa_{32,13}^a & \kappa_{32,21}^a & \kappa_{32,23}^a & \kappa_{32,31}^a & \kappa_{32} \end{pmatrix},\\ & \kappa_{12}=\kappa_{12}^a+\kappa_{12}^b+\kappa_{12}^c,\quad \kappa_{13}=\kappa_{13}^a+\kappa_{13}^b+\kappa_{13}^c,\quad \kappa_{21}=\kappa_{21}^a+\kappa_{21}^b+\kappa_{21}^c,\\ & \kappa_{23}=\kappa_{23}^a+\kappa_{23}^b+\kappa_{23}^c,\quad \kappa_{31}=\kappa_{31}^a+\kappa_{31}^b+\kappa_{31}^c,\quad \kappa_{32}=\kappa_{32}^a+\kappa_{32}^b+\kappa_{32}^c,\\ & \Sigma_{2\rho\beta}^M=(\kappa_{\beta,12}^T,\kappa_{\beta,13}^T,\kappa_{\beta,21}^T,\kappa_{\beta,23}^T,\kappa_{\beta,31}^T,\kappa_{\beta,32}^T)^T,\quad \Sigma_{2\beta}^M=\kappa_\beta,\\ & \Sigma_{2\rho\sigma}^M= \begin{pmatrix} \kappa_{\rho\sigma,1,12} & \kappa_{\rho\sigma,2,12} & \kappa_{\rho\sigma,3,12}\\ \kappa_{\rho\sigma,1,13} & \kappa_{\rho\sigma,2,13} & \kappa_{\rho\sigma,3,13}\\ \kappa_{\rho\sigma,1,21} & \kappa_{\rho\sigma,2,21} & \kappa_{\rho\sigma,3,21}\\ \kappa_{\rho\sigma,1,23} & \kappa_{\rho\sigma,2,23} & \kappa_{\rho\sigma,3,23}\\ \kappa_{\rho\sigma,1,31} & \kappa_{\rho\sigma,2,31} & \kappa_{\rho\sigma,3,31}\\ \kappa_{\rho\sigma,1,32} & \kappa_{\rho\sigma,2,32} & \kappa_{\rho\sigma,3,32} \end{pmatrix}, \Delta_{\rho\sigma}= \begin{pmatrix} \Delta_{\rho\sigma,1,12}& \Delta_{\rho\sigma,2,12}& \Delta_{\rho\sigma,3,12}\\ \Delta_{\rho\sigma,1,13}& \Delta_{\rho\sigma,2,13}& \Delta_{\rho\sigma,3,13}\\ \Delta_{\rho\sigma,1,21}& \Delta_{\rho\sigma,2,21}& \Delta_{\rho\sigma,3,21}\\ \Delta_{\rho\sigma,1,23}& \Delta_{\rho\sigma,2,23}& \Delta_{\rho\sigma,3,23}\\ \Delta_{\rho\sigma,1,31}& \Delta_{\rho\sigma,2,31}& \Delta_{\rho\sigma,3,31}\\ \Delta_{\rho\sigma,1,32}& \Delta_{\rho\sigma,2,32}& \Delta_{\rho\sigma,3,32} \end{pmatrix}, \\ & \Sigma_{2\sigma}^M= \begin{pmatrix} \frac{n_1}{2N\sigma_1^4} & 0 & 0 \\ 0& \frac{n_2}{2N\sigma_2^4} & 0 \\ 0 & 0 & \frac{n_3}{2N\sigma_3^4} \end{pmatrix}, \quad \Delta_{\sigma}=\frac{\kappa_4-3}{4} \begin{pmatrix} \frac{n_1}{N\sigma_1^4} & 0 & 0\\ 0& \frac{n_2}{N\sigma_2^4} & 0\\ 0 & 0& \frac{n_3}{N\sigma_3^4} \end{pmatrix},\\ & \Delta_{\rho}={\rm diag}(\Delta_{\rho,12} \quad \Delta_{\rho,13} \quad \Delta_{\rho,21} \quad \Delta_{\rho,23} \quad \Delta_{\rho,31} \quad \Delta_{\rho,32}),\\ & \Delta_{\beta\sigma}=(\Delta_{\rho\sigma,1}^T,\Delta_{\rho\sigma,2}^T,\Delta_{\rho\sigma,3}^T)^T, \Delta_{\rho\beta}=(\Delta_{\rho\beta,12}^T,\Delta_{\rho\beta,13}^T,\Delta_{\rho\beta,21}^T,\Delta_{\rho\beta,23}^T,\Delta_{\rho\beta,31}^T,\Delta_{\rho\beta,33}^T)^T. \end{align*}
附录 3 引理 2.2 的证明
\mathcal{F}\{\tilde{Y}_{(i)}|\tilde{Y}_{(-i)}\}=\Sigma_{i,(-i)}\Sigma_{(-i),(-i)}^{-1}\tilde{Y}_{(-i)},
其中 \Sigma_{i,(-i)} \in R^{1\times(N-1)} \Sigma i i \Sigma_{(-i),(-i)} \in R^{(N-1)\times(N-1)} \Sigma i i \Omega=\Sigma^{-1} \Sigma=(\textbf{I}_{N}-\textbf{W}_{\rho})^{-1}\Sigma_e(\textbf{I}_{N}-\textbf{W}_{\rho}^T)^{-1} \Sigma_{i,(-i)}=-\Omega_{i,i}^{-1}\Omega_{i,(-i)}(\Omega_{(-i),(-i)}-\Omega_{i,(-i)}^T\Omega_{i,i}^{-1}\Omega_{i,(-i)})^T,\Sigma_{(-i),(-i)}^{-1}=\Omega_{(-i),(-i)}-\Omega_{i,(-i)}^T\Omega_{i,i}^{-1}\Omega_{i,(-i)}. \mathcal{F}\{\tilde{Y}_{(i)}|\tilde{Y}_{(-i)}\}=-\Omega_{i,i}^{-1}\Omega_{i,(-i)}\tilde{Y}_{(-i)}.
回顾 \Omega=\Sigma^{-1}=\Sigma_e^{-1}-\Sigma_e^{-1}W_{\rho}-W_{\rho}^{T}\Sigma_e^{-1}+W_{\rho}\Sigma_e^{-1}W_{\rho}^T j_1,j_2,j_3 \in \{1,2,3\}, i\in N_j, j_1 \neq j_2 \neq j_3
\begin{align*} \Omega=& \begin{pmatrix} \sigma_1^{-2}\textbf{I}_{n_1} & \textbf{0} & \textbf{0} \\ \textbf{0} & \sigma_2^{-2}\textbf{I}_{n_2} & \textbf{0}\\\textbf{0} & \textbf{0} & \sigma_3^{-2}\textbf{I}_{n_3}\end{pmatrix} -\begin{pmatrix} \sigma_1^{-2}\textbf{I}_{n_1} & \textbf{0} & \textbf{0} \\ \textbf{0} & \sigma_2^{-2}\textbf{I}_{n_2} & \textbf{0}\\\textbf{0} & \textbf{0} & \sigma_3^{-2}\textbf{I}_{n_3}\end{pmatrix}\begin{pmatrix} \textbf{0} & \rho_{12}W_{12}& \rho_{13}W_{13} \\ \rho_{21}W_{21} & \textbf{0}\rho_{23}W_{23}\\\rho_{31}W_{31}& \rho_{32}W_{32}& \textbf{0} \end{pmatrix}\\&-\begin{pmatrix} \textbf{0} & \rho_{12}W_{12}^T& \rho_{13}W_{13}^T \\ \rho_{21}W_{21}^T & \textbf{0}& \rho_{23}W_{23}^T\\\rho_{31}W_{31}^T& \rho_{32}W_{32}^T& \textbf{0} \end{pmatrix}\begin{pmatrix} \sigma_1^{-2}\textbf{I}_{n_1} & \textbf{0} & \textbf{0} \\ \textbf{0} & \sigma_2^{-2}\textbf{I}_{n_2} & \textbf{0}\\\textbf{0} & \textbf{0} & \sigma_3^{-2}\textbf{I}_{n_3}\end{pmatrix} +\begin{pmatrix} \textbf{0} & \rho_{12}W_{12}& \rho_{13}W_{13} \\ \rho_{21}W_{21} & \textbf{0}& \rho_{23}W_{23}\\\rho_{31}W_{31}& \rho_{32}W_{32}& \textbf{0} \end{pmatrix}\\ & \quad \begin{pmatrix} \sigma_1^{-2}\textbf{I}_{n_1} & \textbf{0} & \textbf{0} \\ \textbf{0} & \sigma_2^{-2}\textbf{I}_{n_2} & \textbf{0}\\\textbf{0} & \textbf{0} & \sigma_3^{-2}\textbf{I}_{n_3}\end{pmatrix} \begin{pmatrix} \textbf{0} & \rho_{12}W_{12}^T& \rho_{13}W_{13}^T \\ \rho_{21}W_{21}^T & \textbf{0}& \rho_{23}W_{23}^T\\\rho_{31}W_{31}^T& \rho_{32}W_{32}^T& \textbf{0} \end{pmatrix} =\begin{pmatrix} { \omega_{11} } & { \omega_{12} } & { \omega_{13} }\\ { \omega_{21} } & { \omega_{22} } & { \omega_{23} }\\ { \omega_{31} } & { \omega_{32} } & { \omega_{33} } \end{pmatrix}, \end{align*}
\begin{align*} \omega_{11}&=\frac{\textbf{I}_{n_1}}{\sigma_1^{2}}+\frac{\rho_{12}^2W_{12}W_{12}^T}{\sigma_2^{2}}+\frac{\rho_{13}^2W_{13}W_{13}^T }{\sigma_3^{2}}, \omega_{12}=-\frac{\rho_{12}W_{12}}{\sigma_1^{2}}-\frac{\rho_{21}W_{21}^T}{\sigma_2^{2}}+\frac{\rho_{13}\rho_{23}W_{13}W_{23}^T}{\sigma_3^{2}},\\ \omega_{13}&=-\frac{\rho_{13}W_{13}}{\sigma_1^{2}}-\frac{\rho_{31}W_{31}^T}{\sigma_2^{2}}+\frac{\rho_{12}\rho_{32}W_{12}W_{32}^T}{\sigma_3^{2}}, \omega_{21}=-\frac{\rho_{21}W_{21}}{\sigma_2^{2}}-\frac{\rho_{12}W_{12}^T}{\sigma_1^{2}}+\frac{\rho_{23}\rho_{13}W_{23}W_{13}^T}{\sigma_3^{2}},\\ \omega_{22}&=\frac{\textbf{I}_{n_2}}{\sigma_2^{2}}+\frac{\rho_{21}^2W_{21}W_{21}^T}{\sigma_1^{2}}+\frac{\rho_{23}^2W_{23}W_{23}^T}{\sigma_3^{2}}, \omega_{23}=-\frac{\rho_{23}W_{23}}{\sigma_2^{2}}-\frac{\rho_{32}W_{32}^T}{\sigma_3^{2}}+\frac{\rho_{21}\rho_{31}W_{21}W_{31}^T}{\sigma_1^{2}},\\ \omega_{31}&=-\frac{\rho_{31}W_{31}}{\sigma_3^{2}}-\frac{\rho_{13}W_{13}^T}{\sigma_1^{2}}+\frac{\rho_{32}\rho_{12}W_{32}W_{12}^T}{\sigma_2^{2}}, \omega_{32}=-\frac{\rho_{32}W_{32}}{\sigma_3^{2}}-\frac{\rho_{23}W_{23}^T}{\sigma_2^{2}}+\frac{\rho_{31}\rho_{21}W_{31}W_{21}^T}{\sigma_1^{2}},\\ \omega_{33}&=\frac{\textbf{I}_{n_3}}{\sigma_3^{2}}+\frac{\rho_{31}^2W_{31}W_{31}^T}{\sigma_1^{2}}+\frac{\rho_{32}^2W_{32}W_{32}^T}{\sigma_2^{2}}. \end{align*}
进而得到: 若 i \in N_j, j_1,j_2,j_3 \in \{1,2,3\}, j_1 \neq j_2 \neq j_3
\Omega_{i,i}=\sigma_{j_1}^{-2}+\sigma_{j_2}^{-2}\Sigma_{k \in \mathcal{N}_{j_2}}\rho_{j_{1}j_{2}}w_{ki}^2+\sigma_{j_3}^{-2}\Sigma_{k \in \mathcal{N}_{j_3}}\rho_{j_{1}j_{3}}w_{ki}^2,
\begin{align*} & \mathcal{F}\{\tilde{Y}_{(i)}|\tilde{Y}_{(-i)}\}=-\Omega_{i,i}^{-1}\Omega_{i,(-i)}\tilde{Y}_{(-i)}\\ =\ & \Sigma_{i_1 \in \mathcal{N}_{j_{1}}}\frac{\sigma_{j_2}^2\sigma_{j_3}^2\rho_{j_{2}j_{1}}w_{ii_1}+\sigma_{j_2}^2\sigma_{j_3}^2\rho_{j_{1}j_{2}}w_{i_{1}i}+\sigma_{j_1}^2\sigma_{j_2}^2\rho_{j_{2}j_{3}}\rho_{j_{1}j_{3}}\Sigma_{k \in \mathcal{N}_{j_{3}}}w_{ik}w_{i_{1}k}}{\sigma_{j_2}^2\sigma_{j_3}^2+\sigma_{j_2}^2\sigma_{j_3}^2\alpha_{i}\rho_{j_{1}j_{2}}+\sigma_{j_1}^2\sigma_{j_2}^2\beta_{i}\rho_{j_{1}j_{3}}}\tilde{Y}_{i_1}\\ &-\Sigma_{i_2 \in \mathcal{N}_{j_{2}}}\frac{\sigma_{j_1}^2\sigma_{j_3}^2+\sigma_{j_2}^2\sigma_{j_3}^2\rho_{j_{2}j_{1}}w_{ii_2}^2+\sigma_{j_1}^2\sigma_{j_2}^2\rho_{j_{2}j_{3}}^2\Sigma_{k \in \mathcal{N}_{j_{3}}}w_{ik}^2}{\sigma_{j_2}^2\sigma_{j_3}^2+\sigma_{j_2}^2\sigma_{j_3}^2\alpha_{i}\rho_{j_{1}j_{2}}+\sigma_{j_1}^2\sigma_{j_2}^2\beta_{i}\rho_{j_{1}j_{3}}}\tilde{Y}_{i_2}\\ &+\Sigma_{i_3 \in \mathcal{N}_{j_{3}}}\frac{\sigma_{j_1}^2\sigma_{j_3}^2\rho_{j_{2}j_{3}}w_{ii_3}-\sigma_{j_1}^2\sigma_{j_2}^2\rho_{j_{3}j_{2}}w_{i_{3}i}+\sigma_{j_2}^2\sigma_{j_3}^2\rho_{j_{2}j_{1}}\rho_{j_{3}j_{1}}\Sigma_{k \in \mathcal{N}_{j_{3}}}w_{ik}w_{i_{3}k}}{\sigma_{j_2}^2\sigma_{j_3}^2+\sigma_{j_2}^2\sigma_{j_3}^2\alpha_{i}\rho_{j_{1}j_{2}}+\sigma_{j_1}^2\sigma_{j_2}^2\beta_{i}\rho_{j_{1}j_{3}}}\tilde{Y}_{i_3}, \end{align*}
其中w_{ki} W (k,i) \alpha_i=\Sigma_{k \in \mathcal{N}_{j_{2}}}w_{ki}^2 \beta_i=\Sigma_{k \in \mathcal{N}_{j_{3}}}w_{ki}^2 . 引理得证.
附录4 2.3 节 Q(\gamma)
\begin{align*} \frac{\partial Q(\gamma)}{\partial \beta}=& -2(P_1P_4+P_2P_5+P_3P_6),\\ \frac{\partial Q(\gamma)}{\partial \rho_{12}}=\ & 2(P_5^T\frac{\partial m_2}{\partial \rho_{12}}(\frac{\varepsilon_2}{\sigma_2^2}-\frac{\rho_{12}W_{12}^T\varepsilon_1}{\sigma_1^2}-\frac{\rho_{32}W_{32}^T\varepsilon_3}{\sigma_3^2})-\frac{P_5^Tm_2W_{12}^T\varepsilon_1}{\sigma_1^2}\\ & -\frac{P_4^Tm_1W_{12}Y_2}{\sigma_1^2}+\frac{P_5^Tm_2\rho_{12}W_{12}^TW_{12}Y_2}{\sigma_1^2}+\frac{P_6^Tm_3\rho_{13}W_{13}^TW_{12}Y_2}{\sigma_1^2}),\\ \frac{\partial Q(\gamma)}{\partial \rho_{13}}=\ & 2(P_6^T\frac{\partial m_3}{\partial \rho_{13}}(\frac{\varepsilon_3}{\sigma_3^2}-\frac{\rho_{13}W_{13}^T\varepsilon_1}{\sigma_1^2}-\frac{\rho_{23}W_{23}^T\varepsilon_2}{\sigma_2^2})-\frac{P_6^Tm_3W_{13}^T\varepsilon_1}{\sigma_1^2}\\ & -\frac{P_4^Tm_1W_{13}Y_3}{\sigma_1^2}+\frac{P_5^Tm_2\rho_{12}W_{12}^TW_{13}Y_3}{\sigma_1^2}+\frac{P_6^Tm_3\rho_{13}W_{13}^TW_{13}Y_3}{\sigma_1^2}),\\ \frac{\partial Q(\gamma)}{\partial \rho_{21}}=\ & 2(P_4^T\frac{\partial m_1}{\partial \rho_{21}}(\frac{\varepsilon_1}{\sigma_1^2}-\frac{\rho_{21}W_{21}^T\varepsilon_2}{\sigma_2^2}-\frac{\rho_{31}W_{31}^T\varepsilon_3}{\sigma_3^2})-\frac{P_4^Tm_1W_{21}^T\varepsilon_2}{\sigma_2^2}\\ & -\frac{P_5^Tm_2W_{21}Y_1}{\sigma_2^2}+\frac{P_4^Tm_1\rho_{21}W_{21}^TW_{21}Y_1}{\sigma_2^2}+\frac{P_6^Tm_3\rho_{23}W_{23}^TW_{21}Y_1}{\sigma_2^2}),\\ \frac{\partial Q(\gamma)}{\partial \rho_{23}}=\ &2(P_6^T\frac{\partial m_3}{\partial \rho_{23}}(\frac{\varepsilon_3}{\sigma_3^2}-\frac{\rho_{13}W_{13}^T\varepsilon_1}{\sigma_1^2}-\frac{\rho_{23}W_{23}^T\varepsilon_2}{\sigma_2^2})-\frac{P_6^Tm_3W_{23}^T\varepsilon_2}{\sigma_2^2}\\ & -\frac{P_5^Tm_2W_{23}Y_3}{\sigma_2^2}+\frac{P_4^Tm_1\rho_{21}W_{21}^TW_{23}Y_3}{\sigma_2^2}+\frac{P_6^Tm_3\rho_{23}W_{23}^TW_{23}Y_3}{\sigma_2^2}),\\ \frac{\partial Q(\gamma)}{\partial \rho_{31}}=\ & 2(P_4^T\frac{\partial m_1}{\partial \rho_{31}}(\frac{\varepsilon_1}{\sigma_1^2}-\frac{\rho_{21}W_{21}^T\varepsilon_2}{\sigma_2^2}-\frac{\rho_{31}W_{31}^T\varepsilon_3}{\sigma_3^2})-\frac{P_4^Tm_1W_{31}^T\varepsilon_3}{\sigma_3^2}\\ & -\frac{P_6^Tm_3W_{31}Y_1}{\sigma_3^2}+\frac{P_4^Tm_1\rho_{31}W_{31}^TW_{31}Y_1}{\sigma_3^2}+\frac{P_5^Tm_2\rho_{32}W_{32}^TW_{31}Y_1}{\sigma_3^2}),\\ \frac{\partial Q(\gamma)}{\partial \rho_{32}}=\ & 2(P_5^T\frac{\partial m_2}{\partial \rho_{32}}(\frac{\varepsilon_2}{\sigma_2^2}-\frac{\rho_{12}W_{12}^T\varepsilon_1}{\sigma_1^2}-\frac{\rho_{32}W_{32}^T\varepsilon_3}{\sigma_3^2})-\frac{P_5^Tm_2W_{32}^T\varepsilon_3}{\sigma_3^2}\\ &-\frac{P_6^Tm_3W_{32}Y_2}{\sigma_3^2}+\frac{P_4^Tm_1\rho_{31}W_{31}^TW_{32}Y_2}{\sigma_3^2}+\frac{P_5^Tm_2\rho_{32}W_{32}^TW_{32}Y_2}{\sigma_3^2}), \end{align*}
\begin{align*} P_1&=(\frac{X_1^T}{\sigma_1^2}-\frac{\rho_{21}X_2^TW_{21}}{\sigma_2^2}-\frac{\rho_{31}X_3^TW_{31}}{\sigma_3^2})m_1, P_2=(\frac{X_2^T}{\sigma_2^2}-\frac{\rho_{12}X_1^TW_{12}}{\sigma_1^2}-\frac{\rho_{32}X_3^TW_{32}}{\sigma_3^2})m_2,\\ P_3&=(\frac{X_3^T}{\sigma_3^2}-\frac{\rho_{13}X_1^TW_{13}}{\sigma_1^2}-\frac{\rho_{23}X_2^TW_{23}}{\sigma_2^2})m_3, P_4=m_1(\frac{\varepsilon_1}{\sigma_1^2}-\frac{\rho_{21}W_{21}^T\varepsilon_2}{\sigma_2^2}-\frac{\rho_{31}W_{31}^T\varepsilon_3}{\sigma_3^2}),\\ P_5&=m_2(\frac{\varepsilon_2}{\sigma_2^2}-\frac{\rho_{12}W_{12}^T\varepsilon_1}{\sigma_1^2}-\frac{\rho_{32}W_{32}^T\varepsilon_3}{\sigma_3^2}), P_6=m_3(\frac{\varepsilon_3}{\sigma_3^2}-\frac{\rho_{13}W_{13}^T\varepsilon_1}{\sigma_1^2}-\frac{\rho_{23}W_{23}^T\varepsilon_2}{\sigma_2^2}). \end{align*}
附录5 2.3 节 \Sigma_1^L \Sigma_2^L
\begin{align*} & \Sigma_1^L= \begin{pmatrix} \Sigma_{1\rho}^L & \Sigma_{1\rho\beta}^L \\ \Sigma_{1\rho\beta}^{LT} & \Sigma_{1\beta}^L \end{pmatrix},\quad \Sigma_2^L= \begin{pmatrix} \Sigma_{2\rho}^L & \Sigma_{2\rho\beta}^L \\ \Sigma_{2\rho\beta}^{LT} & \Sigma_{2\beta}^L \end{pmatrix},\\ & \Sigma_{1\rho}^L = \begin{pmatrix} \kappa_{12,12}^{*} & \kappa_{12,13}^{*} & \kappa_{12,21}^{*} & \kappa_{12,23}^{*} & \kappa_{12,31}^{*} & \kappa_{12,32}^{*} \\ \kappa_{13,12}^{*} & \kappa_{13,13}^{*} & \kappa_{13,21}^{*} & \kappa_{13,23}^{*} & \kappa_{13,31}^{*} & \kappa_{13,32}^{*} \\ \kappa_{21,12}^{*} & \kappa_{21,13}^{*} & \kappa_{21,21}^{*} & \kappa_{21,23}^{*} & \kappa_{21,31}^{*} & \kappa_{21,32}^{*} \\ \kappa_{23,12}^{*} & \kappa_{23,13}^{*} & \kappa_{23,21}^{*} & \kappa_{23,23}^{*} & \kappa_{23,31}^{*} & \kappa_{23,32}^{*} \\ \kappa_{31,12}^{*} & \kappa_{31,13}^{*} & \kappa_{31,21}^{*} & \kappa_{31,23}^{*} & \kappa_{31,31}^{*} & \kappa_{31,32}^{*} \\ \kappa_{32,12}^{*} & \kappa_{32,13}^{*} & \kappa_{32,21}^{*} & \kappa_{32,23}^{*} & \kappa_{32,31}^{*} & \kappa_{32,32}^{*} \end{pmatrix},\\ & \Sigma_{2\rho}^L = \begin{pmatrix} \kappa_{12,12}^{**} & \kappa_{12,13}^{**} & \kappa_{12,21}^{**} & \kappa_{12,23}^{**} & \kappa_{12,31}^{**} & \kappa_{12,32}^{**} \\ \kappa_{13,12}^{**} & \kappa_{13,13}^{**} & \kappa_{13,21}^{**} & \kappa_{13,23}^{**} & \kappa_{13,31}^{**} & \kappa_{13,32}^{**} \\ \kappa_{21,12}^{**} & \kappa_{21,13}^{**} & \kappa_{21,21}^{**} & \kappa_{21,23}^{**} & \kappa_{21,31}^{**} & \kappa_{21,32}^{**} \\ \kappa_{23,12}^{**} & \kappa_{23,13}^{**} & \kappa_{23,21}^{**} & \kappa_{23,23}^{**} & \kappa_{23,31}^{**} & \kappa_{23,32}^{**} \\ \kappa_{31,12}^{**} & \kappa_{31,13}^{**} & \kappa_{31,21}^{**} & \kappa_{31,23}^{**} & \kappa_{31,31}^{**} & \kappa_{31,32}^{**} \\ \kappa_{32,12}^{**} & \kappa_{32,13}^{**} & \kappa_{32,21}^{**} & \kappa_{32,23}^{**} & \kappa_{32,31}^{**} & \kappa_{32,32}^{**} \end{pmatrix},\\ & \Sigma_{1\rho\beta}^L =(\kappa_{\beta,12}^{*}, \kappa_{\beta,13}^{*}, \kappa_{\beta,21}^{*}, \kappa_{\beta,23}^{*}, \kappa_{\beta,31}^{*}, \kappa_{\beta,32}^{*})^T,\\ & \Sigma_{2\rho\beta}^L =(\kappa_{\beta,12}^{**}, \kappa_{\beta,13}^{**}, \kappa_{\beta,21}^{**}, \kappa_{\beta,23}^{**}, \kappa_{\beta,31}^{**}, \kappa_{\beta,32}^{**})^T, \Sigma_{1\beta}^L =\kappa^*,\quad \Sigma_{2\beta}^L=\kappa^{**}. \end{align*}
参考文献
View Option
[1]
Anselin L . Spatial Econometrics:Methods and Models. New York : Springer , 1988
[本文引用: 1]
[2]
Borgatti S P Everett M G . Network analysis of 2-mode data
Social Networks, 1997 , 19 243 -269
[本文引用: 1]
[3]
Cai Q Liu J M . Hierarchical clustering of bipartite networks based on multiobjective optimization
IEEE Transactions on Network Science and Engineering, 2020 , 7 421 -434
[本文引用: 2]
[4]
Chen E Fan J Zhu X . Community network auto-regression for high-dimensional time serie
Journal of Econometrics, 2023 , 235 1239 -1256
[本文引用: 1]
[5]
Chen X Chen Y Xiao P . The impact of sampling and network topology on the estimation of social intercorrelations
Journal of Marketing Research, 2013 , 50 95 -110
[本文引用: 1]
[6]
Cohen-Cole E Liu X Zenou Y . Multivariate choices and identification of social interactions
Journal of Applied Econometrics, 2018 , 33 165 -178
[本文引用: 1]
[7]
D'Esposito M R De Stefano D Ragozini G . On the use of multiple correspondence analysis to visually explore affiliation networks
Social Networks, 2014 , 38 28 -40
[本文引用: 1]
[8]
Everett M G Borgatti S P . The dual-projection approach for two-mode networks
Social Networks, 2013 , 35 204 -210
[本文引用: 2]
[9]
Feng L Zhou C Zhao Q . A spectral method to find communities in bipartite networks
Physica A, 2019 , 513 424 -437
DOI:10.1016/j.physa.2018.09.022
[本文引用: 1]
Community detection in complex networks that aims to find partitions of networks with dense intra-edges and sparse inter-edges, has recently attracted lots of interest in many fields. Specially, bipartite networks composed of two different types of vertices are the common representations for many real-world networks, such as actor-film, consumer-product networks, etc. In this paper, we show that optimizing Barber's bipartite modularity, which is widely used to evaluate partitions of bipartite networks, can be reformulated as a spectral problem with appropriate relaxations. We further propose a new method combining singular value decomposition(SVD) and BRIM algorithm to obtain an optimal community partition. Compared with many other algorithms, the new method can give us a more detailed and comprehensive view of the original bipartite network for different cluster numbers k. We test our method on both synthetic networks and two benchmark data sets. Experimental results show that, our method is not only capable to extract a community partition with a larger bipartite modularity, but also converge to the exact underlying community partition when k is appropriately set, which helps to alleviate the resolution limit issue to some extent. (C) 2018 Elsevier B.V.
[10]
Gao M Chen L . A projection based algorithm for link prediction in bipartite network
International Conference on Information System and Artifical Intelligence, 2016 : 56 -61
[本文引用: 1]
[11]
Huang D . Least squares estimation of spatial autoregressive models for large-scale social networks
Electronic Journal of Statistics, 2019 , 13 1135 -1165
[本文引用: 2]
[12]
Huang D Wang F Zhu X Wang H . Two-mode network autoregressive model for large-scale networks
Journal of Econometrics, 2020 , 216 203 -219
[本文引用: 11]
[13]
Kelejian H H Prucha I R . Specification and estimation of spatial autoregressive models with autoregressive and heteroskedastic disturbances
Journal of Econometrics, 2010 , 157 53 -67
PMID:20577573
[本文引用: 2]
This study develops a methodology of inference for a widely used Cliff-Ord type spatial model containing spatial lags in the dependent variable, exogenous variables, and the disturbance terms, while allowing for unknown heteroskedasticity in the innovations. We first generalize the GMM estimator suggested in Kelejian and Prucha (1998,1999) for the spatial autoregressive parameter in the disturbance process. We also define IV estimators for the regression parameters of the model and give results concerning the joint asymptotic distribution of those estimators and the GMM estimator. Much of the theory is kept general to cover a wide range of settings.
[14]
Lee L . Asymptotic distributions of quasi-maximum likelihood estimators for spatial autoregressive models
Econometrica, 2004 , 72 1899 -1925
[本文引用: 1]
[15]
LeSage J P Pace R K . Introduction to Spatial Econometrics
Boca Raton: Chapman and Hall/CRC, 2009
[本文引用: 2]
[16]
Li X Chen H . Recommendation as link prediction in bipartite graphs: A graph kernel-based machine learning approach
Decision Support Systems, 2013 , 54 880 -890
[本文引用: 2]
[17]
Liu X . Identification and efficient estimation of simultaneous equations network models
Journal of Business & Econometrics Statistics, 2014 , 32 516 -536
[本文引用: 1]
[18]
Malikov E Sun Y . Semiparametric estimation and testing of smooth coefficient spatial autoregressive models
Journal of Econometrics, 2017 , 199 12 -34
[本文引用: 1]
[19]
Ord K . Estimation methods for models of spatial interaction
Journal of the American Statistical Association, 1975 , 70 120 -126
[本文引用: 1]
[20]
Ouyang F . Using three social network analysis approaches to understand computer-supported collaborative learning
Journal of Educational Computing Research, 2021 , 59 1401 -1424
[本文引用: 1]
[21]
Seber G A . A Matrix Handbook for Statisticians. New York : Wiley , 2008
[本文引用: 1]
[22]
Shumway R Stoffer D . Time Series Analysis and Its Applications. New York : Springer , 2017
[本文引用: 2]
[23]
White H . Estimation, Inference and Specification Analysis. Cambridge : Cambridge University Press , 1996
[本文引用: 1]
[24]
Yang K Lee L F . Identification and QML estimation of multivariate and simultaneous equations spatial autoregressive models
Journal of Econometrics, 2017 , 196 196 -214
[本文引用: 2]
[25]
Zhu X Pan R . Grouped network vector autoregression
Statistica Sinica, 2020 , 30 1437 -1462 .
[本文引用: 1]
[26]
Zhu X Pan R Li G , et al . Network vector autoregression
Annals of Satistics, 2017 , 45 1096 -1123
[本文引用: 1]
1
1988
... 网络数据是指用有向图或者无向图作为一种通用语言的数据, 在生活中也很普遍, 例如新冠病毒传播网络、基因网络、金融网络、交通网络、通话网络等. 对于网络数据的分析, 过去的研究主要是集中在对于网络结构的分析上. 对此, 学者们提出了许多模型来描述网络结构, 最初是对空间结构进行描述, 因而对于网络模型的构建是建立在空间模型的基础上. Ord[19 ] 提出了空间自回归 (SAR) 模型, 它研究了空间结构对于用户所产生的影响. 基于 SAR 模型, Anselin[1 ] 提出了空间杜宾模型, 该模型考虑了协变量与误差项的相关性, 之后相继提出了空间误差模型与 SAR 组合模型, LeSage 和 Pace[15 ] 从空间数据出发, 给出了更一般的空间自回归模型, 将上述模型都包含其中. ...
Network analysis of 2-mode data
1
1997
... 但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
Hierarchical clustering of bipartite networks based on multiobjective optimization
2
2020
... 但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
... [3 ]研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
Community network auto-regression for high-dimensional time serie
1
2023
... 为了研究网络结构对于用户所带来的影响, 基于 SAR 模型, Chen 等[5 ] 提出了网络自回归 (NAR) 模型. 随后, Zhu 等[26 ] 考虑了大规模社交网络中 NAR 模型, 并给出了 NAR 模型的平稳性. 已有的文献大多都假设 NAR 模型中各种节点之间是不存在差别的, 很少对节点的异质性进行考虑. 为了弱化这一假设, Malikov 和 Sun[18 ] 提出一种灵活的半参数 SAR 模型, 允许空间自回归参数在单元间变化, 从而允许变量识别特定社区的空间依赖性. Zhu 和 Pan[25 ] 基于 NAR 模型, 建立了分组 NAR 模型, 将网络个体划分不同的组, 不同组的 NAR 模型具有不同的参数; Chen 等[4 ] 提出了社区 NAR 模型, 基于拥有 N K
The impact of sampling and network topology on the estimation of social intercorrelations
1
2013
... 为了研究网络结构对于用户所带来的影响, 基于 SAR 模型, Chen 等[5 ] 提出了网络自回归 (NAR) 模型. 随后, Zhu 等[26 ] 考虑了大规模社交网络中 NAR 模型, 并给出了 NAR 模型的平稳性. 已有的文献大多都假设 NAR 模型中各种节点之间是不存在差别的, 很少对节点的异质性进行考虑. 为了弱化这一假设, Malikov 和 Sun[18 ] 提出一种灵活的半参数 SAR 模型, 允许空间自回归参数在单元间变化, 从而允许变量识别特定社区的空间依赖性. Zhu 和 Pan[25 ] 基于 NAR 模型, 建立了分组 NAR 模型, 将网络个体划分不同的组, 不同组的 NAR 模型具有不同的参数; Chen 等[4 ] 提出了社区 NAR 模型, 基于拥有 N K
Multivariate choices and identification of social interactions
1
2018
... 其中假定 \varepsilon_1 \varepsilon_2 \varepsilon_3 {\rm Cov}(\varepsilon_1)=\sigma_1^{2}{\bf I}_{n_1} {\rm Cov}(\varepsilon_2)=\sigma_2^{2}{\bf I}_{n_2} {\rm Cov}(\varepsilon_3)=\sigma_3^{2}{\bf I}_{n_3} \textbf{I}_n\in \mathbb{R}^{n\times n}(n=n_1,n_2,n_3) \rho_{kl}({1\leqslant k\ne l \leqslant 3}) \rho_{12} \rho_{13} \rho_{21} \rho_{23} \rho_{31} \rho_{31} [17 ] 和 Cohen-Cole 等[6 ] , \beta_1 \beta_2 \beta_3
On the use of multiple correspondence analysis to visually explore affiliation networks
1
2014
... 但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
The dual-projection approach for two-mode networks
2
2013
... 但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
... 在实际中, 不止存在双模网络数据, 还存在大量的三模网络数据, 即一个网络中存在三种类型的节点, 同类型节点不直接相连, 不同类型的节点之间才可以直接相连, Everett 和 Borgatti[8 ] 在文中提到过三模数据, 并指出了一个犯罪行为按受害者分类可以构成三模网络数据集. Fan[20 ] 在文中提到了一个三模数据, 即学生-话题- 知识网络, 包括三种数据类型: 学生、讨论话题、知识术语. 此外还存在其他三模数据, 如: 第三方平台中商家、顾客、配送员所构成的网络, 校园评价系统中学生、老师、家长所构成的网络等. 因此, 本文基于 Huang 等[12 ] 所提出的双模 NAR 模型进行拓展, 考虑了三模 NAR 模型. ...
A spectral method to find communities in bipartite networks
1
2019
... 但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
A projection based algorithm for link prediction in bipartite network
1
2016
... 但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
Least squares estimation of spatial autoregressive models for large-scale social networks
2
2019
... 采用拟极大似然法进行参数估计的时候, 需要计算 \textbf{I}_{N}-\textbf{W}_{\rho} N [22 ] 所提出的 BLP, Huang[11 ] 提出了一种基于 BLP 的最小二乘估计方法. 定义 \tilde{Y}_i=Y_i-\mu_i \tilde{Y}_{(-i)}=Y_{(-i)}-\mu_{(-i)} \mu_i=E(Y_i) Y_{(-i)}=\{Y_j:j\ne i,1 \leqslant j \leqslant N\} \mu_{(-i)}=E(Y_{(-i)}) . 在给定\tilde{Y}_{(-i)} \tilde{Y}_i \mathcal{N}_1 \mathcal{N}_2 \mathcal{N}_3
... 其中 \tilde{Y}=\{Y_i-\mu_i,1\leqslant i \leqslant N\} [12 ] 已经给出了基于双模 NAR 形式的(2.4)和(2.5)式的证明, 在三模 NAR 模型中, 形式并未发生改变, 证明思路类似, 此处省略细节. 那么, \hat{\gamma}_M=\arg\min_{\gamma}Q(\gamma)\in \mathbb{R}^{p+ 6 } . Huang[11 ] 所提出的基于 BLP 的最小二乘估计, 在计算的过程中并未涉及到对于大规模矩阵的行列式计算, 其次, 虽然涉及到了矩阵的逆, 即 m \Sigma_e m \Sigma_e Q(\gamma) Q(\gamma)
Two-mode network autoregressive model for large-scale networks
11
2020
... 但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
... 在实际中, 不止存在双模网络数据, 还存在大量的三模网络数据, 即一个网络中存在三种类型的节点, 同类型节点不直接相连, 不同类型的节点之间才可以直接相连, Everett 和 Borgatti[8 ] 在文中提到过三模数据, 并指出了一个犯罪行为按受害者分类可以构成三模网络数据集. Fan[20 ] 在文中提到了一个三模数据, 即学生-话题- 知识网络, 包括三种数据类型: 学生、讨论话题、知识术语. 此外还存在其他三模数据, 如: 第三方平台中商家、顾客、配送员所构成的网络, 校园评价系统中学生、老师、家长所构成的网络等. 因此, 本文基于 Huang 等[12 ] 所提出的双模 NAR 模型进行拓展, 考虑了三模 NAR 模型. ...
... 定义 S=\textbf{I}_{N}-\textbf{W}_{\rho} \theta=(\rho_{12},\rho_{13},\rho_{21},\rho_{23},\rho_{31},\rho_{32},\beta^T,\sigma_1^2,\sigma_2^2,\sigma_3^2)^T\in \mathbb{R}^{p+9 } . 参考 Huang 等[12 ] , 拟极大似然函数写为 ...
... 为了建立 QMLE 估计的相合性与渐近正态性, 根据 Huang 等[12 ] 针对双模 NAR 模型计算得到的拟极大似然函数的一阶导数与二阶导数形式, 整理得到了三模 NAR 模型的拟极大似然函数的一阶导数与二阶导数形式, 结果如下 ...
... 定理 2.1 的证明借鉴了 Huang 等[12 ] 在双模 NAR 模型 QMLE 渐近正态性证明中得到的结论:\sqrt{N}(\hat{\theta}_M-\theta)=\{-\frac{\ddot{l}(\theta^*)}{N}\}^{-1}\{\frac{\dot{l}(\theta)}{\sqrt{N}}\} \theta^* \theta \hat{\theta}_M
... Huang 等[12 ] 指出了对于计算 |\textbf{I}_N-W_{\rho}| O(N^3) |\textbf{I}_N-W_{\rho}|
... 定义 \Omega=S^T\Sigma_{e}^{-1}S m=\{{\rm diag}(\Omega)\}^{-1} Y_c=\{\mathcal{F}\{\tilde{Y}_{(i)}|\tilde{Y}_{(-i)}\},i=1,2,\cdots,N\} {\rm diag}(A) A 12 ]得到的结论, 可以得到:Y_c=-m(\Omega-m^{-1})(Y-u), u=E(Y)=S^{-1}\textbf{X}\beta . 因此, 最小二乘目标函数可以构造为 ...
... 其中 \tilde{Y}=\{Y_i-\mu_i,1\leqslant i \leqslant N\} [12 ] 已经给出了基于双模 NAR 形式的(2.4)和(2.5)式的证明, 在三模 NAR 模型中, 形式并未发生改变, 证明思路类似, 此处省略细节. 那么, \hat{\gamma}_M=\arg\min_{\gamma}Q(\gamma)\in \mathbb{R}^{p+ 6 } . Huang[11 ] 所提出的基于 BLP 的最小二乘估计, 在计算的过程中并未涉及到对于大规模矩阵的行列式计算, 其次, 虽然涉及到了矩阵的逆, 即 m \Sigma_e m \Sigma_e Q(\gamma) Q(\gamma)
... 根据 Huang 等[12 ] 针对双模 NAR 模型整理的 Q(\gamma) 的一阶与二阶导数形式, 整理得到三模 NAR 模型的最小二乘估计的导数形式, 首先定义如下指标:\widetilde{S}=\Sigma_e^{-1}S=\Omega_eS , M_1=m\widetilde{S}^T\Sigma_e^{1/2} , M_{2,j_1j_2}=(\frac{\partial m}{\partial \rho_{j_1j_2}}\widetilde{S}^T+m\frac{\partial \widetilde{S}^T}{\partial \rho_{j_1j_2}}+m\widetilde{S}^T\frac{\partial S}{\partial \rho_{j_1j_2}}S^{-1})\Sigma_e^{1/2} , M_{3,j_1j_2}=m\widetilde{S}^T\frac{\partial S}{\partial \rho_{j_1j_2}}S^{-1} , J_{1,j_1j_2}=M_{3,j_1j_2}\textbf{X}\beta , M_{j_1j_2}=M_1^TM_{2,j_1j_2}, J_{j_1j_2}=M_1^TJ_{1,j_1j_2} , H=-2(m\widetilde{S}^T\textbf{X})^TM_1 .从而可以得到最小二乘估计函数的一阶导数与二阶导数形式 ...
... 定义 \mathbb{Q}(\gamma)=E(Q(\gamma)) [12 ] 得到的关于 Q(\gamma) \mathbb{Q}(\gamma)=||mS^T(\Sigma_e^{-1}\otimes\textbf{I})(SS_0^{-1}(\textbf{I}_p\otimes\textbf{X})\beta_0-(\textbf{I}_p\otimes\textbf{X})\beta||^2+{\rm tr}(m\Omega\Sigma_0\Omega m), \otimes \mathbb{Q}(\gamma)=||m\widetilde{S}^T(SS_0^{-1}\textbf{X}\beta_0-\textbf{X}\beta||^2+{\rm tr}(m\Omega\Sigma_0\Omega m).
... 定理 2.2 的证明借鉴了 Huang 等[12 ] 在双模 NAR 模型中 LSE 方法渐近正态性证明中得到的结论:\sqrt{N}(\hat{\gamma}-\gamma)=\{-\frac{\ddot{Q}(\gamma)}{N}\}^{-1}\{\frac{\dot{Q}(\gamma)}{\sqrt{N}}\} \theta^* \theta \hat{\theta}_M
Specification and estimation of spatial autoregressive models with autoregressive and heteroskedastic disturbances
2
2010
... 为了更好地刻画网络中各个节点的相邻程度, 构建权重矩阵. 定义 W_{kl}=(w_{kl,i_ki_l})=(a_{i_ki_l}/d_{i_k}) d_{i_k}=\sum\limits_{m=1}^{N} a_{i_km} k [13 ] 对权重矩阵进行了更加详细的描述与证明. 我们之后的模拟结果也说明了针对权重矩阵的不同生成方式, 模拟表现较好. 首先采用行标准化的方式对邻接矩阵进行标准化, 得到W=[\textbf{0}_{n_1\times n_1},W_{12},W_{13}; W_{21},\textbf{0}_{n_2\times n_2},W_{23};W_{31},W_{32},\textbf{0}_{n_3\times n_3}]\in \mathbb{R}^{N\times N}.
... 邻接矩阵 给定邻接矩阵 A W . 在行标准化的情形下, 我们定义W_{12} W_{13} W_{21} W_{23} W_{31} W_{32} A 13 ]中的方法, 通过 A A W . ...
Asymptotic distributions of quasi-maximum likelihood estimators for spatial autoregressive models
1
2004
... 每一个类型的节点 i_1 ( {1\leqslant i_1 \leqslant n_1} ) , i_2 ( {1\leqslant i_2 \leqslant n_2} ) 或 i_3 ( {1\leqslant i_3 \leqslant n_3} ) 分别对应一个响应变量 Y_{1,i_1}, Y_{2,i_2} Y_{3,i_3} Y_1=(Y_{1,1},\cdots,Y_{1,n_1})^T, Y_2=(Y_{2,1},\cdots,Y_{2,n_2})^T Y_3=(Y_{3,1},\cdots,Y_{3,n_3})^T . 为了增强响应变量的解释能力, 我们借助 LeSage 和 Pace[15 ] 中对于不同类型的响应节点引入不同的外生协变量, 分别将类型 I、II 和 III 节点的外生变量定义如下: X_1=(X_{1,1}^T, \cdots,X_{1,n_1}^T)^T\in \mathbb{R}^{n_1\times p_1} X_2=(X_{2,1}^T,\cdots,X_{2,n_2}^T)^T\in \mathbb{R}^{n_2\times p_2} X_3=(X_{3,1}^T,\cdots,X_{3,n_3}^T)^T\in \mathbb{R}^{n_3\times p_3} X_{i,j} Y_{i,j} p_i 14 ,24 ], 我们假定 X_1 X_2 X_3
Introduction to Spatial Econometrics
2
2009
... 网络数据是指用有向图或者无向图作为一种通用语言的数据, 在生活中也很普遍, 例如新冠病毒传播网络、基因网络、金融网络、交通网络、通话网络等. 对于网络数据的分析, 过去的研究主要是集中在对于网络结构的分析上. 对此, 学者们提出了许多模型来描述网络结构, 最初是对空间结构进行描述, 因而对于网络模型的构建是建立在空间模型的基础上. Ord[19 ] 提出了空间自回归 (SAR) 模型, 它研究了空间结构对于用户所产生的影响. 基于 SAR 模型, Anselin[1 ] 提出了空间杜宾模型, 该模型考虑了协变量与误差项的相关性, 之后相继提出了空间误差模型与 SAR 组合模型, LeSage 和 Pace[15 ] 从空间数据出发, 给出了更一般的空间自回归模型, 将上述模型都包含其中. ...
... 每一个类型的节点 i_1 ( {1\leqslant i_1 \leqslant n_1} ) , i_2 ( {1\leqslant i_2 \leqslant n_2} ) 或 i_3 ( {1\leqslant i_3 \leqslant n_3} ) 分别对应一个响应变量 Y_{1,i_1}, Y_{2,i_2} Y_{3,i_3} Y_1=(Y_{1,1},\cdots,Y_{1,n_1})^T, Y_2=(Y_{2,1},\cdots,Y_{2,n_2})^T Y_3=(Y_{3,1},\cdots,Y_{3,n_3})^T . 为了增强响应变量的解释能力, 我们借助 LeSage 和 Pace[15 ] 中对于不同类型的响应节点引入不同的外生协变量, 分别将类型 I、II 和 III 节点的外生变量定义如下: X_1=(X_{1,1}^T, \cdots,X_{1,n_1}^T)^T\in \mathbb{R}^{n_1\times p_1} X_2=(X_{2,1}^T,\cdots,X_{2,n_2}^T)^T\in \mathbb{R}^{n_2\times p_2} X_3=(X_{3,1}^T,\cdots,X_{3,n_3}^T)^T\in \mathbb{R}^{n_3\times p_3} X_{i,j} Y_{i,j} p_i 14 ,24 ], 我们假定 X_1 X_2 X_3
Recommendation as link prediction in bipartite graphs: A graph kernel-based machine learning approach
2
2013
... 但无论是分组 NAR 还是社区 NAR, 同一个组或者同一个社区中的节点之间只要存在边就会存在影响, 但实际中会存在同一类型的节点之间不存在直接相连的边, 只有不同类型的节点之间才会存在直接相连的边从而产生影响. 双模网络就是针对这种网络的简单情况而提出的, Borgatti 和Everett[2 ] 、Li 和 Chen[16 ] 、Cai 和 Liu[3 ] 等都观察到了双模网络结构, 如买家与卖家间的交易、选民与候选人间的投票、导演与演员间的合作等; 但以往的研究主要集中在分析网络结构上, 如: 基于双模网络 Everett 和Borgatti[8 ] 以及 D'Esposito[7 ] 等研究了可视化, Li 和 Chen[16 ] 以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
... [16 ]以及 Gao 和Chen[10 ] 研究了链路预测, Feng 等[9 ] 以及 Cai 和 Liu[3 ] 研究了社区检测等. 为了突破对双模网络结构的研究, 进一步研究双模网络中响应变量的依赖性, Huang 等[12 ] 从无向图视角提出了双模 NAR 模型, 首先利用传统网络估计方法--拟极大似然估计 (QMLE) 方法进行参数估计, 但是在 QMLE 计算过程中存在大规模矩阵行列式的计算, 计算量复杂, 进而采用了基于最优线性预测 (BLP) 的最小二乘估计 (LSE) 方法来提升计算效率, 并在不同情况下进行了数值模拟, 发现两种方法的估计性能都较高, 同时 LSE 的计算效率优于 QMLE 的计算效率. ...
Identification and efficient estimation of simultaneous equations network models
1
2014
... 其中假定 \varepsilon_1 \varepsilon_2 \varepsilon_3 {\rm Cov}(\varepsilon_1)=\sigma_1^{2}{\bf I}_{n_1} {\rm Cov}(\varepsilon_2)=\sigma_2^{2}{\bf I}_{n_2} {\rm Cov}(\varepsilon_3)=\sigma_3^{2}{\bf I}_{n_3} \textbf{I}_n\in \mathbb{R}^{n\times n}(n=n_1,n_2,n_3) \rho_{kl}({1\leqslant k\ne l \leqslant 3}) \rho_{12} \rho_{13} \rho_{21} \rho_{23} \rho_{31} \rho_{31} [17 ] 和 Cohen-Cole 等[6 ] , \beta_1 \beta_2 \beta_3
Semiparametric estimation and testing of smooth coefficient spatial autoregressive models
1
2017
... 为了研究网络结构对于用户所带来的影响, 基于 SAR 模型, Chen 等[5 ] 提出了网络自回归 (NAR) 模型. 随后, Zhu 等[26 ] 考虑了大规模社交网络中 NAR 模型, 并给出了 NAR 模型的平稳性. 已有的文献大多都假设 NAR 模型中各种节点之间是不存在差别的, 很少对节点的异质性进行考虑. 为了弱化这一假设, Malikov 和 Sun[18 ] 提出一种灵活的半参数 SAR 模型, 允许空间自回归参数在单元间变化, 从而允许变量识别特定社区的空间依赖性. Zhu 和 Pan[25 ] 基于 NAR 模型, 建立了分组 NAR 模型, 将网络个体划分不同的组, 不同组的 NAR 模型具有不同的参数; Chen 等[4 ] 提出了社区 NAR 模型, 基于拥有 N K
Estimation methods for models of spatial interaction
1
1975
... 网络数据是指用有向图或者无向图作为一种通用语言的数据, 在生活中也很普遍, 例如新冠病毒传播网络、基因网络、金融网络、交通网络、通话网络等. 对于网络数据的分析, 过去的研究主要是集中在对于网络结构的分析上. 对此, 学者们提出了许多模型来描述网络结构, 最初是对空间结构进行描述, 因而对于网络模型的构建是建立在空间模型的基础上. Ord[19 ] 提出了空间自回归 (SAR) 模型, 它研究了空间结构对于用户所产生的影响. 基于 SAR 模型, Anselin[1 ] 提出了空间杜宾模型, 该模型考虑了协变量与误差项的相关性, 之后相继提出了空间误差模型与 SAR 组合模型, LeSage 和 Pace[15 ] 从空间数据出发, 给出了更一般的空间自回归模型, 将上述模型都包含其中. ...
Using three social network analysis approaches to understand computer-supported collaborative learning
1
2021
... 在实际中, 不止存在双模网络数据, 还存在大量的三模网络数据, 即一个网络中存在三种类型的节点, 同类型节点不直接相连, 不同类型的节点之间才可以直接相连, Everett 和 Borgatti[8 ] 在文中提到过三模数据, 并指出了一个犯罪行为按受害者分类可以构成三模网络数据集. Fan[20 ] 在文中提到了一个三模数据, 即学生-话题- 知识网络, 包括三种数据类型: 学生、讨论话题、知识术语. 此外还存在其他三模数据, 如: 第三方平台中商家、顾客、配送员所构成的网络, 校园评价系统中学生、老师、家长所构成的网络等. 因此, 本文基于 Huang 等[12 ] 所提出的双模 NAR 模型进行拓展, 考虑了三模 NAR 模型. ...
1
2008
... 证 根据 Seber[21 ] , 为了确保 \textbf{I}_{N}-\textbf{W}_{\rho} |\lambda_{1}(\textbf{W}_{\rho})|<1 \lambda_{j}(W) W \in \mathbb{R}^{N \times N} j |\lambda_{1}(W)| \geq |\lambda_{2}(W)| \geq \cdots \geq |\lambda_{N}(W)| . 根据 Gerschgorin 圆盘定理, 若 \textbf{W}_{\rho} \lambda_{1}(W)
2
2017
... 采用拟极大似然法进行参数估计的时候, 需要计算 \textbf{I}_{N}-\textbf{W}_{\rho} N [22 ] 所提出的 BLP, Huang[11 ] 提出了一种基于 BLP 的最小二乘估计方法. 定义 \tilde{Y}_i=Y_i-\mu_i \tilde{Y}_{(-i)}=Y_{(-i)}-\mu_{(-i)} \mu_i=E(Y_i) Y_{(-i)}=\{Y_j:j\ne i,1 \leqslant j \leqslant N\} \mu_{(-i)}=E(Y_{(-i)}) . 在给定\tilde{Y}_{(-i)} \tilde{Y}_i \mathcal{N}_1 \mathcal{N}_2 \mathcal{N}_3
... 根据文献[22 ]得 ...
1
1996
... 根据 White[23 ] 的结论, 上式表明:\liminf\limits_{n \to \infty}\min\limits_{\theta \in \bar{B}_{\epsilon}(\theta_0)}\frac{\mathbb{Q}(\gamma)-\mathbb{Q}(\gamma_0)}{N} > 0, \bar{B}_{\epsilon}(\theta_0) \theta_0 \epsilon
Identification and QML estimation of multivariate and simultaneous equations spatial autoregressive models
2
2017
... 每一个类型的节点 i_1 ( {1\leqslant i_1 \leqslant n_1} ) , i_2 ( {1\leqslant i_2 \leqslant n_2} ) 或 i_3 ( {1\leqslant i_3 \leqslant n_3} ) 分别对应一个响应变量 Y_{1,i_1}, Y_{2,i_2} Y_{3,i_3} Y_1=(Y_{1,1},\cdots,Y_{1,n_1})^T, Y_2=(Y_{2,1},\cdots,Y_{2,n_2})^T Y_3=(Y_{3,1},\cdots,Y_{3,n_3})^T . 为了增强响应变量的解释能力, 我们借助 LeSage 和 Pace[15 ] 中对于不同类型的响应节点引入不同的外生协变量, 分别将类型 I、II 和 III 节点的外生变量定义如下: X_1=(X_{1,1}^T, \cdots,X_{1,n_1}^T)^T\in \mathbb{R}^{n_1\times p_1} X_2=(X_{2,1}^T,\cdots,X_{2,n_2}^T)^T\in \mathbb{R}^{n_2\times p_2} X_3=(X_{3,1}^T,\cdots,X_{3,n_3}^T)^T\in \mathbb{R}^{n_3\times p_3} X_{i,j} Y_{i,j} p_i 14 ,24 ], 我们假定 X_1 X_2 X_3
... 为了建立 LSE 估计的渐近正态性, 首先需要参数的可识别性. 利用 Yang 和 Lee[24 ] SAR 模型参数可识别性的方法计算最小二乘目标函数的期望, 从而建立参数的可识别性. ...
Grouped network vector autoregression
1
2020
... 为了研究网络结构对于用户所带来的影响, 基于 SAR 模型, Chen 等[5 ] 提出了网络自回归 (NAR) 模型. 随后, Zhu 等[26 ] 考虑了大规模社交网络中 NAR 模型, 并给出了 NAR 模型的平稳性. 已有的文献大多都假设 NAR 模型中各种节点之间是不存在差别的, 很少对节点的异质性进行考虑. 为了弱化这一假设, Malikov 和 Sun[18 ] 提出一种灵活的半参数 SAR 模型, 允许空间自回归参数在单元间变化, 从而允许变量识别特定社区的空间依赖性. Zhu 和 Pan[25 ] 基于 NAR 模型, 建立了分组 NAR 模型, 将网络个体划分不同的组, 不同组的 NAR 模型具有不同的参数; Chen 等[4 ] 提出了社区 NAR 模型, 基于拥有 N K
Network vector autoregression
1
2017
... 为了研究网络结构对于用户所带来的影响, 基于 SAR 模型, Chen 等[5 ] 提出了网络自回归 (NAR) 模型. 随后, Zhu 等[26 ] 考虑了大规模社交网络中 NAR 模型, 并给出了 NAR 模型的平稳性. 已有的文献大多都假设 NAR 模型中各种节点之间是不存在差别的, 很少对节点的异质性进行考虑. 为了弱化这一假设, Malikov 和 Sun[18 ] 提出一种灵活的半参数 SAR 模型, 允许空间自回归参数在单元间变化, 从而允许变量识别特定社区的空间依赖性. Zhu 和 Pan[25 ] 基于 NAR 模型, 建立了分组 NAR 模型, 将网络个体划分不同的组, 不同组的 NAR 模型具有不同的参数; Chen 等[4 ] 提出了社区 NAR 模型, 基于拥有 N K




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}