磁共振成像机遇和挑战——中国十年来发展成果及展望
1
2022
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
磁共振成像机遇和挑战——中国十年来发展成果及展望
1
2022
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
A digital signal processor-based pulse programmer with performance of run-time information handling for magnetic resonance imaging
6
2015
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... 针对以上设计中存在的问题,2015年,Xiao等[2]基于DSP(TMS320VC33)和FPGA(EP2C8Q208)设计了一个梯度波形时间分辨率达到1 μs的谱仪,其梯度波形发生器的结构框图见图6. 通过网络接口模块中的以太网将来自PC机的参数与波形数据传输到DSP的片上存储器,DSP经外部总线连接梯度生成模块的FPGA,并预先为FPGA配置数据和参数,FPGA根据给定的配置进行梯度计算(包括矩阵乘法、预加重和一阶匀场),其计算结果发送到三个数模转换器(DAC),最终生成并输出梯度波形. DSP软件部分采用汇编语言编写,DSP可通过读取状态端口获取运行时的详细信息,当发生如梯度计算溢出之类的异常时,DSP停止成像处理并立即执行相应的服务子程序. 在此设计中,DSP采用汇编语言编写,编写较为简单,且提供32条控制线,具有强大的控制能力. ...
... 基于DSP与FPGA结合的梯度波形发生器结构框图(根据文献[
2]绘制)
Block diagram of gradient waveform generator based on DSP and FPGA (Reproduced from Ref.[<xref ref-type="bibr" rid="b2">2</xref>])Fig. 6 Xiao等[2]将其与谱仪的其他部件如功率放大器、射频线圈等组合后,连接至0.35 T永磁MRI系统进行人体成像实验,并采用Matlab软件进行图像重建,使用T1加权自旋回波(T1-SE)序列对人脑进行多层成像,结果如图7所示. 成像结果表明此梯度波形发生器具有良好的性能,能对人体清晰成像,且适用于临床. ...
... Block diagram of gradient waveform generator based on DSP and FPGA (Reproduced from Ref.[
2])
Fig. 6 Xiao等[2]将其与谱仪的其他部件如功率放大器、射频线圈等组合后,连接至0.35 T永磁MRI系统进行人体成像实验,并采用Matlab软件进行图像重建,使用T1加权自旋回波(T1-SE)序列对人脑进行多层成像,结果如图7所示. 成像结果表明此梯度波形发生器具有良好的性能,能对人体清晰成像,且适用于临床. ...
... Xiao等[2]将其与谱仪的其他部件如功率放大器、射频线圈等组合后,连接至0.35 T永磁MRI系统进行人体成像实验,并采用Matlab软件进行图像重建,使用T1加权自旋回波(T1-SE)序列对人脑进行多层成像,结果如图7所示. 成像结果表明此梯度波形发生器具有良好的性能,能对人体清晰成像,且适用于临床. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
A compact and high-precision gradient waveform generator using an FPGA device for magnetic resonance imaging
7
2022
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... [3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... 梯度磁场发生单元硬件结构框图(根据文献[
3,
5,
6]绘制)
Hardware structure diagram of gradient magnetic field generation unit (Reproduced from Ref.[<xref ref-type="bibr" rid="b3">3</xref>,<xref ref-type="bibr" rid="b5">5</xref>,<xref ref-type="bibr" rid="b6">6</xref>])Fig. 1 梯度波形发生器的性能直接影响最终成像的质量,它不仅从扫描速度上,也从空间分辨率上限制着整个MRI系统性能的改善. 本文第一部分将围绕梯度波形发生器,分别探讨基于数字信号处理器(Digital Signal Processor,DSP)、现场可编程门阵列(Field Programmable Gate Array,FPGA)及将两者结合设计的梯度波形发生器相关研究进展,集中对各梯度波形发生器与上位机的通信方式,数字信号的处理能力,板载存储器容量及DAC等进行介绍与讨论,并比较不同实现方法的优劣. 本文第二部分详细介绍消除及减弱涡流影响的方法,主要分析并讨论模拟预加重及数字预加重这两种方法的实现. 最后对梯度波形发生器未来的发展方向进行展望. ...
... Hardware structure diagram of gradient magnetic field generation unit (Reproduced from Ref.[
3,
5,
6])
Fig. 1 梯度波形发生器的性能直接影响最终成像的质量,它不仅从扫描速度上,也从空间分辨率上限制着整个MRI系统性能的改善. 本文第一部分将围绕梯度波形发生器,分别探讨基于数字信号处理器(Digital Signal Processor,DSP)、现场可编程门阵列(Field Programmable Gate Array,FPGA)及将两者结合设计的梯度波形发生器相关研究进展,集中对各梯度波形发生器与上位机的通信方式,数字信号的处理能力,板载存储器容量及DAC等进行介绍与讨论,并比较不同实现方法的优劣. 本文第二部分详细介绍消除及减弱涡流影响的方法,主要分析并讨论模拟预加重及数字预加重这两种方法的实现. 最后对梯度波形发生器未来的发展方向进行展望. ...
... 2022年,Xing等[3]选用低成本FPGA芯片EP2C35F484,在Quartus II软件中采用VHDL编译,研发出一款输出数据精度为24 bit,时间分辨率达到1 μs的紧凑型高精度梯度波形发生器. 在系统初始化时期,序列控制器通过双向数据总线将梯度波形数据及梯度计算参数(如时间分辨率、矩阵系数)预加载到FPGA内嵌的随机存取存储器(RAM)中,当FPGA接收到触发信号后,从RAM中周期性地读出梯度波形数据,由FPGA对原始数据进行坐标变换及直流偏置等梯度运算,最终进入DAC转换得到梯度波形. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
... 梯度波形预加重法相较于前两者具有诸多优点,它体积小,设计制作成本低,也无需考虑磁极空间的占用问题,目前较多研发人员选择梯度波形预加重法来消除或减弱涡流的影响. 涡流产生的磁场是多个指数衰减时间常数及其对应的幅度常数的叠加,根据涡流的电感-电阻(LR)电路模型,磁场中感应的涡流场可以表示为(1)式,其中Ai和Ti分别为涡流衰减的时间常数和幅度常数,m是所包含的涡流环的数量[3]. 通过调整时间常数和相应的幅度常数,能使预加重单元更好地克服梯度涡流对MRI图像的影响. ...
1
2000
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
Implementation of MRI gradient generation system and controller on field programmable gate array (FPGA)
8
2018
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... ,
5,
6]绘制)
Hardware structure diagram of gradient magnetic field generation unit (Reproduced from Ref.[<xref ref-type="bibr" rid="b3">3</xref>,<xref ref-type="bibr" rid="b5">5</xref>,<xref ref-type="bibr" rid="b6">6</xref>])Fig. 1 梯度波形发生器的性能直接影响最终成像的质量,它不仅从扫描速度上,也从空间分辨率上限制着整个MRI系统性能的改善. 本文第一部分将围绕梯度波形发生器,分别探讨基于数字信号处理器(Digital Signal Processor,DSP)、现场可编程门阵列(Field Programmable Gate Array,FPGA)及将两者结合设计的梯度波形发生器相关研究进展,集中对各梯度波形发生器与上位机的通信方式,数字信号的处理能力,板载存储器容量及DAC等进行介绍与讨论,并比较不同实现方法的优劣. 本文第二部分详细介绍消除及减弱涡流影响的方法,主要分析并讨论模拟预加重及数字预加重这两种方法的实现. 最后对梯度波形发生器未来的发展方向进行展望. ...
... ,
5,
6])
Fig. 1 梯度波形发生器的性能直接影响最终成像的质量,它不仅从扫描速度上,也从空间分辨率上限制着整个MRI系统性能的改善. 本文第一部分将围绕梯度波形发生器,分别探讨基于数字信号处理器(Digital Signal Processor,DSP)、现场可编程门阵列(Field Programmable Gate Array,FPGA)及将两者结合设计的梯度波形发生器相关研究进展,集中对各梯度波形发生器与上位机的通信方式,数字信号的处理能力,板载存储器容量及DAC等进行介绍与讨论,并比较不同实现方法的优劣. 本文第二部分详细介绍消除及减弱涡流影响的方法,主要分析并讨论模拟预加重及数字预加重这两种方法的实现. 最后对梯度波形发生器未来的发展方向进行展望. ...
... 2018年,Kumar等[5]使用Vivado设计了由Microblaze软核处理器、梯度波形合成器、DAC及定时信号生成单元的知识产权(intellectual property,IP)核组成的梯度波形发生器. 该系统通过传输控制协议/网际协议(Transmission Control Protocol/Internet Protocol,TCP/IP)与个人电脑(Personal Computer,PC)通信,系统架构如图3所示. 其中,Microblaze软核处理器是一个经FPGA优化的高度可重构IP核. 形成身体特定部位的高对比度图像所需的梯度波形和相位样本位于脉冲文件中,该文件由第三方软件转换为TCP/IP数据包.TCP/IP数据包通过以太网从PC传输至MicroBlaze软核处理器,由MicroBlaze软核处理器执行数据解码、数据识别分离等处理后,通过高级可扩展接口(Advanced eXtensible Interface,AXI)提供给梯度波形合成器并滤波,由串行外设接口(Serial Peripheral interface,SPI)以1~2 MSPS(Million Samples per Second)速率将处理后的梯度样本传输到DAC模块,最终DAC模块以1 MSPS的速率生成梯度波形信号.DAC采样的产生由定时信号触发单元控制,定时信号触发单元在脉冲文件中指定的偏移之后产生触发信号,从而精确地产生梯度信号. ...
... [
5]
Block diagram of gradient waveform generator based on FPGA design scheme<sup>[<xref ref-type="bibr" rid="b5">5</xref>]</sup>Fig. 3 实现新的MRI序列既耗时又昂贵[29],Kumar等[5]将梯度波形和相位样本放置在脉冲文件中并统一转化为数据包的设计能以最小的代价指定各种序列,并且能够快速部署到硬件. 此外,由于梯度样本的生成速率较低,而FPGA处理速度快,因此无需生成整个梯度样本,从而节省FPGA资源并减少梯度波形生成总时间. 但在此设计中,具体采用的FPGA、DAC型号并未说明. 并且,梯度波形发生器DAC为1 MSPS,但此系统未在梯度波形发生器的输出端设置中间缓冲区,故队列为空的概率较高. ...
... [
5]
Fig. 3 实现新的MRI序列既耗时又昂贵[29],Kumar等[5]将梯度波形和相位样本放置在脉冲文件中并统一转化为数据包的设计能以最小的代价指定各种序列,并且能够快速部署到硬件. 此外,由于梯度样本的生成速率较低,而FPGA处理速度快,因此无需生成整个梯度样本,从而节省FPGA资源并减少梯度波形生成总时间. 但在此设计中,具体采用的FPGA、DAC型号并未说明. 并且,梯度波形发生器DAC为1 MSPS,但此系统未在梯度波形发生器的输出端设置中间缓冲区,故队列为空的概率较高. ...
... 实现新的MRI序列既耗时又昂贵[29],Kumar等[5]将梯度波形和相位样本放置在脉冲文件中并统一转化为数据包的设计能以最小的代价指定各种序列,并且能够快速部署到硬件. 此外,由于梯度样本的生成速率较低,而FPGA处理速度快,因此无需生成整个梯度样本,从而节省FPGA资源并减少梯度波形生成总时间. 但在此设计中,具体采用的FPGA、DAC型号并未说明. 并且,梯度波形发生器DAC为1 MSPS,但此系统未在梯度波形发生器的输出端设置中间缓冲区,故队列为空的概率较高. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
一种基于高性能DSP的MRI梯度计算模块设计
4
2011
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... ,
6]绘制)
Hardware structure diagram of gradient magnetic field generation unit (Reproduced from Ref.[<xref ref-type="bibr" rid="b3">3</xref>,<xref ref-type="bibr" rid="b5">5</xref>,<xref ref-type="bibr" rid="b6">6</xref>])Fig. 1 梯度波形发生器的性能直接影响最终成像的质量,它不仅从扫描速度上,也从空间分辨率上限制着整个MRI系统性能的改善. 本文第一部分将围绕梯度波形发生器,分别探讨基于数字信号处理器(Digital Signal Processor,DSP)、现场可编程门阵列(Field Programmable Gate Array,FPGA)及将两者结合设计的梯度波形发生器相关研究进展,集中对各梯度波形发生器与上位机的通信方式,数字信号的处理能力,板载存储器容量及DAC等进行介绍与讨论,并比较不同实现方法的优劣. 本文第二部分详细介绍消除及减弱涡流影响的方法,主要分析并讨论模拟预加重及数字预加重这两种方法的实现. 最后对梯度波形发生器未来的发展方向进行展望. ...
... ,
6])
Fig. 1 梯度波形发生器的性能直接影响最终成像的质量,它不仅从扫描速度上,也从空间分辨率上限制着整个MRI系统性能的改善. 本文第一部分将围绕梯度波形发生器,分别探讨基于数字信号处理器(Digital Signal Processor,DSP)、现场可编程门阵列(Field Programmable Gate Array,FPGA)及将两者结合设计的梯度波形发生器相关研究进展,集中对各梯度波形发生器与上位机的通信方式,数字信号的处理能力,板载存储器容量及DAC等进行介绍与讨论,并比较不同实现方法的优劣. 本文第二部分详细介绍消除及减弱涡流影响的方法,主要分析并讨论模拟预加重及数字预加重这两种方法的实现. 最后对梯度波形发生器未来的发展方向进行展望. ...
... 自2000年起,不断有研究人员在梯度波形数字预加重设计中提供新方法. 2007年,Liu等[58]使用PC机通过PCI总线配置在FPGA内部构建的寄存器,用以改变预加重的时间与幅度常数,但预加重的通道仅有三路,对梯度涡流的补偿不足. 2008年,Zang等[59]提出利用MR信号测量涡流后,经过拟合、迭代寻找最佳涡流补偿参数的方法,但是该方法首先得确定样品信号区,需要耗时10 min才能得到较好的预加重补偿效果. 2010年,Xiao等[24]采取在FPGA内部使用快速无限冲激响应滤波器(Infinite Impulse Response Filter,IIR)滤波器算法对原始梯度波形叠加过驱动的方法,实现对涡流的预加重处理,但随着迭代次数增加,累计误差也逐渐增加. 2011年,Pan等[6]针对Xiao等[24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
一种基于高性能DSP的MRI梯度计算模块设计
4
2011
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... ,
6]绘制)
Hardware structure diagram of gradient magnetic field generation unit (Reproduced from Ref.[<xref ref-type="bibr" rid="b3">3</xref>,<xref ref-type="bibr" rid="b5">5</xref>,<xref ref-type="bibr" rid="b6">6</xref>])Fig. 1 梯度波形发生器的性能直接影响最终成像的质量,它不仅从扫描速度上,也从空间分辨率上限制着整个MRI系统性能的改善. 本文第一部分将围绕梯度波形发生器,分别探讨基于数字信号处理器(Digital Signal Processor,DSP)、现场可编程门阵列(Field Programmable Gate Array,FPGA)及将两者结合设计的梯度波形发生器相关研究进展,集中对各梯度波形发生器与上位机的通信方式,数字信号的处理能力,板载存储器容量及DAC等进行介绍与讨论,并比较不同实现方法的优劣. 本文第二部分详细介绍消除及减弱涡流影响的方法,主要分析并讨论模拟预加重及数字预加重这两种方法的实现. 最后对梯度波形发生器未来的发展方向进行展望. ...
... ,
6])
Fig. 1 梯度波形发生器的性能直接影响最终成像的质量,它不仅从扫描速度上,也从空间分辨率上限制着整个MRI系统性能的改善. 本文第一部分将围绕梯度波形发生器,分别探讨基于数字信号处理器(Digital Signal Processor,DSP)、现场可编程门阵列(Field Programmable Gate Array,FPGA)及将两者结合设计的梯度波形发生器相关研究进展,集中对各梯度波形发生器与上位机的通信方式,数字信号的处理能力,板载存储器容量及DAC等进行介绍与讨论,并比较不同实现方法的优劣. 本文第二部分详细介绍消除及减弱涡流影响的方法,主要分析并讨论模拟预加重及数字预加重这两种方法的实现. 最后对梯度波形发生器未来的发展方向进行展望. ...
... 自2000年起,不断有研究人员在梯度波形数字预加重设计中提供新方法. 2007年,Liu等[58]使用PC机通过PCI总线配置在FPGA内部构建的寄存器,用以改变预加重的时间与幅度常数,但预加重的通道仅有三路,对梯度涡流的补偿不足. 2008年,Zang等[59]提出利用MR信号测量涡流后,经过拟合、迭代寻找最佳涡流补偿参数的方法,但是该方法首先得确定样品信号区,需要耗时10 min才能得到较好的预加重补偿效果. 2010年,Xiao等[24]采取在FPGA内部使用快速无限冲激响应滤波器(Infinite Impulse Response Filter,IIR)滤波器算法对原始梯度波形叠加过驱动的方法,实现对涡流的预加重处理,但随着迭代次数增加,累计误差也逐渐增加. 2011年,Pan等[6]针对Xiao等[24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
基于DSP技术的梯度波形发生器
6
2009
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... Dai等[7]采用德州仪器公司的32位(bit)通用浮点DSP芯片TMS320C6713B为核心,基于外设部件互连(Peripheral Component Interconnect,PCI)总线设计了梯度波形发生器. 此DSP主要负责采集触发信号及计算预加重,当DSP采集到触发信号后,将存储在32 MB外接同步动态随机存储器(Synchronous Dynamic Random Access Memory,SDRAM)中的梯度波形数据(选层梯度、相位编码梯度及频率编码梯度数据)进行预加重计算后,由复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)进行并串转换后送至DAC,而后使用电流/电压转换器进行转换以满足后级电路的需求,最后还运用单端转差分电路以达到抑制共模噪声及高频噪声的目的. 此设计的硬件结构框图如图2所示. 选用的DAC为TI公司的PCM1704,群延时小(<2 μs)且具有24 bit位宽. 将此梯度波形发生器集成到自研发的0.3 T永磁开放式MRI,结果表明能对人体头部进行清晰地成像. 采用浮点DSP通常需使用最小32 bit存储各个数值,则所有总线及寄存器均需采用32 bit,此类DSP内部结构复杂,且要求乘法器和算术逻辑运算单元(Arithmetic Logic Unit,ALU)运算能力强大,一定程度上限制了系统的改进. 此外,该设计使用单片DSP实现,相较使用FPGA开发而言,灵活性、可扩展性与运算速度略显不足[23],实时性较差[24]. ...
... [
7]
Block diagram of gradient waveform generator based on DSP design scheme<sup>[<xref ref-type="bibr" rid="b7">7</xref>]</sup>Fig. 2 1.2.2 基于FPGA的设计方案FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
... [
7]
Fig. 2 1.2.2 基于FPGA的设计方案FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
... 大多数情况下,梯度波形预加重至少要提供4组预加重参数. 梯度波形预加重的主要指标是时间常数与幅度常数,传统采用滑动变阻器设计模拟预加重的方法已逐步被淘汰,而采用数字电位器,相比使用滑动变阻器的方法而言具有可重复性强、受环境影响小及精度高的优点. 但数字电位器的数据字除包含数据位,还包含地址位和指令位,能够设置的预加重参数范围有限. 此外,虽然不同的电位器内部结构不同,但均可根据电路结构计算时间常数和幅度常数,即时间常数及幅度常数的取值由电路结构及其包含的元器件直接决定,能取的值十分有限. 数字预加重的使用能提高预加重的精度,且能灵活扩展预加重参数的个数并缩短预加重耗时. 但一方面,数字预加重对进行梯度预加重计算的芯片资源要求较高,因为梯度预加重通常需要做到至少4组预加重参数,但若DSP或FPGA等芯片本身资源已被梯度波形发生器高度利用,则无法具有充足资源用于生成足够降低涡流的预加重参数. 另一方面,数字预加重的引入会导致梯度波形的幅度抖动与时间抖动,可能导致成像的伪影及梯度波形输出的延迟. 此外,原始波形数据需要经过梯度计算等处理后进入DAC,而数字预加重会占用1~2 bit DAC位数[7],导致梯度波形发生器输出的波形分辨率降低[63,64]. 而模拟预加重是对DAC输出的梯度波形进行预加重处理,不占用DAC的位数,故模拟预加重也有其一定的优势. ...
基于DSP技术的梯度波形发生器
6
2009
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... Dai等[7]采用德州仪器公司的32位(bit)通用浮点DSP芯片TMS320C6713B为核心,基于外设部件互连(Peripheral Component Interconnect,PCI)总线设计了梯度波形发生器. 此DSP主要负责采集触发信号及计算预加重,当DSP采集到触发信号后,将存储在32 MB外接同步动态随机存储器(Synchronous Dynamic Random Access Memory,SDRAM)中的梯度波形数据(选层梯度、相位编码梯度及频率编码梯度数据)进行预加重计算后,由复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)进行并串转换后送至DAC,而后使用电流/电压转换器进行转换以满足后级电路的需求,最后还运用单端转差分电路以达到抑制共模噪声及高频噪声的目的. 此设计的硬件结构框图如图2所示. 选用的DAC为TI公司的PCM1704,群延时小(<2 μs)且具有24 bit位宽. 将此梯度波形发生器集成到自研发的0.3 T永磁开放式MRI,结果表明能对人体头部进行清晰地成像. 采用浮点DSP通常需使用最小32 bit存储各个数值,则所有总线及寄存器均需采用32 bit,此类DSP内部结构复杂,且要求乘法器和算术逻辑运算单元(Arithmetic Logic Unit,ALU)运算能力强大,一定程度上限制了系统的改进. 此外,该设计使用单片DSP实现,相较使用FPGA开发而言,灵活性、可扩展性与运算速度略显不足[23],实时性较差[24]. ...
... [
7]
Block diagram of gradient waveform generator based on DSP design scheme<sup>[<xref ref-type="bibr" rid="b7">7</xref>]</sup>Fig. 2 1.2.2 基于FPGA的设计方案FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
... [
7]
Fig. 2 1.2.2 基于FPGA的设计方案FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
... 大多数情况下,梯度波形预加重至少要提供4组预加重参数. 梯度波形预加重的主要指标是时间常数与幅度常数,传统采用滑动变阻器设计模拟预加重的方法已逐步被淘汰,而采用数字电位器,相比使用滑动变阻器的方法而言具有可重复性强、受环境影响小及精度高的优点. 但数字电位器的数据字除包含数据位,还包含地址位和指令位,能够设置的预加重参数范围有限. 此外,虽然不同的电位器内部结构不同,但均可根据电路结构计算时间常数和幅度常数,即时间常数及幅度常数的取值由电路结构及其包含的元器件直接决定,能取的值十分有限. 数字预加重的使用能提高预加重的精度,且能灵活扩展预加重参数的个数并缩短预加重耗时. 但一方面,数字预加重对进行梯度预加重计算的芯片资源要求较高,因为梯度预加重通常需要做到至少4组预加重参数,但若DSP或FPGA等芯片本身资源已被梯度波形发生器高度利用,则无法具有充足资源用于生成足够降低涡流的预加重参数. 另一方面,数字预加重的引入会导致梯度波形的幅度抖动与时间抖动,可能导致成像的伪影及梯度波形输出的延迟. 此外,原始波形数据需要经过梯度计算等处理后进入DAC,而数字预加重会占用1~2 bit DAC位数[7],导致梯度波形发生器输出的波形分辨率降低[63,64]. 而模拟预加重是对DAC输出的梯度波形进行预加重处理,不占用DAC的位数,故模拟预加重也有其一定的优势. ...
一体化NMR波谱仪梯度-场频联锁-匀场系统设计
2
2012
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... 2012年,Wang等[8]选用8片Microchip公司生产的数控电位器MCP41010设计了4组预加重电路,数控电位器的触点位置由梯度波形发生器经过SPI向它发送数据改变,从而改变其某两端的电阻值,最终更改预加重的参数. 每组预加重电路具有两片MCP41010,一片用于改变时间常数,另一片用于改变幅度常数. 基于其结合了数控电位器、电压跟随器与微分电路的电路设计,时间常数与幅度常数均能取256个不同的取值,可通过控制字的设定分别或同时调节时间常数和幅度常数. 此设计解决了传统预加重电路容易受温、湿度等环境影响的问题,在时间常数与幅度常数的调节灵活性上也有所提升. ...
一体化NMR波谱仪梯度-场频联锁-匀场系统设计
2
2012
... 磁共振成像(Magnetic Resonance Imaging,MRI)以其高软组织分辨率、多参数、非侵入性、无辐射[1]和成像模式灵活等优点,已成为临床成像的主流技术[2]. 在MRI系统中,梯度磁场沿三个正交方向X、Y、Z呈线性变化,主磁场与线性梯度磁场叠加后,样品中不同位置就有不同的共振频率,因此可以利用梯度磁场来确定空间位置[3]. 磁共振系统由磁体、梯度、射频、计算机和图像处理等子系统组成[4],其中,梯度子系统用于产生梯度磁场,它由梯度波形发生器、梯度放大器及梯度线圈组成. 梯度磁场的产生由上位机发送梯度数据至梯度波形发生器,梯度波形发生器按照一定时序将X、Y、Z三路梯度数据经过计算及分流后送至数模转换器(Digital to Analog Converter,DAC)转换为模拟信号,然后模拟信号发送到梯度放大器进行信号放大,最终反馈至梯度线圈产生梯度磁场[3,5,6],梯度磁场发生单元硬件结构见图1. 其中,梯度波形发生器通常由梯度计算模块、DAC模块、存储器模块及外围设备组成. 梯度波形发生器是MRI系统的关键组成部分,其主要功能是实现梯度数据的计算(如矩阵计算、预加重计算及一阶匀场),将预存在梯度波形发生器存储器中的原始波形数据转换为模拟梯度信号,最终产生用以选层编码、相位编码和频率编码的三路梯度[7,8]. ...
... 2012年,Wang等[8]选用8片Microchip公司生产的数控电位器MCP41010设计了4组预加重电路,数控电位器的触点位置由梯度波形发生器经过SPI向它发送数据改变,从而改变其某两端的电阻值,最终更改预加重的参数. 每组预加重电路具有两片MCP41010,一片用于改变时间常数,另一片用于改变幅度常数. 基于其结合了数控电位器、电压跟随器与微分电路的电路设计,时间常数与幅度常数均能取256个不同的取值,可通过控制字的设定分别或同时调节时间常数和幅度常数. 此设计解决了传统预加重电路容易受温、湿度等环境影响的问题,在时间常数与幅度常数的调节灵活性上也有所提升. ...
一种通用的核磁共振微成像系统
1
2000
... 早期多由PC机直接生成任意波形函数的数据,然后由DAC将波形数据转换成模拟信号[9],此类设计集成度差,能产生的梯度波形有限且受周边环境影响大. MRI设备具有无创、软组织分辨率高且可任意断面成像等显著优点,与此同时,数字电路与集成电路的不断发展给MRI设备提供了更多优化的可能,越来越多的科研人员投身MRI研究中,这也使梯度波形发生器能够朝更高集成度、高精度和高稳定度的方向稳步发展[10]. ...
一种通用的核磁共振微成像系统
1
2000
... 早期多由PC机直接生成任意波形函数的数据,然后由DAC将波形数据转换成模拟信号[9],此类设计集成度差,能产生的梯度波形有限且受周边环境影响大. MRI设备具有无创、软组织分辨率高且可任意断面成像等显著优点,与此同时,数字电路与集成电路的不断发展给MRI设备提供了更多优化的可能,越来越多的科研人员投身MRI研究中,这也使梯度波形发生器能够朝更高集成度、高精度和高稳定度的方向稳步发展[10]. ...
一种具有数字预加重的磁共振成像梯度波形发生器
1
2006
... 早期多由PC机直接生成任意波形函数的数据,然后由DAC将波形数据转换成模拟信号[9],此类设计集成度差,能产生的梯度波形有限且受周边环境影响大. MRI设备具有无创、软组织分辨率高且可任意断面成像等显著优点,与此同时,数字电路与集成电路的不断发展给MRI设备提供了更多优化的可能,越来越多的科研人员投身MRI研究中,这也使梯度波形发生器能够朝更高集成度、高精度和高稳定度的方向稳步发展[10]. ...
一种具有数字预加重的磁共振成像梯度波形发生器
1
2006
... 早期多由PC机直接生成任意波形函数的数据,然后由DAC将波形数据转换成模拟信号[9],此类设计集成度差,能产生的梯度波形有限且受周边环境影响大. MRI设备具有无创、软组织分辨率高且可任意断面成像等显著优点,与此同时,数字电路与集成电路的不断发展给MRI设备提供了更多优化的可能,越来越多的科研人员投身MRI研究中,这也使梯度波形发生器能够朝更高集成度、高精度和高稳定度的方向稳步发展[10]. ...
Comparison study of hardware architectures performance between FPGA and DSP processors for implementing digital signal processing algorithms: Application of FIR digital filter
2
2022
... 设计梯度波形发生器时主要关注其集成度、主时钟频率、板载存储器的容量、数据传输速率及梯度计算时数据的精度等问题. 其中,集成度决定了梯度波形发生器的尺寸,主时钟频率决定了是否能将应用程序的采样率与硬件的时钟频率相匹配,及各模块的工作频率范围[11],板载存储器的容量决定了产生的梯度波形数目及复杂程度,数据传输速率决定了系统整体耗时,梯度计算时数据的精度影响最终波形的质量. 梯度波形发生器的主要指标是梯度波形的线性度及上升时间[12]. 其中,梯度波形的线性度由DAC的位宽决定,更高的DAC位宽能使得线性度更高. 梯度波形的线性度是衡量梯度磁场平稳性的指标,线性度好代表着梯度磁场在空间中的变化精细,故线性度越好则图像质量就越好[13,14]. 梯度波形的上升时间由DAC的采样率决定,更高的DAC采样率能使得上升时间更短,梯度上升快可进一步加快扫描速度. 由此可见,DAC的选型对梯度波形发生器的设计至关重要. 在梯度波形发生器中,由DAC模块将原始梯度波形数据转换成模拟梯度信号,在选择DAC模块时主要关注其位宽、采样率、群延时等. ...
... DSP采用改进的哈佛总线结构[15],使用时主要使用其乘法与累加(Multiply Accumulate,MAC)功能[16],它可以轻松访问大量输入输出信号,也可以使用超长指令字的方法在一个时钟冲程中执行复杂计算. DSP一般采用C语言编程,擅长顺序执行,开发时间短,尤其是对于先进的控制技术.FPGA主要由基本可编程逻辑单元(Configurable Logic Blocks,CLB)、可编程输入输出单元(Input Output Block,IOB)、嵌入式块随机存储器(Random Access Memory,RAM)组成,采用硬件描述语言Verilog HDL(Hardware Description Language)或VHDL(VHSIC Hardware Description Language)对数字电路或系统进行设计与描述.DSP和FPGA的体系结构使它们能够有效地完成运算与控制,并确保数据具有良好的数值精度[11]. ...
1
2009
... 设计梯度波形发生器时主要关注其集成度、主时钟频率、板载存储器的容量、数据传输速率及梯度计算时数据的精度等问题. 其中,集成度决定了梯度波形发生器的尺寸,主时钟频率决定了是否能将应用程序的采样率与硬件的时钟频率相匹配,及各模块的工作频率范围[11],板载存储器的容量决定了产生的梯度波形数目及复杂程度,数据传输速率决定了系统整体耗时,梯度计算时数据的精度影响最终波形的质量. 梯度波形发生器的主要指标是梯度波形的线性度及上升时间[12]. 其中,梯度波形的线性度由DAC的位宽决定,更高的DAC位宽能使得线性度更高. 梯度波形的线性度是衡量梯度磁场平稳性的指标,线性度好代表着梯度磁场在空间中的变化精细,故线性度越好则图像质量就越好[13,14]. 梯度波形的上升时间由DAC的采样率决定,更高的DAC采样率能使得上升时间更短,梯度上升快可进一步加快扫描速度. 由此可见,DAC的选型对梯度波形发生器的设计至关重要. 在梯度波形发生器中,由DAC模块将原始梯度波形数据转换成模拟梯度信号,在选择DAC模块时主要关注其位宽、采样率、群延时等. ...
永磁微型磁共振成像仪的梯度线圈与图像质量
1
2012
... 设计梯度波形发生器时主要关注其集成度、主时钟频率、板载存储器的容量、数据传输速率及梯度计算时数据的精度等问题. 其中,集成度决定了梯度波形发生器的尺寸,主时钟频率决定了是否能将应用程序的采样率与硬件的时钟频率相匹配,及各模块的工作频率范围[11],板载存储器的容量决定了产生的梯度波形数目及复杂程度,数据传输速率决定了系统整体耗时,梯度计算时数据的精度影响最终波形的质量. 梯度波形发生器的主要指标是梯度波形的线性度及上升时间[12]. 其中,梯度波形的线性度由DAC的位宽决定,更高的DAC位宽能使得线性度更高. 梯度波形的线性度是衡量梯度磁场平稳性的指标,线性度好代表着梯度磁场在空间中的变化精细,故线性度越好则图像质量就越好[13,14]. 梯度波形的上升时间由DAC的采样率决定,更高的DAC采样率能使得上升时间更短,梯度上升快可进一步加快扫描速度. 由此可见,DAC的选型对梯度波形发生器的设计至关重要. 在梯度波形发生器中,由DAC模块将原始梯度波形数据转换成模拟梯度信号,在选择DAC模块时主要关注其位宽、采样率、群延时等. ...
永磁微型磁共振成像仪的梯度线圈与图像质量
1
2012
... 设计梯度波形发生器时主要关注其集成度、主时钟频率、板载存储器的容量、数据传输速率及梯度计算时数据的精度等问题. 其中,集成度决定了梯度波形发生器的尺寸,主时钟频率决定了是否能将应用程序的采样率与硬件的时钟频率相匹配,及各模块的工作频率范围[11],板载存储器的容量决定了产生的梯度波形数目及复杂程度,数据传输速率决定了系统整体耗时,梯度计算时数据的精度影响最终波形的质量. 梯度波形发生器的主要指标是梯度波形的线性度及上升时间[12]. 其中,梯度波形的线性度由DAC的位宽决定,更高的DAC位宽能使得线性度更高. 梯度波形的线性度是衡量梯度磁场平稳性的指标,线性度好代表着梯度磁场在空间中的变化精细,故线性度越好则图像质量就越好[13,14]. 梯度波形的上升时间由DAC的采样率决定,更高的DAC采样率能使得上升时间更短,梯度上升快可进一步加快扫描速度. 由此可见,DAC的选型对梯度波形发生器的设计至关重要. 在梯度波形发生器中,由DAC模块将原始梯度波形数据转换成模拟梯度信号,在选择DAC模块时主要关注其位宽、采样率、群延时等. ...
1
2018
... 设计梯度波形发生器时主要关注其集成度、主时钟频率、板载存储器的容量、数据传输速率及梯度计算时数据的精度等问题. 其中,集成度决定了梯度波形发生器的尺寸,主时钟频率决定了是否能将应用程序的采样率与硬件的时钟频率相匹配,及各模块的工作频率范围[11],板载存储器的容量决定了产生的梯度波形数目及复杂程度,数据传输速率决定了系统整体耗时,梯度计算时数据的精度影响最终波形的质量. 梯度波形发生器的主要指标是梯度波形的线性度及上升时间[12]. 其中,梯度波形的线性度由DAC的位宽决定,更高的DAC位宽能使得线性度更高. 梯度波形的线性度是衡量梯度磁场平稳性的指标,线性度好代表着梯度磁场在空间中的变化精细,故线性度越好则图像质量就越好[13,14]. 梯度波形的上升时间由DAC的采样率决定,更高的DAC采样率能使得上升时间更短,梯度上升快可进一步加快扫描速度. 由此可见,DAC的选型对梯度波形发生器的设计至关重要. 在梯度波形发生器中,由DAC模块将原始梯度波形数据转换成模拟梯度信号,在选择DAC模块时主要关注其位宽、采样率、群延时等. ...
一种基于DSP与FPGA实现场发射平板显示器视频信号处理系统的方案
1
2010
... DSP采用改进的哈佛总线结构[15],使用时主要使用其乘法与累加(Multiply Accumulate,MAC)功能[16],它可以轻松访问大量输入输出信号,也可以使用超长指令字的方法在一个时钟冲程中执行复杂计算. DSP一般采用C语言编程,擅长顺序执行,开发时间短,尤其是对于先进的控制技术.FPGA主要由基本可编程逻辑单元(Configurable Logic Blocks,CLB)、可编程输入输出单元(Input Output Block,IOB)、嵌入式块随机存储器(Random Access Memory,RAM)组成,采用硬件描述语言Verilog HDL(Hardware Description Language)或VHDL(VHSIC Hardware Description Language)对数字电路或系统进行设计与描述.DSP和FPGA的体系结构使它们能够有效地完成运算与控制,并确保数据具有良好的数值精度[11]. ...
一种基于DSP与FPGA实现场发射平板显示器视频信号处理系统的方案
1
2010
... DSP采用改进的哈佛总线结构[15],使用时主要使用其乘法与累加(Multiply Accumulate,MAC)功能[16],它可以轻松访问大量输入输出信号,也可以使用超长指令字的方法在一个时钟冲程中执行复杂计算. DSP一般采用C语言编程,擅长顺序执行,开发时间短,尤其是对于先进的控制技术.FPGA主要由基本可编程逻辑单元(Configurable Logic Blocks,CLB)、可编程输入输出单元(Input Output Block,IOB)、嵌入式块随机存储器(Random Access Memory,RAM)组成,采用硬件描述语言Verilog HDL(Hardware Description Language)或VHDL(VHSIC Hardware Description Language)对数字电路或系统进行设计与描述.DSP和FPGA的体系结构使它们能够有效地完成运算与控制,并确保数据具有良好的数值精度[11]. ...
A proposed RISC instruction set architecture for the MAC unit of 32-bit VLIW DSP processor core
1
2014
... DSP采用改进的哈佛总线结构[15],使用时主要使用其乘法与累加(Multiply Accumulate,MAC)功能[16],它可以轻松访问大量输入输出信号,也可以使用超长指令字的方法在一个时钟冲程中执行复杂计算. DSP一般采用C语言编程,擅长顺序执行,开发时间短,尤其是对于先进的控制技术.FPGA主要由基本可编程逻辑单元(Configurable Logic Blocks,CLB)、可编程输入输出单元(Input Output Block,IOB)、嵌入式块随机存储器(Random Access Memory,RAM)组成,采用硬件描述语言Verilog HDL(Hardware Description Language)或VHDL(VHSIC Hardware Description Language)对数字电路或系统进行设计与描述.DSP和FPGA的体系结构使它们能够有效地完成运算与控制,并确保数据具有良好的数值精度[11]. ...
Survey on hardware implementation of random number generators on FPGA: Theory and experimental analyses
1
2018
... 单独采用DSP相比基于FPGA设计梯度波形发生器而言有诸多缺点.一方面,DSP的运算管理能力差,需要累计一定量的数据后进行计算,而FPGA的操作是并行的,相比DSP群延时小,能减少对需要精确定时的MRI设备的影响. 另一方面,DSP硬件一旦确定,便难以修改,故其功能比较局限,主要用于特定领域.而FPGA自从赛灵思在80年代发明之后,就作为可编程逻辑器件(Programmable Logic Device,PLD)类芯片的代表性器件.FPGA可重新编程且完全可重新配置,使用预先构建的逻辑块和可编程路由资源,可以自定义硬件[17],有助于梯度波形发生器在后续使用中性能的改进与完善. 此外,在程序编程上,HDL语言虽不如C语言直观,但它们能对硬件资源进行控制,从而实现系统性能优化. 虽然采用HDL的开发相较C编程而言更为复杂,但FPGA厂商提供大量内部设计库或知识产权(Intellectual Property,IP)核,在设计中调用这些设计库及IP核能适当缩短梯度波形发生器的开发周期. ...
Comparison between FPGA Co-Processor&Tms320 C641x DSP Family in Implementing DIF FFT Algorithm
1
2005
... 梯度波形发生器的设计对组件工作速度及灵活性要求较高,单片DSP的顺序执行架构难以满足梯度波形发生器运算速度及灵活性的设计需求,采用多片DSP并行的方案会增加成本并占用大量的电路板空间.FPGA的并行特性能实现更好的信道化,支持更大的数据吞吐量[18].2010年之前,有不少研究人员采用DSP实现梯度波形发生器的设计,但随着FPGA的逐步崛起及对MRI梯度系统的性能要求越来越高,几乎已没有研究者单独采用DSP设计梯度波形发生器. 目前,研究者多采用FPGA或DSP结合FPGA的设计方案,使用片上系统(System-on-Chip,SoC)的设计方案如今也逐步被采用.DSP与FPGA组合设备因其可以实现高并行性和吞吐量,作为一个独立的控制器系统获得了关注,尤其是对于需要实现复杂控制的设备[19],如梯度波形发生器.DSP编程方便且算法通用性好,但DSP的顺序执行架构限制着其运行速度,采用多片DSP并行的方案来提升速度会使设计复杂且体积较大.现场可编程门阵列(Field Programmable Gate Array,FPGA)器件具有并行性、可重构性、处理速度快和拥有灵活的接口等优势,然而,传统的FPGA设计往往较为复杂,因为使用HDL的寄存器传输级(Register Transfer Level,RTL)开发是复杂且耗时的[20].将两者结合用于梯度波形发生器的设计能充分发挥各自的优点. ...
FPGA v/s DSP performance comparison for a VSC-based STATCOM control application
1
2013
... 梯度波形发生器的设计对组件工作速度及灵活性要求较高,单片DSP的顺序执行架构难以满足梯度波形发生器运算速度及灵活性的设计需求,采用多片DSP并行的方案会增加成本并占用大量的电路板空间.FPGA的并行特性能实现更好的信道化,支持更大的数据吞吐量[18].2010年之前,有不少研究人员采用DSP实现梯度波形发生器的设计,但随着FPGA的逐步崛起及对MRI梯度系统的性能要求越来越高,几乎已没有研究者单独采用DSP设计梯度波形发生器. 目前,研究者多采用FPGA或DSP结合FPGA的设计方案,使用片上系统(System-on-Chip,SoC)的设计方案如今也逐步被采用.DSP与FPGA组合设备因其可以实现高并行性和吞吐量,作为一个独立的控制器系统获得了关注,尤其是对于需要实现复杂控制的设备[19],如梯度波形发生器.DSP编程方便且算法通用性好,但DSP的顺序执行架构限制着其运行速度,采用多片DSP并行的方案来提升速度会使设计复杂且体积较大.现场可编程门阵列(Field Programmable Gate Array,FPGA)器件具有并行性、可重构性、处理速度快和拥有灵活的接口等优势,然而,传统的FPGA设计往往较为复杂,因为使用HDL的寄存器传输级(Register Transfer Level,RTL)开发是复杂且耗时的[20].将两者结合用于梯度波形发生器的设计能充分发挥各自的优点. ...
A single-board NMR spectrometer based on a software defined radio architecture
6
2010
... 梯度波形发生器的设计对组件工作速度及灵活性要求较高,单片DSP的顺序执行架构难以满足梯度波形发生器运算速度及灵活性的设计需求,采用多片DSP并行的方案会增加成本并占用大量的电路板空间.FPGA的并行特性能实现更好的信道化,支持更大的数据吞吐量[18].2010年之前,有不少研究人员采用DSP实现梯度波形发生器的设计,但随着FPGA的逐步崛起及对MRI梯度系统的性能要求越来越高,几乎已没有研究者单独采用DSP设计梯度波形发生器. 目前,研究者多采用FPGA或DSP结合FPGA的设计方案,使用片上系统(System-on-Chip,SoC)的设计方案如今也逐步被采用.DSP与FPGA组合设备因其可以实现高并行性和吞吐量,作为一个独立的控制器系统获得了关注,尤其是对于需要实现复杂控制的设备[19],如梯度波形发生器.DSP编程方便且算法通用性好,但DSP的顺序执行架构限制着其运行速度,采用多片DSP并行的方案来提升速度会使设计复杂且体积较大.现场可编程门阵列(Field Programmable Gate Array,FPGA)器件具有并行性、可重构性、处理速度快和拥有灵活的接口等优势,然而,传统的FPGA设计往往较为复杂,因为使用HDL的寄存器传输级(Register Transfer Level,RTL)开发是复杂且耗时的[20].将两者结合用于梯度波形发生器的设计能充分发挥各自的优点. ...
... 2011年,Tang等[20]基于单板可配置软件定义无线电架构设计了一块100 mm×220 mm的小尺寸MRI谱仪,FPGA芯片采用EP3C55F484,负责执行数据计算任务,DSP采用TMS320LF2407A,用于寄存器配置. 其中,梯度波形发生器的实现通过通用串行总线(Universal Serial Bus,USB)接口设备(PDIUSBD12,Philips)将经前端处理后的代码下载到DSP内部程序存储器中,DSP的加载程序通过16 bit并行端口配置FPGA内部的寄存器和梯度波形数据后,由FPGA接收命令字并将其解码为各种控制线,最终传输至24 bit DAC(PCM1704)将波形数据转换为电压脉冲,硬件结构图见图4. 此设计提供了一种高精度、易于编程的梯度波形发生器设计方案. 同时,利用FPGA数量丰富的可编程I/O配置外部控制线,解决了DSP数据及控制输出端口数量有限的问题. 但采用的USB接口设备(PDIUSBD12,Philips)遵循协议USB1.1,其最高传输速率只有12 Mbps,限制了系统在通信速率上的改进. ...
... [
20]
Block diagram of gradient waveform generator based on DSP and FPGA<sup>[<xref ref-type="bibr" rid="b20">20</xref>]</sup>Fig. 4 2012年,Ai等[33]采用Cyclone III系列FPGA处理器EP3C40F484C6,通过以太网接口控制器DM9000读取PC机的梯度波形数据,并将数据存放在FPGA内部设计生成的FIFO(First in,First out)存储器中,使用高性能浮点DSP芯片ADSP21369负责对涡流预加重运算及波形的坐标转换,RAM为DSP扩展内存,用于存储梯度波形数据,最终由FPGA控制精度为24 bit的DAC芯片(PCM1704)进行数模转换后输出(图5).此设计用以太网与主机进行数据传输,采用的DM9000是一款集成10/100 M自适应的网络控制芯片,且提供8 bit和16 bit数据接口以适应不同的处理器[34],传输速率比Tang等[20]采用的USB接口设备快. 但此设计采用DSP进行涡流补偿及梯度变换计算,DSP的顺序执行架构与基于FPGA设计的梯度计算模块相比,在灵活性及运算速度上略显不足. ...
... [
20]
Fig. 4 2012年,Ai等[33]采用Cyclone III系列FPGA处理器EP3C40F484C6,通过以太网接口控制器DM9000读取PC机的梯度波形数据,并将数据存放在FPGA内部设计生成的FIFO(First in,First out)存储器中,使用高性能浮点DSP芯片ADSP21369负责对涡流预加重运算及波形的坐标转换,RAM为DSP扩展内存,用于存储梯度波形数据,最终由FPGA控制精度为24 bit的DAC芯片(PCM1704)进行数模转换后输出(图5).此设计用以太网与主机进行数据传输,采用的DM9000是一款集成10/100 M自适应的网络控制芯片,且提供8 bit和16 bit数据接口以适应不同的处理器[34],传输速率比Tang等[20]采用的USB接口设备快. 但此设计采用DSP进行涡流补偿及梯度变换计算,DSP的顺序执行架构与基于FPGA设计的梯度计算模块相比,在灵活性及运算速度上略显不足. ...
... 2012年,Ai等[33]采用Cyclone III系列FPGA处理器EP3C40F484C6,通过以太网接口控制器DM9000读取PC机的梯度波形数据,并将数据存放在FPGA内部设计生成的FIFO(First in,First out)存储器中,使用高性能浮点DSP芯片ADSP21369负责对涡流预加重运算及波形的坐标转换,RAM为DSP扩展内存,用于存储梯度波形数据,最终由FPGA控制精度为24 bit的DAC芯片(PCM1704)进行数模转换后输出(图5).此设计用以太网与主机进行数据传输,采用的DM9000是一款集成10/100 M自适应的网络控制芯片,且提供8 bit和16 bit数据接口以适应不同的处理器[34],传输速率比Tang等[20]采用的USB接口设备快. 但此设计采用DSP进行涡流补偿及梯度变换计算,DSP的顺序执行架构与基于FPGA设计的梯度计算模块相比,在灵活性及运算速度上略显不足. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
Note:High resolution ultra fast high-power pulse generator for inductive load using digital signal processor
1
2014
... 早期使用软件进行数字信号处理,随着集成电路及半导体技术等发展,使用专用硬件芯片DSP处理数字信号成为主流方法.20世纪90年代末,微处理器,特别是DSP变得更强、更快,DSP具有包含随机存取存储器(RAM)、闪存及各种外围单元[21]的优势,被逐步引入MRI谱仪的开发中,例如利用数字滤波技术实现任意数字滤波器、实现数字化直接频率合成等[22].DSP是为完成数字信号处理任务特意设计的微处理器,它既能迅速处理采样数据,又能实时传输采样数据. 此外,DSP还具有动态范围大,数字信号处理能力强等优点. ...
DSP技术在核磁共振数据系统中的应用
1
2000
... 早期使用软件进行数字信号处理,随着集成电路及半导体技术等发展,使用专用硬件芯片DSP处理数字信号成为主流方法.20世纪90年代末,微处理器,特别是DSP变得更强、更快,DSP具有包含随机存取存储器(RAM)、闪存及各种外围单元[21]的优势,被逐步引入MRI谱仪的开发中,例如利用数字滤波技术实现任意数字滤波器、实现数字化直接频率合成等[22].DSP是为完成数字信号处理任务特意设计的微处理器,它既能迅速处理采样数据,又能实时传输采样数据. 此外,DSP还具有动态范围大,数字信号处理能力强等优点. ...
DSP技术在核磁共振数据系统中的应用
1
2000
... 早期使用软件进行数字信号处理,随着集成电路及半导体技术等发展,使用专用硬件芯片DSP处理数字信号成为主流方法.20世纪90年代末,微处理器,特别是DSP变得更强、更快,DSP具有包含随机存取存储器(RAM)、闪存及各种外围单元[21]的优势,被逐步引入MRI谱仪的开发中,例如利用数字滤波技术实现任意数字滤波器、实现数字化直接频率合成等[22].DSP是为完成数字信号处理任务特意设计的微处理器,它既能迅速处理采样数据,又能实时传输采样数据. 此外,DSP还具有动态范围大,数字信号处理能力强等优点. ...
An open-source, low-cost NMR spectrometer operating in the mT field regime
1
2021
... Dai等[7]采用德州仪器公司的32位(bit)通用浮点DSP芯片TMS320C6713B为核心,基于外设部件互连(Peripheral Component Interconnect,PCI)总线设计了梯度波形发生器. 此DSP主要负责采集触发信号及计算预加重,当DSP采集到触发信号后,将存储在32 MB外接同步动态随机存储器(Synchronous Dynamic Random Access Memory,SDRAM)中的梯度波形数据(选层梯度、相位编码梯度及频率编码梯度数据)进行预加重计算后,由复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)进行并串转换后送至DAC,而后使用电流/电压转换器进行转换以满足后级电路的需求,最后还运用单端转差分电路以达到抑制共模噪声及高频噪声的目的. 此设计的硬件结构框图如图2所示. 选用的DAC为TI公司的PCM1704,群延时小(<2 μs)且具有24 bit位宽. 将此梯度波形发生器集成到自研发的0.3 T永磁开放式MRI,结果表明能对人体头部进行清晰地成像. 采用浮点DSP通常需使用最小32 bit存储各个数值,则所有总线及寄存器均需采用32 bit,此类DSP内部结构复杂,且要求乘法器和算术逻辑运算单元(Arithmetic Logic Unit,ALU)运算能力强大,一定程度上限制了系统的改进. 此外,该设计使用单片DSP实现,相较使用FPGA开发而言,灵活性、可扩展性与运算速度略显不足[23],实时性较差[24]. ...
基于单片FPGA的磁共振成像梯度计算模块
5
2010
... Dai等[7]采用德州仪器公司的32位(bit)通用浮点DSP芯片TMS320C6713B为核心,基于外设部件互连(Peripheral Component Interconnect,PCI)总线设计了梯度波形发生器. 此DSP主要负责采集触发信号及计算预加重,当DSP采集到触发信号后,将存储在32 MB外接同步动态随机存储器(Synchronous Dynamic Random Access Memory,SDRAM)中的梯度波形数据(选层梯度、相位编码梯度及频率编码梯度数据)进行预加重计算后,由复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)进行并串转换后送至DAC,而后使用电流/电压转换器进行转换以满足后级电路的需求,最后还运用单端转差分电路以达到抑制共模噪声及高频噪声的目的. 此设计的硬件结构框图如图2所示. 选用的DAC为TI公司的PCM1704,群延时小(<2 μs)且具有24 bit位宽. 将此梯度波形发生器集成到自研发的0.3 T永磁开放式MRI,结果表明能对人体头部进行清晰地成像. 采用浮点DSP通常需使用最小32 bit存储各个数值,则所有总线及寄存器均需采用32 bit,此类DSP内部结构复杂,且要求乘法器和算术逻辑运算单元(Arithmetic Logic Unit,ALU)运算能力强大,一定程度上限制了系统的改进. 此外,该设计使用单片DSP实现,相较使用FPGA开发而言,灵活性、可扩展性与运算速度略显不足[23],实时性较差[24]. ...
... 此设计改变了先前设计中[24]采用并行计算消耗大量计算资源的缺点,使用串行计算实现矩阵乘法和直流偏置. 实际上,在MRI系统中,梯度波形的更新周期在μs级,而FPGA可以在ns级运行[30],故可以使用逻辑门来构建乘法器,将并行矩阵运算转换为先乘后加的串行运算. 虽然此法同样消耗了大量寄存器,但减少了乘法器的使用,节省了大量的计算资源,FPGA计算资源消耗情况见表1. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
... 自2000年起,不断有研究人员在梯度波形数字预加重设计中提供新方法. 2007年,Liu等[58]使用PC机通过PCI总线配置在FPGA内部构建的寄存器,用以改变预加重的时间与幅度常数,但预加重的通道仅有三路,对梯度涡流的补偿不足. 2008年,Zang等[59]提出利用MR信号测量涡流后,经过拟合、迭代寻找最佳涡流补偿参数的方法,但是该方法首先得确定样品信号区,需要耗时10 min才能得到较好的预加重补偿效果. 2010年,Xiao等[24]采取在FPGA内部使用快速无限冲激响应滤波器(Infinite Impulse Response Filter,IIR)滤波器算法对原始梯度波形叠加过驱动的方法,实现对涡流的预加重处理,但随着迭代次数增加,累计误差也逐渐增加. 2011年,Pan等[6]针对Xiao等[24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
... [24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
基于单片FPGA的磁共振成像梯度计算模块
5
2010
... Dai等[7]采用德州仪器公司的32位(bit)通用浮点DSP芯片TMS320C6713B为核心,基于外设部件互连(Peripheral Component Interconnect,PCI)总线设计了梯度波形发生器. 此DSP主要负责采集触发信号及计算预加重,当DSP采集到触发信号后,将存储在32 MB外接同步动态随机存储器(Synchronous Dynamic Random Access Memory,SDRAM)中的梯度波形数据(选层梯度、相位编码梯度及频率编码梯度数据)进行预加重计算后,由复杂可编程逻辑器件(Complex Programmable Logic Device,CPLD)进行并串转换后送至DAC,而后使用电流/电压转换器进行转换以满足后级电路的需求,最后还运用单端转差分电路以达到抑制共模噪声及高频噪声的目的. 此设计的硬件结构框图如图2所示. 选用的DAC为TI公司的PCM1704,群延时小(<2 μs)且具有24 bit位宽. 将此梯度波形发生器集成到自研发的0.3 T永磁开放式MRI,结果表明能对人体头部进行清晰地成像. 采用浮点DSP通常需使用最小32 bit存储各个数值,则所有总线及寄存器均需采用32 bit,此类DSP内部结构复杂,且要求乘法器和算术逻辑运算单元(Arithmetic Logic Unit,ALU)运算能力强大,一定程度上限制了系统的改进. 此外,该设计使用单片DSP实现,相较使用FPGA开发而言,灵活性、可扩展性与运算速度略显不足[23],实时性较差[24]. ...
... 此设计改变了先前设计中[24]采用并行计算消耗大量计算资源的缺点,使用串行计算实现矩阵乘法和直流偏置. 实际上,在MRI系统中,梯度波形的更新周期在μs级,而FPGA可以在ns级运行[30],故可以使用逻辑门来构建乘法器,将并行矩阵运算转换为先乘后加的串行运算. 虽然此法同样消耗了大量寄存器,但减少了乘法器的使用,节省了大量的计算资源,FPGA计算资源消耗情况见表1. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
... 自2000年起,不断有研究人员在梯度波形数字预加重设计中提供新方法. 2007年,Liu等[58]使用PC机通过PCI总线配置在FPGA内部构建的寄存器,用以改变预加重的时间与幅度常数,但预加重的通道仅有三路,对梯度涡流的补偿不足. 2008年,Zang等[59]提出利用MR信号测量涡流后,经过拟合、迭代寻找最佳涡流补偿参数的方法,但是该方法首先得确定样品信号区,需要耗时10 min才能得到较好的预加重补偿效果. 2010年,Xiao等[24]采取在FPGA内部使用快速无限冲激响应滤波器(Infinite Impulse Response Filter,IIR)滤波器算法对原始梯度波形叠加过驱动的方法,实现对涡流的预加重处理,但随着迭代次数增加,累计误差也逐渐增加. 2011年,Pan等[6]针对Xiao等[24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
... [24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
基于FPGA+DSP的光纤数据传输电路设计
1
2023
... FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
基于FPGA+DSP的光纤数据传输电路设计
1
2023
... FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
核磁共振脉冲序列发生器研究进展
1
2012
... FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
核磁共振脉冲序列发生器研究进展
1
2012
... FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
An autonomous, highly portable NMR spectrometer based on a low-cost System-on-Chip (SoC)
1
2019
... FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
1
2004
... FPGA具有接口适应性强、静态可重复编程及程序移植性强的特性[25],其并行处理的工作模式提高了数据的处理速度. 在FPGA内部实现存储器与定时器等分立元件,能消除分立元件之间延时的不确定性,提高控制系统整体的精度与稳定性[26]. 相较于DSP,FPGA具有固有的并行架构以及处理精确计时要求的能力,采用FPGA作为逻辑控制单元可简化系统设计[27]. 生产FPGA的公司均配置有相应的开发软件,如Xilinx公司的Foundation和Vivado,Altera公司的QuartusII和MaxplusII等,相较于基于DSP的设计,如今更多研究者选用FPGA设计梯度波形发生器[28]. ...
Pulseq: A rapid and hardware-independent pulse sequence prototyping framework
2
2017
... 实现新的MRI序列既耗时又昂贵[29],Kumar等[5]将梯度波形和相位样本放置在脉冲文件中并统一转化为数据包的设计能以最小的代价指定各种序列,并且能够快速部署到硬件. 此外,由于梯度样本的生成速率较低,而FPGA处理速度快,因此无需生成整个梯度样本,从而节省FPGA资源并减少梯度波形生成总时间. 但在此设计中,具体采用的FPGA、DAC型号并未说明. 并且,梯度波形发生器DAC为1 MSPS,但此系统未在梯度波形发生器的输出端设置中间缓冲区,故队列为空的概率较高. ...
... 此外,上文提到的梯度波形发生器设计几乎都需要依赖PC机实现系统控制或数据传输,在设计便携式与可移动性MRI系统时,由于场地限制及功率不足等原因,PC机难以使用. 近年来,研究人员针对设计便携性及可移动性磁共振谱仪提出了新方法[29],他们选用SoC实现了完全自主的操作,解决了传统谱仪设计中无法脱离PC机使用的问题. 目前已有公司对SoC芯片进行研制与量产. 随着对梯度波形发生器更高综合性能如集成度、实时控制及可靠传输的追求,越来越多研究人员开始采用Xilinx公司的产品,如Xilinx公司的“ZYNQ”系列,ZYNQ 全称为Zynq-7000 All Programmable SoC,是高性能全可编程处理平台. ZYNQ SoC集成了采用FPGA实现的可编程逻辑(Programmable Logic,PL)部分和以ARM(Advanced RISC Machines)为核心的处理系统(Processing System,PS)[39]. 在ZYNQ SoC中,FPGA使用HDL进行配置,ARM处理器能运行完整的Linux操作系统,实现嵌入式C语言及嵌入式Python编程. FPGA和ARM之间的双向通信由AXI实现,保障了互联的可预测性及吞吐量[40]. SoC上还具有存储器及典型的外围设备如以太网、USB及通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)等,使其能建立一个完整的计算系统. 采用ZYNQ SoC设计的梯度波形发生器的结构框图如图8所示,上位机通过以太网实现对ZYNQ SoC的控制及数据传输,梯度波形原始数据及相关参数存放在PS的双倍数据速率(Double Data Rate,DDR)SDRAM中,由PS端对数据进行预处理,处理后的数据存放在DDR SDRAM中[41]. 通过AXI实现PS端与PL端的双向通信,双向通信可采用中断或直接内存存取(Direct Memory Access,DMA)方式实现. 在梯度波形生成触发信号作用后,PL端从DDR SDRAM中取出预处理后的数据进行并串转换等处理后,传输至DAC进行数模转换最终输出梯度信号. 采用ZYNQ SoC设计的梯度波形发生器,上位机可通过PS端内部的物理层(Physical Layer,PHY)芯片[42]采用介质无关接口(Media Independent Interface,MII)与ZYNQ板上的媒体访问控制(Media Access Control,MAC)控制器相连,使上位机通过以太网对梯度波形发生器实现数据及参数的传输,以及内部组成部分的控制与更新. ZYNQ的一些系列如XCZU3CG,其PS端外接的以太网接口传输速度能达到1 000 Mbps,与采用独立的DSP和FPGA设计的梯度波形发生器相比,能大大提升系统与上位机的传输速度. 并且,ZYNQ的PS部分的DDR SDRAM存储器,比SDRAM成本更低且传输速率更快,其能在一个时钟周期的上升沿和下降沿传输数据,即具有双倍的SDRAM传输速度[43]. 采用SoC系统设计梯度波形发生器允许集成由第三方提供的IP核,且同时具有ARM的高度可编程性及FPGA的灵活性,将SoC用于设计梯度波形发生器提升便携性的同时,能减小电路板的尺寸和设计的复杂性. 此外,SoC丰富的资源使其可用于设计谱仪的其他部件,如脉冲序列发生器、数字射频收发器等,能极大程度地提升MRI系统的集成化程度. ...
MRI梯度预加重模块的分时复用设计
2
2018
... 此设计改变了先前设计中[24]采用并行计算消耗大量计算资源的缺点,使用串行计算实现矩阵乘法和直流偏置. 实际上,在MRI系统中,梯度波形的更新周期在μs级,而FPGA可以在ns级运行[30],故可以使用逻辑门来构建乘法器,将并行矩阵运算转换为先乘后加的串行运算. 虽然此法同样消耗了大量寄存器,但减少了乘法器的使用,节省了大量的计算资源,FPGA计算资源消耗情况见表1. ...
... 2018年,Huang等[30]在FPGA中设计了具有11通道×4组参数的分时复用梯度预加重模块. 在FPGA中设计了数据选择单元、数据分配单元及预加重计算模块,由选择单元和分配单元将梯度数据和预加重参数输入到梯度计算单元进行预加重计算. 利用FPGA能实现ns级别运算的特点,实现了对数据更新时间为 μs级别的多路梯度信号进行涡流处理. 采取分时复用的方法改变了传统设计中,每组补偿涡流都需要一个计算单元的资源浪费,仅用一个计算单元便极大地降低了涡流,为FPGA节省了大量资源. 但在此设计中,一方面输入信号与预加重后输出的波形信号之间存在4 μs的较长延时,另一方面选用的DAC芯片AD5762的幅度精度只有16 bit,使补偿波形的幅度与时间精度被限制在16 bit以内,难以实现较好的预加重效果. ...
MRI梯度预加重模块的分时复用设计
2
2018
... 此设计改变了先前设计中[24]采用并行计算消耗大量计算资源的缺点,使用串行计算实现矩阵乘法和直流偏置. 实际上,在MRI系统中,梯度波形的更新周期在μs级,而FPGA可以在ns级运行[30],故可以使用逻辑门来构建乘法器,将并行矩阵运算转换为先乘后加的串行运算. 虽然此法同样消耗了大量寄存器,但减少了乘法器的使用,节省了大量的计算资源,FPGA计算资源消耗情况见表1. ...
... 2018年,Huang等[30]在FPGA中设计了具有11通道×4组参数的分时复用梯度预加重模块. 在FPGA中设计了数据选择单元、数据分配单元及预加重计算模块,由选择单元和分配单元将梯度数据和预加重参数输入到梯度计算单元进行预加重计算. 利用FPGA能实现ns级别运算的特点,实现了对数据更新时间为 μs级别的多路梯度信号进行涡流处理. 采取分时复用的方法改变了传统设计中,每组补偿涡流都需要一个计算单元的资源浪费,仅用一个计算单元便极大地降低了涡流,为FPGA节省了大量资源. 但在此设计中,一方面输入信号与预加重后输出的波形信号之间存在4 μs的较长延时,另一方面选用的DAC芯片AD5762的幅度精度只有16 bit,使补偿波形的幅度与时间精度被限制在16 bit以内,难以实现较好的预加重效果. ...
DSP+FPGA的双核串行通信系统设计与实现
1
2022
... 将DSP与FPGA结合的设计方案能充分结合两者优点,且两者之间可采用外部存储器接口(External Memory Interface,EMIF)、通用并行端口(Universal Parallel Port,UPP)、SPI等多种可选择的方式进行数据通信[31]. 将两者结合用于梯度波形发生器的设计,能够高效地完成与梯度波形发生相关数据运算与实时传输,提供多种硬件功能并易于编程,具有准确性、通用性、指令执行速度快且可移植性强的优势[32]. 基于DSP与FPGA各自的优缺点,采用两者结合设计的梯度波形发生器中,DSP常用于数据预处理及配置寄存器,或采用高性能DSP对波形数据进行运算,FPGA则负责与上位机通信及梯度数据的计算与输出. ...
DSP+FPGA的双核串行通信系统设计与实现
1
2022
... 将DSP与FPGA结合的设计方案能充分结合两者优点,且两者之间可采用外部存储器接口(External Memory Interface,EMIF)、通用并行端口(Universal Parallel Port,UPP)、SPI等多种可选择的方式进行数据通信[31]. 将两者结合用于梯度波形发生器的设计,能够高效地完成与梯度波形发生相关数据运算与实时传输,提供多种硬件功能并易于编程,具有准确性、通用性、指令执行速度快且可移植性强的优势[32]. 基于DSP与FPGA各自的优缺点,采用两者结合设计的梯度波形发生器中,DSP常用于数据预处理及配置寄存器,或采用高性能DSP对波形数据进行运算,FPGA则负责与上位机通信及梯度数据的计算与输出. ...
基于FPGA与DSP架构的接收机设计
1
2023
... 将DSP与FPGA结合的设计方案能充分结合两者优点,且两者之间可采用外部存储器接口(External Memory Interface,EMIF)、通用并行端口(Universal Parallel Port,UPP)、SPI等多种可选择的方式进行数据通信[31]. 将两者结合用于梯度波形发生器的设计,能够高效地完成与梯度波形发生相关数据运算与实时传输,提供多种硬件功能并易于编程,具有准确性、通用性、指令执行速度快且可移植性强的优势[32]. 基于DSP与FPGA各自的优缺点,采用两者结合设计的梯度波形发生器中,DSP常用于数据预处理及配置寄存器,或采用高性能DSP对波形数据进行运算,FPGA则负责与上位机通信及梯度数据的计算与输出. ...
基于FPGA与DSP架构的接收机设计
1
2023
... 将DSP与FPGA结合的设计方案能充分结合两者优点,且两者之间可采用外部存储器接口(External Memory Interface,EMIF)、通用并行端口(Universal Parallel Port,UPP)、SPI等多种可选择的方式进行数据通信[31]. 将两者结合用于梯度波形发生器的设计,能够高效地完成与梯度波形发生相关数据运算与实时传输,提供多种硬件功能并易于编程,具有准确性、通用性、指令执行速度快且可移植性强的优势[32]. 基于DSP与FPGA各自的优缺点,采用两者结合设计的梯度波形发生器中,DSP常用于数据预处理及配置寄存器,或采用高性能DSP对波形数据进行运算,FPGA则负责与上位机通信及梯度数据的计算与输出. ...
4
2012
... 2012年,Ai等[33]采用Cyclone III系列FPGA处理器EP3C40F484C6,通过以太网接口控制器DM9000读取PC机的梯度波形数据,并将数据存放在FPGA内部设计生成的FIFO(First in,First out)存储器中,使用高性能浮点DSP芯片ADSP21369负责对涡流预加重运算及波形的坐标转换,RAM为DSP扩展内存,用于存储梯度波形数据,最终由FPGA控制精度为24 bit的DAC芯片(PCM1704)进行数模转换后输出(图5).此设计用以太网与主机进行数据传输,采用的DM9000是一款集成10/100 M自适应的网络控制芯片,且提供8 bit和16 bit数据接口以适应不同的处理器[34],传输速率比Tang等[20]采用的USB接口设备快. 但此设计采用DSP进行涡流补偿及梯度变换计算,DSP的顺序执行架构与基于FPGA设计的梯度计算模块相比,在灵活性及运算速度上略显不足. ...
... 基于DSP与FPGA设计的梯度波形发生器结构框图(根据文献[
33]绘制)
Block diagram of gradient waveform generator based on DSP and FPGA (Reproduced from Ref.[<xref ref-type="bibr" rid="b33">33</xref>])Fig. 5 针对以上设计中存在的问题,2015年,Xiao等[2]基于DSP(TMS320VC33)和FPGA(EP2C8Q208)设计了一个梯度波形时间分辨率达到1 μs的谱仪,其梯度波形发生器的结构框图见图6. 通过网络接口模块中的以太网将来自PC机的参数与波形数据传输到DSP的片上存储器,DSP经外部总线连接梯度生成模块的FPGA,并预先为FPGA配置数据和参数,FPGA根据给定的配置进行梯度计算(包括矩阵乘法、预加重和一阶匀场),其计算结果发送到三个数模转换器(DAC),最终生成并输出梯度波形. DSP软件部分采用汇编语言编写,DSP可通过读取状态端口获取运行时的详细信息,当发生如梯度计算溢出之类的异常时,DSP停止成像处理并立即执行相应的服务子程序. 在此设计中,DSP采用汇编语言编写,编写较为简单,且提供32条控制线,具有强大的控制能力. ...
... Block diagram of gradient waveform generator based on DSP and FPGA (Reproduced from Ref.[
33])
Fig. 5 针对以上设计中存在的问题,2015年,Xiao等[2]基于DSP(TMS320VC33)和FPGA(EP2C8Q208)设计了一个梯度波形时间分辨率达到1 μs的谱仪,其梯度波形发生器的结构框图见图6. 通过网络接口模块中的以太网将来自PC机的参数与波形数据传输到DSP的片上存储器,DSP经外部总线连接梯度生成模块的FPGA,并预先为FPGA配置数据和参数,FPGA根据给定的配置进行梯度计算(包括矩阵乘法、预加重和一阶匀场),其计算结果发送到三个数模转换器(DAC),最终生成并输出梯度波形. DSP软件部分采用汇编语言编写,DSP可通过读取状态端口获取运行时的详细信息,当发生如梯度计算溢出之类的异常时,DSP停止成像处理并立即执行相应的服务子程序. 在此设计中,DSP采用汇编语言编写,编写较为简单,且提供32条控制线,具有强大的控制能力. ...
... Comprehensive comparison of various design schemes
Table 2 | 设计方案 | 第一作者 | 关键技术 | 主时钟频率 | DAC位宽 | 存储器容量 | 精度、时间分辨率及场强 | 优势和劣势 |
基于DSP的设计方案
| Dai[7] | DSP(TMS320C6713B,TI)基于PCI总线,
接收来自上位机的
数据并预处理,DSP
代码编译环境为
CCS 2.0
| 300 MHz | PCM1704,
采样频率16~96 kHz,
24 bit
| 外接SDRAM
与FLASH:
32 MB/8 MB
| 数据精度32 bit,
0.3 T
| 性能稳定、成本低廉;灵活性、可扩展性不足,实时性较差[24] |
基于FPGA的设计方案
| Kumar[5] | 采用FPGA构建处理
器及梯度波形合成
器,使用Vivado软
件进行设计与仿真
| / | 未说明所选用的DAC
| FIFO IP核,未说明数据
深度
| 输出梯度波形的最
小分辨率为0.4 ms
| 节省了FPGA
资源,减少了
梯度波形生成
时间;系统输
出速率快,可
能导致输出
为空
|
| Xing[3] | 使用FPGA
(EP2C35F484,
Altara)及Quartus II
软件共同设计梯度波
形发生器
| 50 MHz | 未说明所选用的DAC
| RAM:
483840 bit | 数据精度24 bit,
时间分辨率1 μs
| 使用串行运算
减少了FPGA
乘法器资源消
耗;增加了
运算的难度
|
| 基于DSP和FPGA结合的设计方案 | Tang[20] | DSP(TMS320LF2407A,
TI)将数据等传至
FPGA(EP3C55F484,
Altera),与Simulink
和System Generator
软件联合设计梯度
波形发生器
| / | PCM1704 | RAM:
292 KB | 数据精度32 bit,
时间分辨率1 μs,
<0.7 T
| 电路板尺寸小,
成本低;采用
USB进行上位
机与梯度波形
发生器的通信,
通信速度相较
以太网而言较慢
|
| Ai[33] | 上位机由以太网传
递信号至FPGA
(EP3C40F484C6,
Altera),DSP
(ADSP21369,ADI)实现梯度计算,软件Quartus II及
Moldelsim
| 50 MHz | PCM1704 | SDRAM:
1GB/4GB
| 幅度参数精度24 bit,
时间参数精度为32 bit,
时间分辨率1 μs,
<0.5 T
| 切换精度小于100 μs;采用DSP进行梯度
计算在运算速
度及计算量上
存在不足
|
| Xiao[2] | DSP(TMS320VC33,TI)接收数据,
FPGA(EP2C8Q208,
Altera)实现梯度计算
| 60 MHz | 未说明所选用的DAC
| ROM:
256 KB,
SDRAM:
1 MB | 时间分辨率1 μs,
0.35 T | DSP有32条控制线及24条地址线,有利于对FPGA进行控制及传输信号 |
存储器:此处的存储器指存放梯度波形数据、相关参数及相应代码的存储器;MB:即兆字节(Megabytes),是存储容量单位;bit:位;ROM:Read-only Memory,只读存储器;精度:即数据精度,指进行梯度计算时梯度数据的位数;时间分辨率:指输出梯度信号的时间分辨率;场强:指实验验证所用MRI设备的场强. ...
基于DM9000A的DSP6711以太网接口扩展
1
2019
... 2012年,Ai等[33]采用Cyclone III系列FPGA处理器EP3C40F484C6,通过以太网接口控制器DM9000读取PC机的梯度波形数据,并将数据存放在FPGA内部设计生成的FIFO(First in,First out)存储器中,使用高性能浮点DSP芯片ADSP21369负责对涡流预加重运算及波形的坐标转换,RAM为DSP扩展内存,用于存储梯度波形数据,最终由FPGA控制精度为24 bit的DAC芯片(PCM1704)进行数模转换后输出(图5).此设计用以太网与主机进行数据传输,采用的DM9000是一款集成10/100 M自适应的网络控制芯片,且提供8 bit和16 bit数据接口以适应不同的处理器[34],传输速率比Tang等[20]采用的USB接口设备快. 但此设计采用DSP进行涡流补偿及梯度变换计算,DSP的顺序执行架构与基于FPGA设计的梯度计算模块相比,在灵活性及运算速度上略显不足. ...
基于DM9000A的DSP6711以太网接口扩展
1
2019
... 2012年,Ai等[33]采用Cyclone III系列FPGA处理器EP3C40F484C6,通过以太网接口控制器DM9000读取PC机的梯度波形数据,并将数据存放在FPGA内部设计生成的FIFO(First in,First out)存储器中,使用高性能浮点DSP芯片ADSP21369负责对涡流预加重运算及波形的坐标转换,RAM为DSP扩展内存,用于存储梯度波形数据,最终由FPGA控制精度为24 bit的DAC芯片(PCM1704)进行数模转换后输出(图5).此设计用以太网与主机进行数据传输,采用的DM9000是一款集成10/100 M自适应的网络控制芯片,且提供8 bit和16 bit数据接口以适应不同的处理器[34],传输速率比Tang等[20]采用的USB接口设备快. 但此设计采用DSP进行涡流补偿及梯度变换计算,DSP的顺序执行架构与基于FPGA设计的梯度计算模块相比,在灵活性及运算速度上略显不足. ...
Low-field MRI: An MR physics perspective
1
2019
... 以上讨论了近二十年来国内外文献中有关梯度波形发生器的详细设计及优缺点,表2对各方法进行了分析比较. 设计方案中采用的主控芯片的时钟频率几乎均为几十至几百MHz,能使输出的梯度信号具有μs级别的时间分辨率. 梯度波形发生器相关代码、原始梯度数据及参数存放于各类型存储器中. MRI系统对各组件的工作时间及群延时均有严格规定,故硬件的选型至关重要. 在过去的MRI系统中,如我国安科公司的ASM-016P永磁型MRI,梯度场大多上升时间为1 ms,如今的MRI设备要求梯度场上升时间为零点几至1 ms. 作为梯度波形发生器的关键器件之一,DAC的数模转换时间及群延时极大地影响着梯度场的上升时间[35]. 梯度波形的上升时间由DAC的采样率决定,线性度由DAC位宽决定,PCM1704采样频率能达到96 kHz,群延时短(<2 μs)且位宽为24 bit,能有效保障梯度波形发生器良好的上升时间及线性度. 梯度波形发生器作为梯度子系统的核心部件之一,它的性能直接影响着梯度系统最终产生的梯度场的性能,梯度场的主要性能可由场强、切换率、线性度及上升时间等衡量,表3为磁共振设备各厂商特定场强下主流型号设备的梯度场性能比较. ...
1
2020
... 以上设计中FPGA与DSP是商用的独立器件,它们之间需要通过各种类型的总线或接口进行通信,在开发周期、系统稳定性及通信效率上存在一定不足. 如今,国外已研发并量产了具有嵌入式DSP的FPGA芯片,如Xilinx公司研制的Virtex-6及Virtex-7等系列,国内也有研究人员提出了具有嵌入式DSP的FPGA设计[36,37]. 具有嵌入式FPGA的DSP芯片的产品也已在国外量产,2022年,CEVA和FLEX LOGIX推出了首款具有嵌入式FPGA的DSP芯片[38],其支持灵活和可更改的指令集,满足用户的多种需求. 这些产品及设计既有FPGA并行性、可重构性及处理速度快的优点,又具有DSP能实现复杂数字信号处理的特点,将它们用于设计梯度波形发生器能缩短开发周期,提高集成度、运算速度及系统稳定性. ...
A high-speed and area-efficiency DSP block embedded in FPGAs
1
2016
... 以上设计中FPGA与DSP是商用的独立器件,它们之间需要通过各种类型的总线或接口进行通信,在开发周期、系统稳定性及通信效率上存在一定不足. 如今,国外已研发并量产了具有嵌入式DSP的FPGA芯片,如Xilinx公司研制的Virtex-6及Virtex-7等系列,国内也有研究人员提出了具有嵌入式DSP的FPGA设计[36,37]. 具有嵌入式FPGA的DSP芯片的产品也已在国外量产,2022年,CEVA和FLEX LOGIX推出了首款具有嵌入式FPGA的DSP芯片[38],其支持灵活和可更改的指令集,满足用户的多种需求. 这些产品及设计既有FPGA并行性、可重构性及处理速度快的优点,又具有DSP能实现复杂数字信号处理的特点,将它们用于设计梯度波形发生器能缩短开发周期,提高集成度、运算速度及系统稳定性. ...
CEVA和FLEX LOGIX推出具有嵌入式FPGA的DSP芯片
1
2022
... 以上设计中FPGA与DSP是商用的独立器件,它们之间需要通过各种类型的总线或接口进行通信,在开发周期、系统稳定性及通信效率上存在一定不足. 如今,国外已研发并量产了具有嵌入式DSP的FPGA芯片,如Xilinx公司研制的Virtex-6及Virtex-7等系列,国内也有研究人员提出了具有嵌入式DSP的FPGA设计[36,37]. 具有嵌入式FPGA的DSP芯片的产品也已在国外量产,2022年,CEVA和FLEX LOGIX推出了首款具有嵌入式FPGA的DSP芯片[38],其支持灵活和可更改的指令集,满足用户的多种需求. 这些产品及设计既有FPGA并行性、可重构性及处理速度快的优点,又具有DSP能实现复杂数字信号处理的特点,将它们用于设计梯度波形发生器能缩短开发周期,提高集成度、运算速度及系统稳定性. ...
CEVA和FLEX LOGIX推出具有嵌入式FPGA的DSP芯片
1
2022
... 以上设计中FPGA与DSP是商用的独立器件,它们之间需要通过各种类型的总线或接口进行通信,在开发周期、系统稳定性及通信效率上存在一定不足. 如今,国外已研发并量产了具有嵌入式DSP的FPGA芯片,如Xilinx公司研制的Virtex-6及Virtex-7等系列,国内也有研究人员提出了具有嵌入式DSP的FPGA设计[36,37]. 具有嵌入式FPGA的DSP芯片的产品也已在国外量产,2022年,CEVA和FLEX LOGIX推出了首款具有嵌入式FPGA的DSP芯片[38],其支持灵活和可更改的指令集,满足用户的多种需求. 这些产品及设计既有FPGA并行性、可重构性及处理速度快的优点,又具有DSP能实现复杂数字信号处理的特点,将它们用于设计梯度波形发生器能缩短开发周期,提高集成度、运算速度及系统稳定性. ...
基于全可编程SoC和LabVIEW的磁共振接收系统设计
1
2018
... 此外,上文提到的梯度波形发生器设计几乎都需要依赖PC机实现系统控制或数据传输,在设计便携式与可移动性MRI系统时,由于场地限制及功率不足等原因,PC机难以使用. 近年来,研究人员针对设计便携性及可移动性磁共振谱仪提出了新方法[29],他们选用SoC实现了完全自主的操作,解决了传统谱仪设计中无法脱离PC机使用的问题. 目前已有公司对SoC芯片进行研制与量产. 随着对梯度波形发生器更高综合性能如集成度、实时控制及可靠传输的追求,越来越多研究人员开始采用Xilinx公司的产品,如Xilinx公司的“ZYNQ”系列,ZYNQ 全称为Zynq-7000 All Programmable SoC,是高性能全可编程处理平台. ZYNQ SoC集成了采用FPGA实现的可编程逻辑(Programmable Logic,PL)部分和以ARM(Advanced RISC Machines)为核心的处理系统(Processing System,PS)[39]. 在ZYNQ SoC中,FPGA使用HDL进行配置,ARM处理器能运行完整的Linux操作系统,实现嵌入式C语言及嵌入式Python编程. FPGA和ARM之间的双向通信由AXI实现,保障了互联的可预测性及吞吐量[40]. SoC上还具有存储器及典型的外围设备如以太网、USB及通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)等,使其能建立一个完整的计算系统. 采用ZYNQ SoC设计的梯度波形发生器的结构框图如图8所示,上位机通过以太网实现对ZYNQ SoC的控制及数据传输,梯度波形原始数据及相关参数存放在PS的双倍数据速率(Double Data Rate,DDR)SDRAM中,由PS端对数据进行预处理,处理后的数据存放在DDR SDRAM中[41]. 通过AXI实现PS端与PL端的双向通信,双向通信可采用中断或直接内存存取(Direct Memory Access,DMA)方式实现. 在梯度波形生成触发信号作用后,PL端从DDR SDRAM中取出预处理后的数据进行并串转换等处理后,传输至DAC进行数模转换最终输出梯度信号. 采用ZYNQ SoC设计的梯度波形发生器,上位机可通过PS端内部的物理层(Physical Layer,PHY)芯片[42]采用介质无关接口(Media Independent Interface,MII)与ZYNQ板上的媒体访问控制(Media Access Control,MAC)控制器相连,使上位机通过以太网对梯度波形发生器实现数据及参数的传输,以及内部组成部分的控制与更新. ZYNQ的一些系列如XCZU3CG,其PS端外接的以太网接口传输速度能达到1 000 Mbps,与采用独立的DSP和FPGA设计的梯度波形发生器相比,能大大提升系统与上位机的传输速度. 并且,ZYNQ的PS部分的DDR SDRAM存储器,比SDRAM成本更低且传输速率更快,其能在一个时钟周期的上升沿和下降沿传输数据,即具有双倍的SDRAM传输速度[43]. 采用SoC系统设计梯度波形发生器允许集成由第三方提供的IP核,且同时具有ARM的高度可编程性及FPGA的灵活性,将SoC用于设计梯度波形发生器提升便携性的同时,能减小电路板的尺寸和设计的复杂性. 此外,SoC丰富的资源使其可用于设计谱仪的其他部件,如脉冲序列发生器、数字射频收发器等,能极大程度地提升MRI系统的集成化程度. ...
基于全可编程SoC和LabVIEW的磁共振接收系统设计
1
2018
... 此外,上文提到的梯度波形发生器设计几乎都需要依赖PC机实现系统控制或数据传输,在设计便携式与可移动性MRI系统时,由于场地限制及功率不足等原因,PC机难以使用. 近年来,研究人员针对设计便携性及可移动性磁共振谱仪提出了新方法[29],他们选用SoC实现了完全自主的操作,解决了传统谱仪设计中无法脱离PC机使用的问题. 目前已有公司对SoC芯片进行研制与量产. 随着对梯度波形发生器更高综合性能如集成度、实时控制及可靠传输的追求,越来越多研究人员开始采用Xilinx公司的产品,如Xilinx公司的“ZYNQ”系列,ZYNQ 全称为Zynq-7000 All Programmable SoC,是高性能全可编程处理平台. ZYNQ SoC集成了采用FPGA实现的可编程逻辑(Programmable Logic,PL)部分和以ARM(Advanced RISC Machines)为核心的处理系统(Processing System,PS)[39]. 在ZYNQ SoC中,FPGA使用HDL进行配置,ARM处理器能运行完整的Linux操作系统,实现嵌入式C语言及嵌入式Python编程. FPGA和ARM之间的双向通信由AXI实现,保障了互联的可预测性及吞吐量[40]. SoC上还具有存储器及典型的外围设备如以太网、USB及通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)等,使其能建立一个完整的计算系统. 采用ZYNQ SoC设计的梯度波形发生器的结构框图如图8所示,上位机通过以太网实现对ZYNQ SoC的控制及数据传输,梯度波形原始数据及相关参数存放在PS的双倍数据速率(Double Data Rate,DDR)SDRAM中,由PS端对数据进行预处理,处理后的数据存放在DDR SDRAM中[41]. 通过AXI实现PS端与PL端的双向通信,双向通信可采用中断或直接内存存取(Direct Memory Access,DMA)方式实现. 在梯度波形生成触发信号作用后,PL端从DDR SDRAM中取出预处理后的数据进行并串转换等处理后,传输至DAC进行数模转换最终输出梯度信号. 采用ZYNQ SoC设计的梯度波形发生器,上位机可通过PS端内部的物理层(Physical Layer,PHY)芯片[42]采用介质无关接口(Media Independent Interface,MII)与ZYNQ板上的媒体访问控制(Media Access Control,MAC)控制器相连,使上位机通过以太网对梯度波形发生器实现数据及参数的传输,以及内部组成部分的控制与更新. ZYNQ的一些系列如XCZU3CG,其PS端外接的以太网接口传输速度能达到1 000 Mbps,与采用独立的DSP和FPGA设计的梯度波形发生器相比,能大大提升系统与上位机的传输速度. 并且,ZYNQ的PS部分的DDR SDRAM存储器,比SDRAM成本更低且传输速率更快,其能在一个时钟周期的上升沿和下降沿传输数据,即具有双倍的SDRAM传输速度[43]. 采用SoC系统设计梯度波形发生器允许集成由第三方提供的IP核,且同时具有ARM的高度可编程性及FPGA的灵活性,将SoC用于设计梯度波形发生器提升便携性的同时,能减小电路板的尺寸和设计的复杂性. 此外,SoC丰富的资源使其可用于设计谱仪的其他部件,如脉冲序列发生器、数字射频收发器等,能极大程度地提升MRI系统的集成化程度. ...
AXI-ICRTRT: Towards a real-time AXI-interconnect for highly integrated SoCs
1
2023
... 此外,上文提到的梯度波形发生器设计几乎都需要依赖PC机实现系统控制或数据传输,在设计便携式与可移动性MRI系统时,由于场地限制及功率不足等原因,PC机难以使用. 近年来,研究人员针对设计便携性及可移动性磁共振谱仪提出了新方法[29],他们选用SoC实现了完全自主的操作,解决了传统谱仪设计中无法脱离PC机使用的问题. 目前已有公司对SoC芯片进行研制与量产. 随着对梯度波形发生器更高综合性能如集成度、实时控制及可靠传输的追求,越来越多研究人员开始采用Xilinx公司的产品,如Xilinx公司的“ZYNQ”系列,ZYNQ 全称为Zynq-7000 All Programmable SoC,是高性能全可编程处理平台. ZYNQ SoC集成了采用FPGA实现的可编程逻辑(Programmable Logic,PL)部分和以ARM(Advanced RISC Machines)为核心的处理系统(Processing System,PS)[39]. 在ZYNQ SoC中,FPGA使用HDL进行配置,ARM处理器能运行完整的Linux操作系统,实现嵌入式C语言及嵌入式Python编程. FPGA和ARM之间的双向通信由AXI实现,保障了互联的可预测性及吞吐量[40]. SoC上还具有存储器及典型的外围设备如以太网、USB及通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)等,使其能建立一个完整的计算系统. 采用ZYNQ SoC设计的梯度波形发生器的结构框图如图8所示,上位机通过以太网实现对ZYNQ SoC的控制及数据传输,梯度波形原始数据及相关参数存放在PS的双倍数据速率(Double Data Rate,DDR)SDRAM中,由PS端对数据进行预处理,处理后的数据存放在DDR SDRAM中[41]. 通过AXI实现PS端与PL端的双向通信,双向通信可采用中断或直接内存存取(Direct Memory Access,DMA)方式实现. 在梯度波形生成触发信号作用后,PL端从DDR SDRAM中取出预处理后的数据进行并串转换等处理后,传输至DAC进行数模转换最终输出梯度信号. 采用ZYNQ SoC设计的梯度波形发生器,上位机可通过PS端内部的物理层(Physical Layer,PHY)芯片[42]采用介质无关接口(Media Independent Interface,MII)与ZYNQ板上的媒体访问控制(Media Access Control,MAC)控制器相连,使上位机通过以太网对梯度波形发生器实现数据及参数的传输,以及内部组成部分的控制与更新. ZYNQ的一些系列如XCZU3CG,其PS端外接的以太网接口传输速度能达到1 000 Mbps,与采用独立的DSP和FPGA设计的梯度波形发生器相比,能大大提升系统与上位机的传输速度. 并且,ZYNQ的PS部分的DDR SDRAM存储器,比SDRAM成本更低且传输速率更快,其能在一个时钟周期的上升沿和下降沿传输数据,即具有双倍的SDRAM传输速度[43]. 采用SoC系统设计梯度波形发生器允许集成由第三方提供的IP核,且同时具有ARM的高度可编程性及FPGA的灵活性,将SoC用于设计梯度波形发生器提升便携性的同时,能减小电路板的尺寸和设计的复杂性. 此外,SoC丰富的资源使其可用于设计谱仪的其他部件,如脉冲序列发生器、数字射频收发器等,能极大程度地提升MRI系统的集成化程度. ...
基于双参考源的数字磁共振控制台相位相干技术
1
2022
... 此外,上文提到的梯度波形发生器设计几乎都需要依赖PC机实现系统控制或数据传输,在设计便携式与可移动性MRI系统时,由于场地限制及功率不足等原因,PC机难以使用. 近年来,研究人员针对设计便携性及可移动性磁共振谱仪提出了新方法[29],他们选用SoC实现了完全自主的操作,解决了传统谱仪设计中无法脱离PC机使用的问题. 目前已有公司对SoC芯片进行研制与量产. 随着对梯度波形发生器更高综合性能如集成度、实时控制及可靠传输的追求,越来越多研究人员开始采用Xilinx公司的产品,如Xilinx公司的“ZYNQ”系列,ZYNQ 全称为Zynq-7000 All Programmable SoC,是高性能全可编程处理平台. ZYNQ SoC集成了采用FPGA实现的可编程逻辑(Programmable Logic,PL)部分和以ARM(Advanced RISC Machines)为核心的处理系统(Processing System,PS)[39]. 在ZYNQ SoC中,FPGA使用HDL进行配置,ARM处理器能运行完整的Linux操作系统,实现嵌入式C语言及嵌入式Python编程. FPGA和ARM之间的双向通信由AXI实现,保障了互联的可预测性及吞吐量[40]. SoC上还具有存储器及典型的外围设备如以太网、USB及通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)等,使其能建立一个完整的计算系统. 采用ZYNQ SoC设计的梯度波形发生器的结构框图如图8所示,上位机通过以太网实现对ZYNQ SoC的控制及数据传输,梯度波形原始数据及相关参数存放在PS的双倍数据速率(Double Data Rate,DDR)SDRAM中,由PS端对数据进行预处理,处理后的数据存放在DDR SDRAM中[41]. 通过AXI实现PS端与PL端的双向通信,双向通信可采用中断或直接内存存取(Direct Memory Access,DMA)方式实现. 在梯度波形生成触发信号作用后,PL端从DDR SDRAM中取出预处理后的数据进行并串转换等处理后,传输至DAC进行数模转换最终输出梯度信号. 采用ZYNQ SoC设计的梯度波形发生器,上位机可通过PS端内部的物理层(Physical Layer,PHY)芯片[42]采用介质无关接口(Media Independent Interface,MII)与ZYNQ板上的媒体访问控制(Media Access Control,MAC)控制器相连,使上位机通过以太网对梯度波形发生器实现数据及参数的传输,以及内部组成部分的控制与更新. ZYNQ的一些系列如XCZU3CG,其PS端外接的以太网接口传输速度能达到1 000 Mbps,与采用独立的DSP和FPGA设计的梯度波形发生器相比,能大大提升系统与上位机的传输速度. 并且,ZYNQ的PS部分的DDR SDRAM存储器,比SDRAM成本更低且传输速率更快,其能在一个时钟周期的上升沿和下降沿传输数据,即具有双倍的SDRAM传输速度[43]. 采用SoC系统设计梯度波形发生器允许集成由第三方提供的IP核,且同时具有ARM的高度可编程性及FPGA的灵活性,将SoC用于设计梯度波形发生器提升便携性的同时,能减小电路板的尺寸和设计的复杂性. 此外,SoC丰富的资源使其可用于设计谱仪的其他部件,如脉冲序列发生器、数字射频收发器等,能极大程度地提升MRI系统的集成化程度. ...
基于双参考源的数字磁共振控制台相位相干技术
1
2022
... 此外,上文提到的梯度波形发生器设计几乎都需要依赖PC机实现系统控制或数据传输,在设计便携式与可移动性MRI系统时,由于场地限制及功率不足等原因,PC机难以使用. 近年来,研究人员针对设计便携性及可移动性磁共振谱仪提出了新方法[29],他们选用SoC实现了完全自主的操作,解决了传统谱仪设计中无法脱离PC机使用的问题. 目前已有公司对SoC芯片进行研制与量产. 随着对梯度波形发生器更高综合性能如集成度、实时控制及可靠传输的追求,越来越多研究人员开始采用Xilinx公司的产品,如Xilinx公司的“ZYNQ”系列,ZYNQ 全称为Zynq-7000 All Programmable SoC,是高性能全可编程处理平台. ZYNQ SoC集成了采用FPGA实现的可编程逻辑(Programmable Logic,PL)部分和以ARM(Advanced RISC Machines)为核心的处理系统(Processing System,PS)[39]. 在ZYNQ SoC中,FPGA使用HDL进行配置,ARM处理器能运行完整的Linux操作系统,实现嵌入式C语言及嵌入式Python编程. FPGA和ARM之间的双向通信由AXI实现,保障了互联的可预测性及吞吐量[40]. SoC上还具有存储器及典型的外围设备如以太网、USB及通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)等,使其能建立一个完整的计算系统. 采用ZYNQ SoC设计的梯度波形发生器的结构框图如图8所示,上位机通过以太网实现对ZYNQ SoC的控制及数据传输,梯度波形原始数据及相关参数存放在PS的双倍数据速率(Double Data Rate,DDR)SDRAM中,由PS端对数据进行预处理,处理后的数据存放在DDR SDRAM中[41]. 通过AXI实现PS端与PL端的双向通信,双向通信可采用中断或直接内存存取(Direct Memory Access,DMA)方式实现. 在梯度波形生成触发信号作用后,PL端从DDR SDRAM中取出预处理后的数据进行并串转换等处理后,传输至DAC进行数模转换最终输出梯度信号. 采用ZYNQ SoC设计的梯度波形发生器,上位机可通过PS端内部的物理层(Physical Layer,PHY)芯片[42]采用介质无关接口(Media Independent Interface,MII)与ZYNQ板上的媒体访问控制(Media Access Control,MAC)控制器相连,使上位机通过以太网对梯度波形发生器实现数据及参数的传输,以及内部组成部分的控制与更新. ZYNQ的一些系列如XCZU3CG,其PS端外接的以太网接口传输速度能达到1 000 Mbps,与采用独立的DSP和FPGA设计的梯度波形发生器相比,能大大提升系统与上位机的传输速度. 并且,ZYNQ的PS部分的DDR SDRAM存储器,比SDRAM成本更低且传输速率更快,其能在一个时钟周期的上升沿和下降沿传输数据,即具有双倍的SDRAM传输速度[43]. 采用SoC系统设计梯度波形发生器允许集成由第三方提供的IP核,且同时具有ARM的高度可编程性及FPGA的灵活性,将SoC用于设计梯度波形发生器提升便携性的同时,能减小电路板的尺寸和设计的复杂性. 此外,SoC丰富的资源使其可用于设计谱仪的其他部件,如脉冲序列发生器、数字射频收发器等,能极大程度地提升MRI系统的集成化程度. ...
Xilinx delivers Zynq UltraScale+RFSoC family integrating the RF signal chain for 5 G wireless, cable remote-PHY, and Radar
1
... 此外,上文提到的梯度波形发生器设计几乎都需要依赖PC机实现系统控制或数据传输,在设计便携式与可移动性MRI系统时,由于场地限制及功率不足等原因,PC机难以使用. 近年来,研究人员针对设计便携性及可移动性磁共振谱仪提出了新方法[29],他们选用SoC实现了完全自主的操作,解决了传统谱仪设计中无法脱离PC机使用的问题. 目前已有公司对SoC芯片进行研制与量产. 随着对梯度波形发生器更高综合性能如集成度、实时控制及可靠传输的追求,越来越多研究人员开始采用Xilinx公司的产品,如Xilinx公司的“ZYNQ”系列,ZYNQ 全称为Zynq-7000 All Programmable SoC,是高性能全可编程处理平台. ZYNQ SoC集成了采用FPGA实现的可编程逻辑(Programmable Logic,PL)部分和以ARM(Advanced RISC Machines)为核心的处理系统(Processing System,PS)[39]. 在ZYNQ SoC中,FPGA使用HDL进行配置,ARM处理器能运行完整的Linux操作系统,实现嵌入式C语言及嵌入式Python编程. FPGA和ARM之间的双向通信由AXI实现,保障了互联的可预测性及吞吐量[40]. SoC上还具有存储器及典型的外围设备如以太网、USB及通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)等,使其能建立一个完整的计算系统. 采用ZYNQ SoC设计的梯度波形发生器的结构框图如图8所示,上位机通过以太网实现对ZYNQ SoC的控制及数据传输,梯度波形原始数据及相关参数存放在PS的双倍数据速率(Double Data Rate,DDR)SDRAM中,由PS端对数据进行预处理,处理后的数据存放在DDR SDRAM中[41]. 通过AXI实现PS端与PL端的双向通信,双向通信可采用中断或直接内存存取(Direct Memory Access,DMA)方式实现. 在梯度波形生成触发信号作用后,PL端从DDR SDRAM中取出预处理后的数据进行并串转换等处理后,传输至DAC进行数模转换最终输出梯度信号. 采用ZYNQ SoC设计的梯度波形发生器,上位机可通过PS端内部的物理层(Physical Layer,PHY)芯片[42]采用介质无关接口(Media Independent Interface,MII)与ZYNQ板上的媒体访问控制(Media Access Control,MAC)控制器相连,使上位机通过以太网对梯度波形发生器实现数据及参数的传输,以及内部组成部分的控制与更新. ZYNQ的一些系列如XCZU3CG,其PS端外接的以太网接口传输速度能达到1 000 Mbps,与采用独立的DSP和FPGA设计的梯度波形发生器相比,能大大提升系统与上位机的传输速度. 并且,ZYNQ的PS部分的DDR SDRAM存储器,比SDRAM成本更低且传输速率更快,其能在一个时钟周期的上升沿和下降沿传输数据,即具有双倍的SDRAM传输速度[43]. 采用SoC系统设计梯度波形发生器允许集成由第三方提供的IP核,且同时具有ARM的高度可编程性及FPGA的灵活性,将SoC用于设计梯度波形发生器提升便携性的同时,能减小电路板的尺寸和设计的复杂性. 此外,SoC丰富的资源使其可用于设计谱仪的其他部件,如脉冲序列发生器、数字射频收发器等,能极大程度地提升MRI系统的集成化程度. ...
Design and verification of DDR SDRAM memory controller using system verilog for higher coverage
1
2019
... 此外,上文提到的梯度波形发生器设计几乎都需要依赖PC机实现系统控制或数据传输,在设计便携式与可移动性MRI系统时,由于场地限制及功率不足等原因,PC机难以使用. 近年来,研究人员针对设计便携性及可移动性磁共振谱仪提出了新方法[29],他们选用SoC实现了完全自主的操作,解决了传统谱仪设计中无法脱离PC机使用的问题. 目前已有公司对SoC芯片进行研制与量产. 随着对梯度波形发生器更高综合性能如集成度、实时控制及可靠传输的追求,越来越多研究人员开始采用Xilinx公司的产品,如Xilinx公司的“ZYNQ”系列,ZYNQ 全称为Zynq-7000 All Programmable SoC,是高性能全可编程处理平台. ZYNQ SoC集成了采用FPGA实现的可编程逻辑(Programmable Logic,PL)部分和以ARM(Advanced RISC Machines)为核心的处理系统(Processing System,PS)[39]. 在ZYNQ SoC中,FPGA使用HDL进行配置,ARM处理器能运行完整的Linux操作系统,实现嵌入式C语言及嵌入式Python编程. FPGA和ARM之间的双向通信由AXI实现,保障了互联的可预测性及吞吐量[40]. SoC上还具有存储器及典型的外围设备如以太网、USB及通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)等,使其能建立一个完整的计算系统. 采用ZYNQ SoC设计的梯度波形发生器的结构框图如图8所示,上位机通过以太网实现对ZYNQ SoC的控制及数据传输,梯度波形原始数据及相关参数存放在PS的双倍数据速率(Double Data Rate,DDR)SDRAM中,由PS端对数据进行预处理,处理后的数据存放在DDR SDRAM中[41]. 通过AXI实现PS端与PL端的双向通信,双向通信可采用中断或直接内存存取(Direct Memory Access,DMA)方式实现. 在梯度波形生成触发信号作用后,PL端从DDR SDRAM中取出预处理后的数据进行并串转换等处理后,传输至DAC进行数模转换最终输出梯度信号. 采用ZYNQ SoC设计的梯度波形发生器,上位机可通过PS端内部的物理层(Physical Layer,PHY)芯片[42]采用介质无关接口(Media Independent Interface,MII)与ZYNQ板上的媒体访问控制(Media Access Control,MAC)控制器相连,使上位机通过以太网对梯度波形发生器实现数据及参数的传输,以及内部组成部分的控制与更新. ZYNQ的一些系列如XCZU3CG,其PS端外接的以太网接口传输速度能达到1 000 Mbps,与采用独立的DSP和FPGA设计的梯度波形发生器相比,能大大提升系统与上位机的传输速度. 并且,ZYNQ的PS部分的DDR SDRAM存储器,比SDRAM成本更低且传输速率更快,其能在一个时钟周期的上升沿和下降沿传输数据,即具有双倍的SDRAM传输速度[43]. 采用SoC系统设计梯度波形发生器允许集成由第三方提供的IP核,且同时具有ARM的高度可编程性及FPGA的灵活性,将SoC用于设计梯度波形发生器提升便携性的同时,能减小电路板的尺寸和设计的复杂性. 此外,SoC丰富的资源使其可用于设计谱仪的其他部件,如脉冲序列发生器、数字射频收发器等,能极大程度地提升MRI系统的集成化程度. ...
Gradient pre-emphasis to counteract first-order concomitant fields on asymmetric MRI gradient systems
1
2017
... 在梯度波形发生器中,梯度计算模块一般由将梯度坐标从逻辑空间转换为物理空间的矩阵计算、用于补偿涡流影响的预加重计算,及旨在补偿静态磁场不均匀性的一阶匀场组成. 其中,梯度预加重计算在梯度波形发生器的设计过程中至关重要,预加重计算能实时抵消涡流场导致的相位失真及图像伪影,巧妙地安排可以使其应用于各种采集策略和任意梯度波形[44]. 本文将在以下部分分析并比较实现梯度预加重的方法. ...
Simple eddy current compensation by additional gradient pulses
1
2018
... 梯度线圈中的电流随时间快速切换,将导致梯度磁场的快速变换,使周围导体在变换的磁场中产生感应电流,即涡流. 涡流的产生伴随着磁场,在成像过程中,只要打开梯度,涡流产生的磁场就会一直存在,根据楞次定律,涡流产生的磁场与原磁场相抵消[45],这些额外的磁场将在数百ms内以多指数形式衰减,并导致初始梯度的滞后. 涡流的产生将导致图像中存在严重伪影,还会导致如低温恒温器过热[46]、线性失真[47]和信噪比的损失等诸多问题. ...
Advancements in gradient system performance for clinical and research MRI
2
2022
... 梯度线圈中的电流随时间快速切换,将导致梯度磁场的快速变换,使周围导体在变换的磁场中产生感应电流,即涡流. 涡流的产生伴随着磁场,在成像过程中,只要打开梯度,涡流产生的磁场就会一直存在,根据楞次定律,涡流产生的磁场与原磁场相抵消[45],这些额外的磁场将在数百ms内以多指数形式衰减,并导致初始梯度的滞后. 涡流的产生将导致图像中存在严重伪影,还会导致如低温恒温器过热[46]、线性失真[47]和信噪比的损失等诸多问题. ...
... 现代快速脉冲序列与梯度技术结合,使得MRI系统具有更高的成像分辨率和更短的扫描时间[46],也要求梯度波形发生器同步发展. 本文基于通信速率,数字信号的处理能力,硬件集成化程度及DAC的精度等方面,分析回顾了采用DSP、FPGA及两者结合的梯度波形发生器设计方案的进展,并详细探讨了模拟预加重及数字预加重的实现方法. ...
Compensation of gradient-induced magnetic field perturbations
1
2008
... 梯度线圈中的电流随时间快速切换,将导致梯度磁场的快速变换,使周围导体在变换的磁场中产生感应电流,即涡流. 涡流的产生伴随着磁场,在成像过程中,只要打开梯度,涡流产生的磁场就会一直存在,根据楞次定律,涡流产生的磁场与原磁场相抵消[45],这些额外的磁场将在数百ms内以多指数形式衰减,并导致初始梯度的滞后. 涡流的产生将导致图像中存在严重伪影,还会导致如低温恒温器过热[46]、线性失真[47]和信噪比的损失等诸多问题. ...
Active-passive gradient shielding for MRI acoustic noise reduction
1
2005
... Classification of methods and related principles for eliminating or reducing eddy currents
Table 4 | 实现方法 | 原理 | 关键技术 | 分类 | 优势和劣势 |
抗涡流板法
| 由高电阻率材料制成,可以在一定程度上减小涡流 | 高电阻率材料 | / | 对厚度的要求严格,设计制作成本高;由于加工工艺限制,板材边缘附近仍会产生涡流[49] |
自屏蔽
梯度线圈法
| 在梯度线圈的外面加一组电流方向与其相反的线圈,使成像区域的梯度磁场满足设计需要
| 屏蔽线圈[48] | 有源屏蔽
梯度线圈 | 在相邻金属结构上的磁场泄露少,图像质量更好;占据较大的MRI扫描仪空间,且需要对梯度线圈进行特殊而复杂的设计,增加了线圈的成本和功耗 |
无源屏蔽
梯度线圈 |
梯度波形
预加重法 | 通过施加电流过驱动的方法,产生一个附加补偿磁场,以补偿涡流引起的伴随场 | RC电路+滑动变阻器/数控电位器 | 模拟
预加重法 | 数控电位器取代滑动变阻器的方法保证了数据的非易失性,且受环境等温度影响小;精度低,灵活性差[55,56] |
| DSP/FPGA结合数学物理方法 | 数字
预加重法 | 能够提高预加重精度并可以灵活扩展预加重参数的个数;占用了DAC位数[55,56] |
RC电路:指电阻-电容组成的电路. ...
一种减小梯度线圈产生的涡流的方法
2
2006
... Classification of methods and related principles for eliminating or reducing eddy currents
Table 4 | 实现方法 | 原理 | 关键技术 | 分类 | 优势和劣势 |
抗涡流板法
| 由高电阻率材料制成,可以在一定程度上减小涡流 | 高电阻率材料 | / | 对厚度的要求严格,设计制作成本高;由于加工工艺限制,板材边缘附近仍会产生涡流[49] |
自屏蔽
梯度线圈法
| 在梯度线圈的外面加一组电流方向与其相反的线圈,使成像区域的梯度磁场满足设计需要
| 屏蔽线圈[48] | 有源屏蔽
梯度线圈 | 在相邻金属结构上的磁场泄露少,图像质量更好;占据较大的MRI扫描仪空间,且需要对梯度线圈进行特殊而复杂的设计,增加了线圈的成本和功耗 |
无源屏蔽
梯度线圈 |
梯度波形
预加重法 | 通过施加电流过驱动的方法,产生一个附加补偿磁场,以补偿涡流引起的伴随场 | RC电路+滑动变阻器/数控电位器 | 模拟
预加重法 | 数控电位器取代滑动变阻器的方法保证了数据的非易失性,且受环境等温度影响小;精度低,灵活性差[55,56] |
| DSP/FPGA结合数学物理方法 | 数字
预加重法 | 能够提高预加重精度并可以灵活扩展预加重参数的个数;占用了DAC位数[55,56] |
RC电路:指电阻-电容组成的电路. ...
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
一种减小梯度线圈产生的涡流的方法
2
2006
... Classification of methods and related principles for eliminating or reducing eddy currents
Table 4 | 实现方法 | 原理 | 关键技术 | 分类 | 优势和劣势 |
抗涡流板法
| 由高电阻率材料制成,可以在一定程度上减小涡流 | 高电阻率材料 | / | 对厚度的要求严格,设计制作成本高;由于加工工艺限制,板材边缘附近仍会产生涡流[49] |
自屏蔽
梯度线圈法
| 在梯度线圈的外面加一组电流方向与其相反的线圈,使成像区域的梯度磁场满足设计需要
| 屏蔽线圈[48] | 有源屏蔽
梯度线圈 | 在相邻金属结构上的磁场泄露少,图像质量更好;占据较大的MRI扫描仪空间,且需要对梯度线圈进行特殊而复杂的设计,增加了线圈的成本和功耗 |
无源屏蔽
梯度线圈 |
梯度波形
预加重法 | 通过施加电流过驱动的方法,产生一个附加补偿磁场,以补偿涡流引起的伴随场 | RC电路+滑动变阻器/数控电位器 | 模拟
预加重法 | 数控电位器取代滑动变阻器的方法保证了数据的非易失性,且受环境等温度影响小;精度低,灵活性差[55,56] |
| DSP/FPGA结合数学物理方法 | 数字
预加重法 | 能够提高预加重精度并可以灵活扩展预加重参数的个数;占用了DAC位数[55,56] |
RC电路:指电阻-电容组成的电路. ...
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
1
2021
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
Multishield active magnetic screening of coil structures in NMR
1
1987
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
An actively shielded gradient coil design for use in planar MRI systems with limited space
1
2018
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
基于梯度电感约束和图形处理单元加速算法的磁共振双平面自屏蔽梯度线圈设计方法
1
2020
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
基于梯度电感约束和图形处理单元加速算法的磁共振双平面自屏蔽梯度线圈设计方法
1
2020
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
矩阵梯度线圈研究现状与发展趋势
1
2021
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
矩阵梯度线圈研究现状与发展趋势
1
2021
... 抗涡流板由高电阻率、高导磁率的材料制成,制作合适的抗涡流板放于主磁体与梯度线圈之间能够抑制涡流. 但抗涡流板厚度要求严格,此外,由于加工工艺限制,板材边缘附近仍会产生涡流. Shen等[49]采取减小梯度线圈半径的方法优化了抗涡流板的设计,显著减小了涡流,但线性区域也随之变小了,并且此设计需在梯度线性区域半径之间找到平衡两者的缩减系数,设计的复杂性高. 自屏蔽梯度线圈根据是否需要电流驱动工作分为无源屏蔽和有源屏蔽[50],1987年,Mansfield和Chapman提出有源屏蔽梯度线圈法用于减少梯度感应涡流[51]. 与无源屏蔽相比,有源屏蔽梯度线圈在相邻金属结构上的磁场泄露少,图像质量更好,但是,它会占据很大的空间,若为此增大磁极距离将增加磁体的成本和尺寸. 2018年,中国科学院的Wang等[52]采用逆边界元方法设计了一组用于平面MRI系统的有源屏蔽梯度线圈,设计的梯度线圈仅占据4个线圈层(通常需要6个线圈层),为患者和其他系统组件(如冷却设备及射频线圈)释放了空间. 还有研究人员将物理反问题转化为一定条件下的数学模型的数值优化问题,采用图形处理单元(Graphics Processing Unit,GPU)加速算法设计梯度线圈,降低涡流的影响[53]. 但是自屏蔽梯度线圈的设计需要对梯度线圈结构进行特殊而复杂的设计,占用空间的同时增加了线圈的成本和功耗[54]. ...
具有模拟预加重的梯度波形发生器.第十五届全国波谱学学术会议论文摘要集
3
2008
... Classification of methods and related principles for eliminating or reducing eddy currents
Table 4 | 实现方法 | 原理 | 关键技术 | 分类 | 优势和劣势 |
抗涡流板法
| 由高电阻率材料制成,可以在一定程度上减小涡流 | 高电阻率材料 | / | 对厚度的要求严格,设计制作成本高;由于加工工艺限制,板材边缘附近仍会产生涡流[49] |
自屏蔽
梯度线圈法
| 在梯度线圈的外面加一组电流方向与其相反的线圈,使成像区域的梯度磁场满足设计需要
| 屏蔽线圈[48] | 有源屏蔽
梯度线圈 | 在相邻金属结构上的磁场泄露少,图像质量更好;占据较大的MRI扫描仪空间,且需要对梯度线圈进行特殊而复杂的设计,增加了线圈的成本和功耗 |
无源屏蔽
梯度线圈 |
梯度波形
预加重法 | 通过施加电流过驱动的方法,产生一个附加补偿磁场,以补偿涡流引起的伴随场 | RC电路+滑动变阻器/数控电位器 | 模拟
预加重法 | 数控电位器取代滑动变阻器的方法保证了数据的非易失性,且受环境等温度影响小;精度低,灵活性差[55,56] |
| DSP/FPGA结合数学物理方法 | 数字
预加重法 | 能够提高预加重精度并可以灵活扩展预加重参数的个数;占用了DAC位数[55,56] |
RC电路:指电阻-电容组成的电路. ...
... [
55,
56]
RC电路:指电阻-电容组成的电路. ...
... 2009年,Xie等[55]设计了一种具有模拟预加重的梯度波形发生器,基于传统的模拟预加重微分电路,选用4个Analog Devices公司的数控电位器芯片AD5235设计了具有4组时间常数和幅度常数的预加重电路,AD5235受温度影响小,且具有非易失性. 经过对自由感应衰减(Free Induction Decay,FID)信号是否进行预加重处理的对比实验,证实了此方法起到了较好的预加重效果,但由于AD5235分辨率为1 024,即其最多只能提供1 024个抽头设定值,故能够设置的预加重参数范围有限. ...
磁共振成像系统核心——谱仪的研制开发
3
2013
... Classification of methods and related principles for eliminating or reducing eddy currents
Table 4 | 实现方法 | 原理 | 关键技术 | 分类 | 优势和劣势 |
抗涡流板法
| 由高电阻率材料制成,可以在一定程度上减小涡流 | 高电阻率材料 | / | 对厚度的要求严格,设计制作成本高;由于加工工艺限制,板材边缘附近仍会产生涡流[49] |
自屏蔽
梯度线圈法
| 在梯度线圈的外面加一组电流方向与其相反的线圈,使成像区域的梯度磁场满足设计需要
| 屏蔽线圈[48] | 有源屏蔽
梯度线圈 | 在相邻金属结构上的磁场泄露少,图像质量更好;占据较大的MRI扫描仪空间,且需要对梯度线圈进行特殊而复杂的设计,增加了线圈的成本和功耗 |
无源屏蔽
梯度线圈 |
梯度波形
预加重法 | 通过施加电流过驱动的方法,产生一个附加补偿磁场,以补偿涡流引起的伴随场 | RC电路+滑动变阻器/数控电位器 | 模拟
预加重法 | 数控电位器取代滑动变阻器的方法保证了数据的非易失性,且受环境等温度影响小;精度低,灵活性差[55,56] |
| DSP/FPGA结合数学物理方法 | 数字
预加重法 | 能够提高预加重精度并可以灵活扩展预加重参数的个数;占用了DAC位数[55,56] |
RC电路:指电阻-电容组成的电路. ...
... ,
56]
RC电路:指电阻-电容组成的电路. ...
... 使用数控电位器替代滑动变阻器的方法能简化参数调整流程[56],但数控电位器存在所需模拟元器件过多及精度不足等缺点. 早期的预加重模块与梯度波形发生器分离,在集成度、精度及稳定度上都有不足. 如今,数字集成电路和信号处理技术迅猛发展,它们是航空航天、医疗器械、通信设备等的核心部分[57],采用数字技术实现预加重取得了诸多进展. 研究人员在设计梯度波形发生器时,通常将预加重部分集成在梯度波形发生器相应芯片当中,提升了系统的稳定性,降低了系统的复杂程度. ...
磁共振成像系统核心——谱仪的研制开发
3
2013
... Classification of methods and related principles for eliminating or reducing eddy currents
Table 4 | 实现方法 | 原理 | 关键技术 | 分类 | 优势和劣势 |
抗涡流板法
| 由高电阻率材料制成,可以在一定程度上减小涡流 | 高电阻率材料 | / | 对厚度的要求严格,设计制作成本高;由于加工工艺限制,板材边缘附近仍会产生涡流[49] |
自屏蔽
梯度线圈法
| 在梯度线圈的外面加一组电流方向与其相反的线圈,使成像区域的梯度磁场满足设计需要
| 屏蔽线圈[48] | 有源屏蔽
梯度线圈 | 在相邻金属结构上的磁场泄露少,图像质量更好;占据较大的MRI扫描仪空间,且需要对梯度线圈进行特殊而复杂的设计,增加了线圈的成本和功耗 |
无源屏蔽
梯度线圈 |
梯度波形
预加重法 | 通过施加电流过驱动的方法,产生一个附加补偿磁场,以补偿涡流引起的伴随场 | RC电路+滑动变阻器/数控电位器 | 模拟
预加重法 | 数控电位器取代滑动变阻器的方法保证了数据的非易失性,且受环境等温度影响小;精度低,灵活性差[55,56] |
| DSP/FPGA结合数学物理方法 | 数字
预加重法 | 能够提高预加重精度并可以灵活扩展预加重参数的个数;占用了DAC位数[55,56] |
RC电路:指电阻-电容组成的电路. ...
... ,
56]
RC电路:指电阻-电容组成的电路. ...
... 使用数控电位器替代滑动变阻器的方法能简化参数调整流程[56],但数控电位器存在所需模拟元器件过多及精度不足等缺点. 早期的预加重模块与梯度波形发生器分离,在集成度、精度及稳定度上都有不足. 如今,数字集成电路和信号处理技术迅猛发展,它们是航空航天、医疗器械、通信设备等的核心部分[57],采用数字技术实现预加重取得了诸多进展. 研究人员在设计梯度波形发生器时,通常将预加重部分集成在梯度波形发生器相应芯片当中,提升了系统的稳定性,降低了系统的复杂程度. ...
Development of DC parameter calibration module for digital integrated circuit test system
1
2023
... 使用数控电位器替代滑动变阻器的方法能简化参数调整流程[56],但数控电位器存在所需模拟元器件过多及精度不足等缺点. 早期的预加重模块与梯度波形发生器分离,在集成度、精度及稳定度上都有不足. 如今,数字集成电路和信号处理技术迅猛发展,它们是航空航天、医疗器械、通信设备等的核心部分[57],采用数字技术实现预加重取得了诸多进展. 研究人员在设计梯度波形发生器时,通常将预加重部分集成在梯度波形发生器相应芯片当中,提升了系统的稳定性,降低了系统的复杂程度. ...
一种具有自触发功能的高精度梯度波形发生器
1
2007
... 自2000年起,不断有研究人员在梯度波形数字预加重设计中提供新方法. 2007年,Liu等[58]使用PC机通过PCI总线配置在FPGA内部构建的寄存器,用以改变预加重的时间与幅度常数,但预加重的通道仅有三路,对梯度涡流的补偿不足. 2008年,Zang等[59]提出利用MR信号测量涡流后,经过拟合、迭代寻找最佳涡流补偿参数的方法,但是该方法首先得确定样品信号区,需要耗时10 min才能得到较好的预加重补偿效果. 2010年,Xiao等[24]采取在FPGA内部使用快速无限冲激响应滤波器(Infinite Impulse Response Filter,IIR)滤波器算法对原始梯度波形叠加过驱动的方法,实现对涡流的预加重处理,但随着迭代次数增加,累计误差也逐渐增加. 2011年,Pan等[6]针对Xiao等[24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
一种具有自触发功能的高精度梯度波形发生器
1
2007
... 自2000年起,不断有研究人员在梯度波形数字预加重设计中提供新方法. 2007年,Liu等[58]使用PC机通过PCI总线配置在FPGA内部构建的寄存器,用以改变预加重的时间与幅度常数,但预加重的通道仅有三路,对梯度涡流的补偿不足. 2008年,Zang等[59]提出利用MR信号测量涡流后,经过拟合、迭代寻找最佳涡流补偿参数的方法,但是该方法首先得确定样品信号区,需要耗时10 min才能得到较好的预加重补偿效果. 2010年,Xiao等[24]采取在FPGA内部使用快速无限冲激响应滤波器(Infinite Impulse Response Filter,IIR)滤波器算法对原始梯度波形叠加过驱动的方法,实现对涡流的预加重处理,但随着迭代次数增加,累计误差也逐渐增加. 2011年,Pan等[6]针对Xiao等[24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
磁共振成像系统中的自动梯度预加重调节方法研究
1
2008
... 自2000年起,不断有研究人员在梯度波形数字预加重设计中提供新方法. 2007年,Liu等[58]使用PC机通过PCI总线配置在FPGA内部构建的寄存器,用以改变预加重的时间与幅度常数,但预加重的通道仅有三路,对梯度涡流的补偿不足. 2008年,Zang等[59]提出利用MR信号测量涡流后,经过拟合、迭代寻找最佳涡流补偿参数的方法,但是该方法首先得确定样品信号区,需要耗时10 min才能得到较好的预加重补偿效果. 2010年,Xiao等[24]采取在FPGA内部使用快速无限冲激响应滤波器(Infinite Impulse Response Filter,IIR)滤波器算法对原始梯度波形叠加过驱动的方法,实现对涡流的预加重处理,但随着迭代次数增加,累计误差也逐渐增加. 2011年,Pan等[6]针对Xiao等[24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
磁共振成像系统中的自动梯度预加重调节方法研究
1
2008
... 自2000年起,不断有研究人员在梯度波形数字预加重设计中提供新方法. 2007年,Liu等[58]使用PC机通过PCI总线配置在FPGA内部构建的寄存器,用以改变预加重的时间与幅度常数,但预加重的通道仅有三路,对梯度涡流的补偿不足. 2008年,Zang等[59]提出利用MR信号测量涡流后,经过拟合、迭代寻找最佳涡流补偿参数的方法,但是该方法首先得确定样品信号区,需要耗时10 min才能得到较好的预加重补偿效果. 2010年,Xiao等[24]采取在FPGA内部使用快速无限冲激响应滤波器(Infinite Impulse Response Filter,IIR)滤波器算法对原始梯度波形叠加过驱动的方法,实现对涡流的预加重处理,但随着迭代次数增加,累计误差也逐渐增加. 2011年,Pan等[6]针对Xiao等[24]在梯度计算过程中数据精度只有16 bit和24 bit的问题,提出了基于高性能DSP的数字预加重设计,使得计算过程中数据精度达到32 bit和40 bit,对梯度波形数据的计算速度也提升了三倍多. 但在此设计中由DSP输出的预加重处理后的数据,还需传输到FPGA进行并串转换及实现对DAC的控制,增加了系统的开发难度. ...
基于高精度磁共振梯度卡的数字涡流预补偿方法
1
2020
... 针对以上问题,2020年,Yang等[60]使用FPGA实现对标准波形的读取,预补偿(包含预加重及欠补偿)计算及DAC的控制,采用DSP设计工具DSP Builder在Simulink环境中搭建数字运算模型,然后直接生成HDL语言. 由FPGA实时对标准波形数值进行计算得到补偿波形,在预补偿计算模块后接入比例分压网络,再由两个位宽为20 bit的DAC芯片AD5791分别输出补偿波形及标准梯度波形,最后于模拟域中将两者叠加得到补偿后的波形,实现了具有五组幅度常数及时间常数的预补偿算法. 目前的DAC在时间分辨率达到标称值时,无法满足幅度分辨率高于其标称值[61],而在预补偿计算模块后加入比例分压电路,使得时间分辨率达到DAC标称值的情况下,幅度分辨率提高了3.3 bit,提高了预补偿的效果. 此外,数字预加重的设计会引入梯度信号在时间上的抖动问题,导致图像伪影[62],该设计在触发信号到来时,会为预补偿计算预留ns级别足够计算的时间后才更新DAC输出时钟的有效边沿,避免了因时间抖动产生的图像伪影,具有高精度、低延时的优点. 但选用的DAC位宽仅20 bit,若需进行一阶匀场及直流偏置等梯度计算,则难以满足使用需求. 此外,该设计只对空间分布中的一阶涡流进行了处理,并未处理高阶涡流及交叉项等涡流,对涡流的补偿存在一定不足. ...
基于高精度磁共振梯度卡的数字涡流预补偿方法
1
2020
... 针对以上问题,2020年,Yang等[60]使用FPGA实现对标准波形的读取,预补偿(包含预加重及欠补偿)计算及DAC的控制,采用DSP设计工具DSP Builder在Simulink环境中搭建数字运算模型,然后直接生成HDL语言. 由FPGA实时对标准波形数值进行计算得到补偿波形,在预补偿计算模块后接入比例分压网络,再由两个位宽为20 bit的DAC芯片AD5791分别输出补偿波形及标准梯度波形,最后于模拟域中将两者叠加得到补偿后的波形,实现了具有五组幅度常数及时间常数的预补偿算法. 目前的DAC在时间分辨率达到标称值时,无法满足幅度分辨率高于其标称值[61],而在预补偿计算模块后加入比例分压电路,使得时间分辨率达到DAC标称值的情况下,幅度分辨率提高了3.3 bit,提高了预补偿的效果. 此外,数字预加重的设计会引入梯度信号在时间上的抖动问题,导致图像伪影[62],该设计在触发信号到来时,会为预补偿计算预留ns级别足够计算的时间后才更新DAC输出时钟的有效边沿,避免了因时间抖动产生的图像伪影,具有高精度、低延时的优点. 但选用的DAC位宽仅20 bit,若需进行一阶匀场及直流偏置等梯度计算,则难以满足使用需求. 此外,该设计只对空间分布中的一阶涡流进行了处理,并未处理高阶涡流及交叉项等涡流,对涡流的补偿存在一定不足. ...
1
... 针对以上问题,2020年,Yang等[60]使用FPGA实现对标准波形的读取,预补偿(包含预加重及欠补偿)计算及DAC的控制,采用DSP设计工具DSP Builder在Simulink环境中搭建数字运算模型,然后直接生成HDL语言. 由FPGA实时对标准波形数值进行计算得到补偿波形,在预补偿计算模块后接入比例分压网络,再由两个位宽为20 bit的DAC芯片AD5791分别输出补偿波形及标准梯度波形,最后于模拟域中将两者叠加得到补偿后的波形,实现了具有五组幅度常数及时间常数的预补偿算法. 目前的DAC在时间分辨率达到标称值时,无法满足幅度分辨率高于其标称值[61],而在预补偿计算模块后加入比例分压电路,使得时间分辨率达到DAC标称值的情况下,幅度分辨率提高了3.3 bit,提高了预补偿的效果. 此外,数字预加重的设计会引入梯度信号在时间上的抖动问题,导致图像伪影[62],该设计在触发信号到来时,会为预补偿计算预留ns级别足够计算的时间后才更新DAC输出时钟的有效边沿,避免了因时间抖动产生的图像伪影,具有高精度、低延时的优点. 但选用的DAC位宽仅20 bit,若需进行一阶匀场及直流偏置等梯度计算,则难以满足使用需求. 此外,该设计只对空间分布中的一阶涡流进行了处理,并未处理高阶涡流及交叉项等涡流,对涡流的补偿存在一定不足. ...
在数字化MRI谱仪系统设计中消除梯度抖动的方法
1
2008
... 针对以上问题,2020年,Yang等[60]使用FPGA实现对标准波形的读取,预补偿(包含预加重及欠补偿)计算及DAC的控制,采用DSP设计工具DSP Builder在Simulink环境中搭建数字运算模型,然后直接生成HDL语言. 由FPGA实时对标准波形数值进行计算得到补偿波形,在预补偿计算模块后接入比例分压网络,再由两个位宽为20 bit的DAC芯片AD5791分别输出补偿波形及标准梯度波形,最后于模拟域中将两者叠加得到补偿后的波形,实现了具有五组幅度常数及时间常数的预补偿算法. 目前的DAC在时间分辨率达到标称值时,无法满足幅度分辨率高于其标称值[61],而在预补偿计算模块后加入比例分压电路,使得时间分辨率达到DAC标称值的情况下,幅度分辨率提高了3.3 bit,提高了预补偿的效果. 此外,数字预加重的设计会引入梯度信号在时间上的抖动问题,导致图像伪影[62],该设计在触发信号到来时,会为预补偿计算预留ns级别足够计算的时间后才更新DAC输出时钟的有效边沿,避免了因时间抖动产生的图像伪影,具有高精度、低延时的优点. 但选用的DAC位宽仅20 bit,若需进行一阶匀场及直流偏置等梯度计算,则难以满足使用需求. 此外,该设计只对空间分布中的一阶涡流进行了处理,并未处理高阶涡流及交叉项等涡流,对涡流的补偿存在一定不足. ...
在数字化MRI谱仪系统设计中消除梯度抖动的方法
1
2008
... 针对以上问题,2020年,Yang等[60]使用FPGA实现对标准波形的读取,预补偿(包含预加重及欠补偿)计算及DAC的控制,采用DSP设计工具DSP Builder在Simulink环境中搭建数字运算模型,然后直接生成HDL语言. 由FPGA实时对标准波形数值进行计算得到补偿波形,在预补偿计算模块后接入比例分压网络,再由两个位宽为20 bit的DAC芯片AD5791分别输出补偿波形及标准梯度波形,最后于模拟域中将两者叠加得到补偿后的波形,实现了具有五组幅度常数及时间常数的预补偿算法. 目前的DAC在时间分辨率达到标称值时,无法满足幅度分辨率高于其标称值[61],而在预补偿计算模块后加入比例分压电路,使得时间分辨率达到DAC标称值的情况下,幅度分辨率提高了3.3 bit,提高了预补偿的效果. 此外,数字预加重的设计会引入梯度信号在时间上的抖动问题,导致图像伪影[62],该设计在触发信号到来时,会为预补偿计算预留ns级别足够计算的时间后才更新DAC输出时钟的有效边沿,避免了因时间抖动产生的图像伪影,具有高精度、低延时的优点. 但选用的DAC位宽仅20 bit,若需进行一阶匀场及直流偏置等梯度计算,则难以满足使用需求. 此外,该设计只对空间分布中的一阶涡流进行了处理,并未处理高阶涡流及交叉项等涡流,对涡流的补偿存在一定不足. ...
1
2015
... 大多数情况下,梯度波形预加重至少要提供4组预加重参数. 梯度波形预加重的主要指标是时间常数与幅度常数,传统采用滑动变阻器设计模拟预加重的方法已逐步被淘汰,而采用数字电位器,相比使用滑动变阻器的方法而言具有可重复性强、受环境影响小及精度高的优点. 但数字电位器的数据字除包含数据位,还包含地址位和指令位,能够设置的预加重参数范围有限. 此外,虽然不同的电位器内部结构不同,但均可根据电路结构计算时间常数和幅度常数,即时间常数及幅度常数的取值由电路结构及其包含的元器件直接决定,能取的值十分有限. 数字预加重的使用能提高预加重的精度,且能灵活扩展预加重参数的个数并缩短预加重耗时. 但一方面,数字预加重对进行梯度预加重计算的芯片资源要求较高,因为梯度预加重通常需要做到至少4组预加重参数,但若DSP或FPGA等芯片本身资源已被梯度波形发生器高度利用,则无法具有充足资源用于生成足够降低涡流的预加重参数. 另一方面,数字预加重的引入会导致梯度波形的幅度抖动与时间抖动,可能导致成像的伪影及梯度波形输出的延迟. 此外,原始波形数据需要经过梯度计算等处理后进入DAC,而数字预加重会占用1~2 bit DAC位数[7],导致梯度波形发生器输出的波形分辨率降低[63,64]. 而模拟预加重是对DAC输出的梯度波形进行预加重处理,不占用DAC的位数,故模拟预加重也有其一定的优势. ...
具有预失真功能的梯度波形发生器
1
2015
... 大多数情况下,梯度波形预加重至少要提供4组预加重参数. 梯度波形预加重的主要指标是时间常数与幅度常数,传统采用滑动变阻器设计模拟预加重的方法已逐步被淘汰,而采用数字电位器,相比使用滑动变阻器的方法而言具有可重复性强、受环境影响小及精度高的优点. 但数字电位器的数据字除包含数据位,还包含地址位和指令位,能够设置的预加重参数范围有限. 此外,虽然不同的电位器内部结构不同,但均可根据电路结构计算时间常数和幅度常数,即时间常数及幅度常数的取值由电路结构及其包含的元器件直接决定,能取的值十分有限. 数字预加重的使用能提高预加重的精度,且能灵活扩展预加重参数的个数并缩短预加重耗时. 但一方面,数字预加重对进行梯度预加重计算的芯片资源要求较高,因为梯度预加重通常需要做到至少4组预加重参数,但若DSP或FPGA等芯片本身资源已被梯度波形发生器高度利用,则无法具有充足资源用于生成足够降低涡流的预加重参数. 另一方面,数字预加重的引入会导致梯度波形的幅度抖动与时间抖动,可能导致成像的伪影及梯度波形输出的延迟. 此外,原始波形数据需要经过梯度计算等处理后进入DAC,而数字预加重会占用1~2 bit DAC位数[7],导致梯度波形发生器输出的波形分辨率降低[63,64]. 而模拟预加重是对DAC输出的梯度波形进行预加重处理,不占用DAC的位数,故模拟预加重也有其一定的优势. ...
具有预失真功能的梯度波形发生器
1
2015
... 大多数情况下,梯度波形预加重至少要提供4组预加重参数. 梯度波形预加重的主要指标是时间常数与幅度常数,传统采用滑动变阻器设计模拟预加重的方法已逐步被淘汰,而采用数字电位器,相比使用滑动变阻器的方法而言具有可重复性强、受环境影响小及精度高的优点. 但数字电位器的数据字除包含数据位,还包含地址位和指令位,能够设置的预加重参数范围有限. 此外,虽然不同的电位器内部结构不同,但均可根据电路结构计算时间常数和幅度常数,即时间常数及幅度常数的取值由电路结构及其包含的元器件直接决定,能取的值十分有限. 数字预加重的使用能提高预加重的精度,且能灵活扩展预加重参数的个数并缩短预加重耗时. 但一方面,数字预加重对进行梯度预加重计算的芯片资源要求较高,因为梯度预加重通常需要做到至少4组预加重参数,但若DSP或FPGA等芯片本身资源已被梯度波形发生器高度利用,则无法具有充足资源用于生成足够降低涡流的预加重参数. 另一方面,数字预加重的引入会导致梯度波形的幅度抖动与时间抖动,可能导致成像的伪影及梯度波形输出的延迟. 此外,原始波形数据需要经过梯度计算等处理后进入DAC,而数字预加重会占用1~2 bit DAC位数[7],导致梯度波形发生器输出的波形分辨率降低[63,64]. 而模拟预加重是对DAC输出的梯度波形进行预加重处理,不占用DAC的位数,故模拟预加重也有其一定的优势. ...
一种永磁磁共振中磁体涡流场的测量方法
1
2018
... 目前较多MRI设备的梯度波形发生器由FPGA或DSP+FPGA结合的方式设计,DSP与FPGA的性能提升为梯度波形发生器的设计提供了更多选择. 此外,具有嵌入式DSP的FPGA设计、内嵌FPGA的DSP芯片已逐步量产,如Xilinx公司研制的内嵌DSP的FPGA芯片Virtex-7系列,含有上千片DSP,不论是系统性能、信号处理速度还是功耗与成本均有所突破. CEVA公司和FLEX LOGIX公司于2022年推出的内嵌FPGA的DSP芯片EFLX eFPGA支持灵活添加与更改指令集. 这些设计及产品结合了DSP与FPGA各自的优点,将它们用于设计梯度波形发生器将使系统集成度、稳定性及速度等方面均有所提升[65]. 此外,片上系统SoC的不断发展也为设计梯度波形发生器提供了新思路,SoC集成了FPGA架构及运行Linux操作系统的ARM处理器,可以在其中集成第三方提供的IP核,两者之间采用AXI通信保障了传输的吞吐量及可预测性,有助于缩短梯度波形发生器的研发周期及保障传输可靠性. 对于梯度预加重处理模块,软硬件的更新迭代除了使其制作成本降低外,其参数精度、计算速度等方面也有所提升,各种数学、物理方法的引入也将为梯度预加重提供更多选择. 随着梯度波形发生器相关软硬件技术的发展及各种数学、物理方法的引入[66],梯度波形发生器的设计将来有望朝着更高集成度、更低成本、更优精度及更快速度等方向发展,也将使MRI成为一种更有竞争力的临床工具. ...
一种永磁磁共振中磁体涡流场的测量方法
1
2018
... 目前较多MRI设备的梯度波形发生器由FPGA或DSP+FPGA结合的方式设计,DSP与FPGA的性能提升为梯度波形发生器的设计提供了更多选择. 此外,具有嵌入式DSP的FPGA设计、内嵌FPGA的DSP芯片已逐步量产,如Xilinx公司研制的内嵌DSP的FPGA芯片Virtex-7系列,含有上千片DSP,不论是系统性能、信号处理速度还是功耗与成本均有所突破. CEVA公司和FLEX LOGIX公司于2022年推出的内嵌FPGA的DSP芯片EFLX eFPGA支持灵活添加与更改指令集. 这些设计及产品结合了DSP与FPGA各自的优点,将它们用于设计梯度波形发生器将使系统集成度、稳定性及速度等方面均有所提升[65]. 此外,片上系统SoC的不断发展也为设计梯度波形发生器提供了新思路,SoC集成了FPGA架构及运行Linux操作系统的ARM处理器,可以在其中集成第三方提供的IP核,两者之间采用AXI通信保障了传输的吞吐量及可预测性,有助于缩短梯度波形发生器的研发周期及保障传输可靠性. 对于梯度预加重处理模块,软硬件的更新迭代除了使其制作成本降低外,其参数精度、计算速度等方面也有所提升,各种数学、物理方法的引入也将为梯度预加重提供更多选择. 随着梯度波形发生器相关软硬件技术的发展及各种数学、物理方法的引入[66],梯度波形发生器的设计将来有望朝着更高集成度、更低成本、更优精度及更快速度等方向发展,也将使MRI成为一种更有竞争力的临床工具. ...
Automatic gradient pre-emphasis adjustment for permanent MRI system
1
2019
... 目前较多MRI设备的梯度波形发生器由FPGA或DSP+FPGA结合的方式设计,DSP与FPGA的性能提升为梯度波形发生器的设计提供了更多选择. 此外,具有嵌入式DSP的FPGA设计、内嵌FPGA的DSP芯片已逐步量产,如Xilinx公司研制的内嵌DSP的FPGA芯片Virtex-7系列,含有上千片DSP,不论是系统性能、信号处理速度还是功耗与成本均有所突破. CEVA公司和FLEX LOGIX公司于2022年推出的内嵌FPGA的DSP芯片EFLX eFPGA支持灵活添加与更改指令集. 这些设计及产品结合了DSP与FPGA各自的优点,将它们用于设计梯度波形发生器将使系统集成度、稳定性及速度等方面均有所提升[65]. 此外,片上系统SoC的不断发展也为设计梯度波形发生器提供了新思路,SoC集成了FPGA架构及运行Linux操作系统的ARM处理器,可以在其中集成第三方提供的IP核,两者之间采用AXI通信保障了传输的吞吐量及可预测性,有助于缩短梯度波形发生器的研发周期及保障传输可靠性. 对于梯度预加重处理模块,软硬件的更新迭代除了使其制作成本降低外,其参数精度、计算速度等方面也有所提升,各种数学、物理方法的引入也将为梯度预加重提供更多选择. 随着梯度波形发生器相关软硬件技术的发展及各种数学、物理方法的引入[66],梯度波形发生器的设计将来有望朝着更高集成度、更低成本、更优精度及更快速度等方向发展,也将使MRI成为一种更有竞争力的临床工具. ...



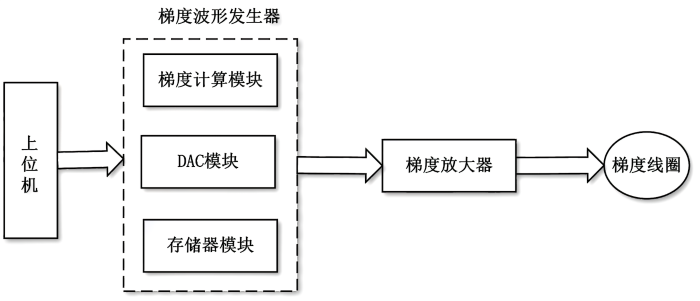


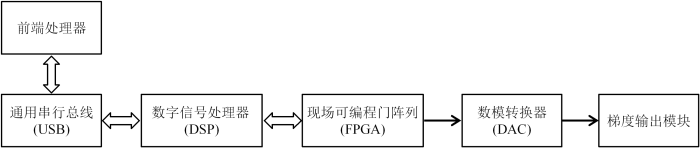
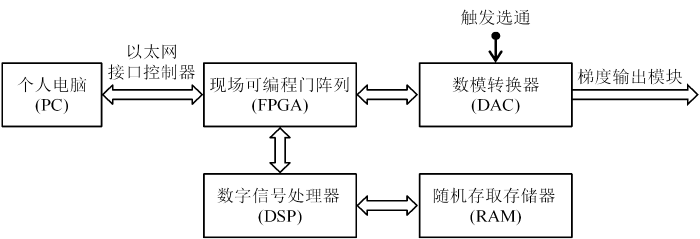
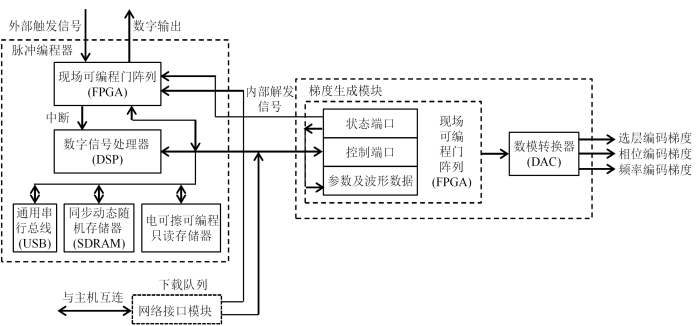
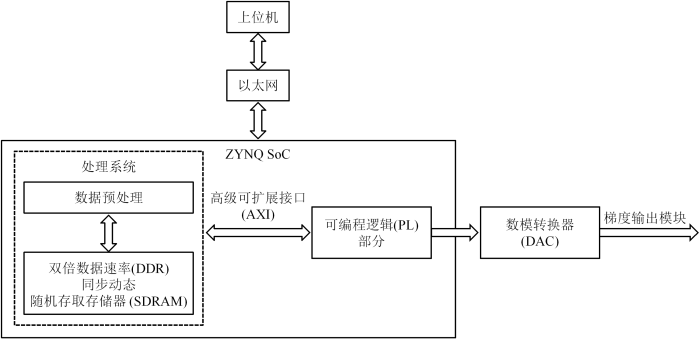


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}