


引 言
RA的早期诊断对治疗和预后影响重大,临床医师需结合患者的临床表现、实验室和影像学检查做出诊断. 选用合适的辅助诊断手段,可减少诊断经验少的医师对部分患者的诊断误差. 具有较高组织对比度的磁共振成像(Magnetic Resonance Image,MRI)作为检测早期RA病变最敏感的工具,可比常规放射检查更早地检测到滑膜炎、关节间隙狭窄、骨侵蚀等症状. 同时对一些横截面组织产生较为立体的观察,对患者的治疗指向性更强,且无电离辐射的伤害[3].
对感兴趣的器官和结构进行精确分割,是从医学图像中提取定量分析指标、执行计算机辅助诊断决策等任务不可或缺的前提. 对滑膜磁共振图像进行分割,有助于在RA诊断和治疗期间对滑膜炎患者的滑膜体积进行准确评估. 然而不同的磁共振成像序列对于滑膜的检出率不尽相同,在T1WI和T2WI常规序列中滑膜组织呈等或稍高信号,边界不清晰;层厚较厚时容易出现部分容积效应,导致一个体素的信号表现为多种组织信号的平均值,包裹积液的滑膜组织,与周围的肌肉组织、积液之间存在边界对比度较弱、灰度不均匀等现象,因此膝关节滑膜分割任务十分具有挑战性.
近年来,基于深度学习的方法已经成为许多医学图像分割和分类任务的主流方法. 在超声图像的应用方面,Andersen等[10]首次利用卷积神经网络(Convolution Neural Network,CNN)对RA患者手腕关节超声图像滑膜炎的严重程度进行简单分类;Christensen等[11]针对EULAR-OMERACT滑膜炎超声评分系统,设计了级联的CNN网络进行RA自动分级,进一步提升滑膜炎严重程度分类的准确性. 在磁共振图像应用方面,Iqbal等[12]利用改进的CNN进行迁移学习自动检测T2序列膝关节磁共振图像中的滑膜积液;Wong等[13]利用UNet对T2W脂肪抑制序列的手腕关节磁共振图像的腕部骨骼进行分割;本课题组初步进行了利用改进的UNet系列网络对T1W序列手腕关节磁共振图像的滑膜进行分割的研究[14,15],但由于卷积运算只关注局部信息的局限性,对于滑膜的纹理和形状个体差异较大的病例分割效果较差.此外,上述研究[12-15]均使用2D卷积核进行分割,缺少对于切片间连续信息的特征学习.
本文选用针对三维医学图像数据设计的使用3D卷积核进行整体分割的VNet网络.另外,滑模分割任务的个体差异较大的特点与脑肿瘤分割任务的特点相似,因此本文参考脑肿瘤分割任务中表现较好的TransBTS[16]网络,引入对长距离关系建模的Transformer结构,对全局信息进行特征提取. 本文探究了膝关节滑膜分割任务下CNN-Transformer结构的潜力,提出一种基于改进的VNet网络的膝关节滑膜分割算法,对滑膜磁共振图像进行3D分割.
1 理论部分
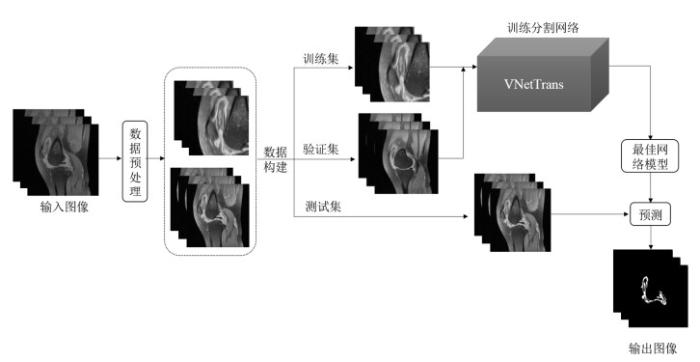
本文在TransBTS的基础上改进,提出了一种结合VNet网络和Transformer编码器的深度学习网络模型—VNetTrans网络,用于实现膝关节滑膜磁共振图像的自动3D分割. 该方法的流程如图1所示,包含以下步骤:1)预处理阶段,对原始膝关节磁共振图像进行统一分辨率和方位、归一化、直方图均衡化操作;对于训练集数据进行ROI的裁剪和数据增强,扩充训练数据,增加样本多样性;2)训练阶段,搭建VNetTrans网络,训练网络得到最佳模型;3)利用最佳模型对测试集进行分割.
图1
1.1 VNet网络
在2D分割方面,完全卷积神经网络(Fully Convolutional Network,FCN)首次实现端到端的语义分割,遵循编码器-解码器的网络结构,可对输入的任意尺寸的图像进行语义分割[17]. 进一步改进和发展的UNet网络[18]采用对称的编码解码结构,添加了跳跃连接,将低分辨率和高分辨率的特征图进行融合以提高细节保留率,从而成为医学图像分割的主流框架. 然而计算机断层扫描(Computed Tomography,CT)和磁共振图像等大多数医学数据都以3D形式存在,因此使用3D卷积核可更好地挖掘数据的高维空间相关性. 3D UNet[19]将UNet架构直接扩展应用到3D数据. 但由于计算资源的限制,该网络只包含三次下采样,无法有效提取深层图像信息,导致分割精度有限.
VNet[20]作为3D UNet网络的变体,针对3D UNet分割精度有限的问题,利用残差连接设计了更深层次的网络(采用4次下采样),从而实现更高的分割性能. VNet网络左侧的下采样路径可分为若干阶段,每个阶段由1~3个卷积层对不同分辨率的特征图进行编码提取特征. 卷积过程中利用了残差连接的思路,前层的特征图与其在本阶段卷积后的特征图相加. 与UNet对称的编码解码结构类似,上采样路径采用跳跃连接融合左侧下采样过程中的特征图,通过该方式收集在压缩路径中丢失的细粒度细节.
1.2 Transformer编码器
尽管基于CNN的方法有很好的效果,但由于卷积核的感受野有限,很难充分利用上下文信息来对目标建立长距离依赖关系. 卷积运算的局限性给全局语义信息的学习带来挑战,然而对于分割任务而言,全局语义信息至关重要. 受启发于自然语言处理领域中的注意力机制[21],Vision Transformer[22]直接将图片分割为小块,仅利用具有全局自注意力机制的Transformer为不同图像块的相关性进行建模,对图像序列进行分类.Transformer完全基于注意力机制而摒弃了卷积操作,在建模全局上下文方面功能强大. 该编码器主要包含多层感知器(Multi-Layer Perceptron,MLP)和多头注意力机制(Multi-Head Attention,MHA)两个子结构. 每个子结构前进行层标准化(Layer Norm),子结构后添加残差连接,如图2(a)所示.
图2

MLP是人工神经网络的基本形式,由输入层、隐藏层、输出层三层基本结构组成,映射一组输入向量到输出向量. 图2(b)中MHA的核心为注意力机制(Attention),注意力机制将需要编码的特征向量,分别与三个权重矩阵
式中
式中
1.3 激活函数
Hinton等[23]提出的ReLU激活函数表达式简单,易于求导,但由于函数负半轴梯度始终为0,在学习率设定较大时会发生神经元坏死的情况.
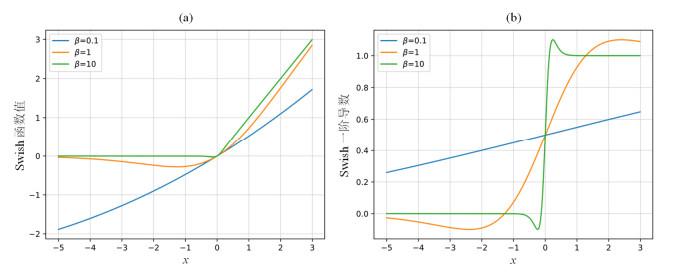
Swish函数[24]是由Google Brain提出的效果优于ReLU的激活函数,对其负值部分进行了优化. 通过自适应学习参数在负半轴添加一个很小的线性分量,来缓解负值的零梯度问题,其数学表达如(3)式所示:
β为常数或可训练参数,不同β取值的函数图像及其一阶导数如图3所示. 可看到当β趋向于0时,Swish函数变成线性函数;当β趋向正无穷时,
图3
本文选用的MemSwish激活函数参考了EfficientNet[25]的实现思路,重新设计了Swish激活函数在反向传播过程中的计算方式,使得前向传播过程中的计算量得以保存,并可被重构在反向传播过程中再使用,避免了重复计算造成的资源浪费及显存占用. 相比于使用Swish激活函数,MemSwish激活函数可在训练过程中节约10%~30%的显存占用.
1.4 VNetTrans网络
对于需要密集预测像素点的分割任务,局部和全局信息都很重要. 若单纯利用Transformer对分割的图像块进行编码,将二维图像转换为一维序列,所有阶段只关注于对全局上下文建模,将缺乏详细定位信息的低分辨率特征直接上采样到全分辨率特征图时,会无法有效恢复相关定位信息而导致分割结果粗糙[26]. 对3D MRI扫描数据连续切片间的局部特征进行建模也是图像分割的关键. 基于CNN架构的网络可以提供一种提取底层视觉线索的方法,很好弥补精细的空间信息. 由此本文尝试采用CNN-Transformer的架构,综合利用来自CNN编码的局部空间信息和Transformer编码的全局上下文信息. 参考TransBTS,提出VNetTrans网络对膝关节滑膜磁共振图像进行3D分割,网络结构如图4所示.
图4
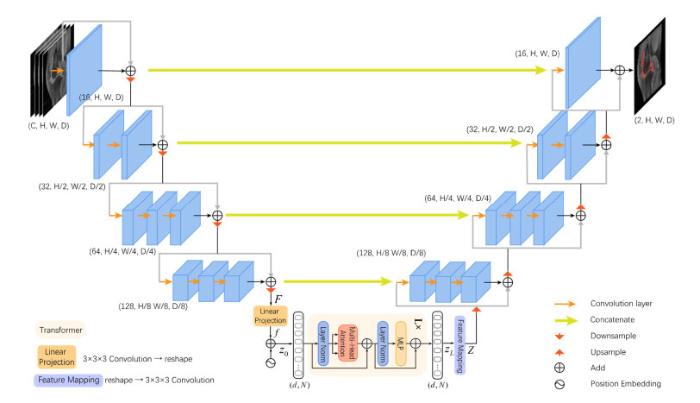
TransBTS在编码过程中仅进行3次下采样且每层卷积次数为固定2次;本文选择将CNN左侧编码器进行4次下采样(Downsample),在下采样路径中的不同阶段,由1~3个卷积层(Convolution layer)对不同分辨率的特征图进行特征提取;在每一层的编码器添加残差块,将输入每个阶段的特征图与其在本阶段卷积后的特征图相加(Add),增加模型深度的同时确保模型有效收敛;并且使用MemSwish激活函数,提高模型的非线性表达能力,提升模型整体的分割性能.
输入的3D膝关节磁共振图像维度为
Transformer编码器由L层编码器组成,每层编码器都有一个标准结构,由一个MHA子结构和一个MLP子结构组成. 选用编码器层数L为4,MHA中的头部数量h为8,序列化编码的图像块大小P为16.
其中,LN(Layer Normalization)表示进行层标准化,
为拟合3D CNN解码器的输入维度,将上文Transformer编码器输出的序列化特征图
2 实验部分
2.1 实验数据
本文所用数据来自于上海市光华中西医结合医院2021年2月至2022年1月收治的膝关节受损的患者共40例,全部患者行MRI检查. 检查前均对病人告知检查内容,获得其同意并签署知情同意书. 患者中男性11例,女性29;年龄分布为37~87岁,均值为62岁;患类风关的病人31例,患关节痛病人6例,患半月板损伤2例和尪痹1例. 除一例发生严重骨侵蚀,滑膜组织所剩无几的类风关晚期患者外,共39例病例纳入研究. 按病例进行数据拆分,同一病例的所有图像属于同一数据集,以近似75:12.5:12.5的比例分为训练集、验证集和测试集.
MRI扫描由影像科医生负责操作. 图像采集使用Siemens Avanto 1.5 T MRI扫描仪,采用为满足本项目研究而定制的基于FLAIR和STIR优化的PD序列. 扫描参数为:回波时间TE=21 ms,重复时间TR=10 420 ms,反转时间TI=2 200 ms,视野FOV=160 mm×160 mm,扫描层厚=3 mm,单层图像尺寸=256×256,方位为冠状位,扫描层数为20~23. 所用图像存储格式为DICOM格式,由放射科一名副主任医师和两名主治医师利用ITK-SNAP[27]对滑膜进行手工勾画标注作为金标准.
2.2 图像分割
先将DICOM格式的图像统一转化为标准的NIFTI格式并压缩;然后将所有病例样本体素重采样为0.625×0.625×3.6 mm3统一图像分辨率,调整图像方位统一为下-后-右(Inferior-Posterior-Right);再将图像灰度值归一化处理到
在数据预处理过程中,本文对不同图像对比度增强方法的处理效果进行了对比.图5(b)直接进行简单的直方图对比度拉伸,结果显示相比原始图像,滑膜与周围其他组织之间对比度区分不大. 图5(c)使用传统的直方图均衡化进行图像增强,当图像存在明显的暗区像素值分布不均衡时放大了噪声. 以图5(d)箭头所指髌上囊处、滑膜皱褶处和股骨软骨周围处为例,CLAHE算法可在增强图像对比度同时较好的抑制噪声,使得滑膜局部细节更为清晰和明显. 图5第二行4幅图中的红色曲线为累积分布函数(Cumulative Distribution Function,CDF),代表直方图的积分;对比原始图像,在保留了图像原有特征的基础上,图5(d)对应图像下方的黑色直方图整体分布更为均衡,CDF曲线更加平滑.
图5
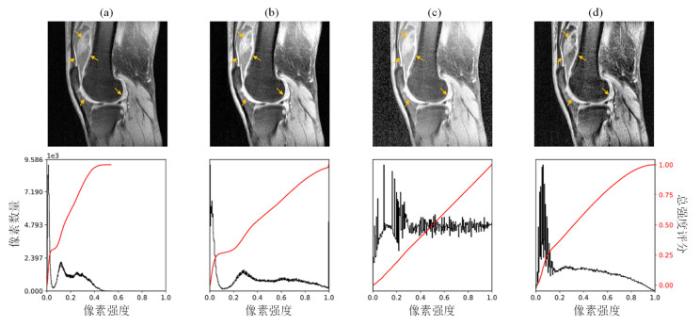
图5
使用不同图像对比度增强方法的效果对比. (a)原始图像,(b)对比度拉伸,(c)直方图均衡化,(d) CLAHE
Fig.5
Comparison of the effects of different image contrast enhancement methods. (a) Original image, (b) Contrast stretching, (c) Histogram equalization, (d) CLAHE
模型训练和数据预处理使用基于PyTorch的医疗影像深度学习框架MONAI 0.8.0,实验运行环境为NVIDIA GeForce RTX 2080Ti,操作系统为Ubuntu18.04,编程语言为Python3.7.本文所有模型训练超参设置相同,设定循环次数epoch为600次,学习率初始化为1e-4,优化器为Adam,损失函数选择Dice Loss.
为验证本文使用MemSwish激活函数的改进算法VNetTrans对滑膜磁共振图像进行3D分割的有效性,在训练超参设定相同的情况下,实验对比了:(1)UNet和VNet模型使用2D和3D卷积核分割的效果;(2)UNet和VNetTrans模型分别使用ReLU、Swish、MemSwish激活函数训练的分割效果;(3)使用MemSwish激活函数的VNetTrans模型和使用原文献相同激活函数的UNet、VNet、TransBTS、UNETR模型训练的分割效果;(4)针对使用MemSwish激活函数的VNetTrans模型的消融实验.
2.3 评价指标
本文使用Dice系数、相对体积差分(Relative Volume Difference,RVD)、灵敏度(Sensitivity)、特异性(Specificity)和豪斯多夫距离(Hausdorff distance,HD),来定量评估算法的分割性能.
对于给定mask的语义分割任务,G、P分别表示ground truth(真值)和prediction(预测值);G'、P'分别表示真值和预测值的表面点集,g'、p'属于G'、P'的子集;TP、FP、TN、FN分别为真阳性(被模型预测为滑膜的滑膜区域)、假阳性(被模型预测为滑膜的背景区域)、真阴性(被模型预测为背景的背景区域)、假阴性(被模型预测为背景的滑膜区域)的数量.
Dice系数对mask的内部填充比较敏感,而HD则对分割出的边界比较敏感.RVD用于评估过分割或欠分割,为正则表示过分割,为负则表示欠分割.灵敏度代表分割方法正确识别ROI像素的概率,特异性则代表正确识别背景像素的概率.HD使用真值和预测值的表面点集之间95%的距离,最小化离群值对HD计算的影响.
3 结果与讨论
3.1 2D和3D分割网络的对比
计算机视觉领域图像分割任务中的医学图像与自然图像之间存在数据维度的差异. 医学影像数据(例如CT、MRI等)多以3D数据形式存在,2D网络难以学习层与层之间具有相互关联的上下文信息,使用3D卷积核可更好的挖掘到数据的高维空间相关性. 本文选用UNet和VNet针对本分割任务使用不同维度卷积核分割,其中UNet选用3×3的2D卷积核和3×3×3的3D卷积核进行三次下采样,VNet选用相同卷积核进行四次下采样. 如表1所示,3D卷积核在两个网络模型分割的表现均优于2D卷积核,这表明对于本文分割任务而言,3D卷积核可更好的获取切片间的连续信息,实现更优的整体分割性能.
表1 2D和3D分割效果对比
Table 1
| 模型 | 卷积核维度 | Dice | HD/mm |
| UNet | 2D | 0.6489 | 89.8 |
| VNet | 2D | 0.6640 | 52.5 |
| UNet | 3D | 0.6528 | 72.2 |
| VNet | 3D | 0.6749 | 34.6 |
3.2 激活函数对比
本文选择3D UNet和VNetTrans网络来测试不同激活函数的表现. 如表2所示,在UNet模型上,使用MemSwish激活函相比较于原Swish函数整体网络训练耗时减少了12%. 相较于ReLU函数,Dice系数提升了0.014 2,HD减少了34.8 mm. 在VNetTrans模型上,使用MemSwish激活函数也使得整体的分割表现更优. 该实验表明在本分割任务中选用MemSwish函数可有效提升网络整体性能.
表2 在UNet和VNetTrans模型中采用不同激活函数的结果对比
Table 2
| 模型 | 激活函数 | Dice | HD/mm | 训练耗时 |
| UNet | ReLU | 0.6528 | 72.2 | 23min |
| Swish | 0.6613 | 50.8 | 34min | |
| MemSwish | 0.6670 | 37.4 | 30min | |
| VNetTrans | ReLU | 0.7140 | 33.6 | 5h58min |
| Swish | 0.7505 | 29.0 | 6h36min | |
| MemSwish | 0.7585 | 24.6 | 6h21min |
3.3 不同网络架构对比
表3 不同网络模型之间的结果对比
Table 3
| 模型 | Dice | Sensitivity | Specificity | RVD/% | HD/mm |
| UNet | 0.6528 | 0.7828 | 0.9864 | 33.84 | 72.2 |
| VNet | 0.6749 | 0.7262 | 0.9908 | 9.21 | 34.6 |
| TransBTS | 0.6996 | 0.7186 | 0.9917 | 4.87 | 36.0 |
| UNETR | 0.6355 | 0.6560 | 0.9920 | −3.31 | 68.8 |
| VNetTrans | 0.7585 | 0.7633 | 0.9943 | −1.34 | 24.6 |
相较于UNet网络,本文算法得到的Dice系数提升0.105 7,HD减少了47.6 mm,特异性提升了0.007 9. UNETR网络使用Transformer结构作为唯一的编码器,由于本分割任务的数据量较少,并不能充分利用该编码器提取特征信息,表3中UNETR网络的Dice系数低于仅使用CNN结构作为编码器的UNet和VNet网络,与一些实验研究[22]表明在数据量较少的情况下CNN结构表现优于Transformer结构一致,说明直接将Transformer结构作为编码器对于本分割任务而言并不合理. 先使用CNN进行高维度语义信息的提取,再将Transformer结构嵌入的本文算法可以更好的利用CNN获取局部特征所需数据量小以及Transformer获取全局特征的优势,提升网络性能. 相较于VNet,本文算法的Dice系数提升0.083 6,HD减少10 mm,敏感度和特异性上均有所提升,算法整体有欠分割的倾向,但相比其他模型RVD绝对值最小,总体分割误差最小.
图6
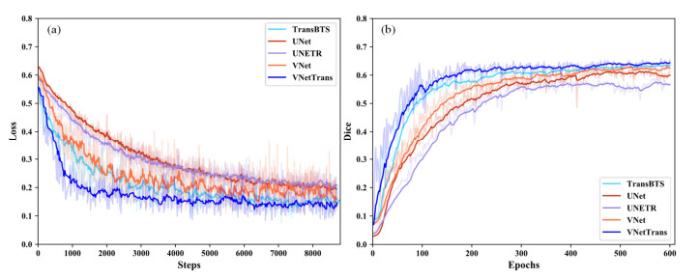
图6
基于不同网络的膝关节滑膜磁共振图像分割的训练过程. (a)训练集的loss曲线,(b)验证集的Dice系数曲线
Fig.6
Training process of knee joint synovial magnetic resonance image segmentation based on different networks. (a) Loss curves of training set; (b) Dice curves of validation set
使用不同网络模型对膝关节滑膜分割的结果比较如图7所示,图中选取了测试集的三个病例(上、中、下)进行展示,图中数值为对应模型分割结果的Dice系数. 对比可得,本文算法在分割结果上整体与医生的金标准最相近. 相较于其他网络模型,对于髌上囊处滑膜与肌肉组织间的区分更为清晰,且能很好的区别滑膜组织与积液. 相比于医生的勾画结果,在韧带、股骨下端与胫骨上缘周围许多细节部位的分割更为精细,弥补了医生不能手动逐像素点勾画的不足,整体边界流畅无毛刺,便于后期更好地进行滑膜容积测算,观察治疗期间用药情况的有效性.
图7
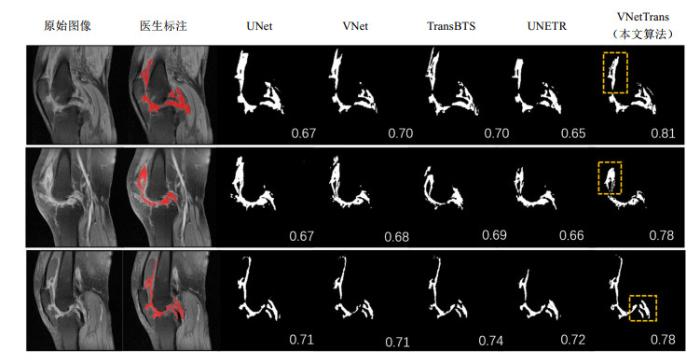
图7
不同网络模型的膝关节滑膜分割结果对比
Fig.7
Comparison of segmentation results of synovium of knee joint with different network models
3.4 消融实验
为进一步评估本文模型中Transformer模块和MemSwish激活函数的有效性,本文通过删除和替换该模块及激活函数,以确定两者对于网络性能的影响. 以在本文模型的基础上删除了Transformer模块,并选用ReLU激活函数的原VNet作为基础网络. 然后比较(1)基础VNet网络、(2)将基础VNet网络中的ReLU激活函数替换为MemSwish后的网络、(3)在基础VNet网络中加入Transformer模块后的网络、(4)在基础VNet中同时加入(2)、(3)操作后的网络(即本文网络)的分割性能(表4).
表4 消融实验
Table 4
| 网络模型 | 激活函数 | 是否加入Transformer模块 | Dice | Sensitivity | Specificity | RVD/% | HD/mm |
| VNet | ReLU | 否 | 0.6749 | 0.7262 | 0.9908 | 9.21 | 34.6 |
| VNet + MemSwish | MemSwish | 否 | 0.6962 | 0.7580 | 0.9904 | 14.92 | 35.8 |
| VNet + Transformer | ReLU | 是 | 0.7140 | 0.7527 | 0.9913 | 2.52 | 33.6 |
| This work | MemSwish | 是 | 0.7585 | 0.7633 | 0.9943 | −1.34 | 24.6 |
从表4可以看到,相比于基础VNet网络,替换了MemSwish激活函数后的网络的Dice系数提升0.021 3,加入Transformer模块后的Dice系数提升0.039 1.后者比前者的Dice系数提高0.017 8.说明Transformer模块相对于激活函数,对于网络整体性能提升的影响更大. 两者融合后的方法可以弥补仅改进激活函数后分割结果的过分割程度,相比基础VNet网络的敏感度和特异性分别提高了0.037 1、0.003 5.
4 结论
本文提出了一种基于3D VNetTrans网络的膝关节滑膜磁共振图像分割算法. 首先利用3D CNN生成特征图以捕获空间和深度信息,再利用Transformer编码器对于全局空间中的长距离依赖关系进行建模,最后在上采样路径中采用跳跃连接将下采样压缩路径中不同阶段的特征图进行融合,逐步得到高分辨率的分割结果. 实验结果表明,相比原VNet网络和其他主流分割算法,VNetTrans可得到较好的分割结果. 这归功于本文算法在下采样过程的不同阶段加入残差结构,增加网络深度的同时改善了网络退化和梯度爆炸的问题. 利用具有捕获长连接能力的Transformer模块加深网络对特征的学习能力,对于滑膜整体形态和分布有更强的学习能力. 同时,使用MemSwish激活函数相较Swish函数可有效减少显存占用提升网络训练速度.
但本文算法仍有需改进之处,存在对与软骨交界处、匍匐包绕十字交叉韧带生长的滑膜边界不能进行较好分辨的问题. 针对该问题,可在未来的工作中尝试利用不同模态的磁共振图像,引入多模态磁共振图像融合的特征进行学习,以更好的分辨膝关节不同组织的解剖位置.
无
参考文献
Rheumatoid arthritis
[J].DOI:10.1038/nrdp.2018.1 [本文引用: 1]
Chinese registry of rheumatoid arthritis (CREDIT): II. prevalence and risk factors of major comorbidities in Chinese patients with rheumatoid arthritis
[J].
2018中国类风湿关节炎诊疗指南
[J].DOI:10.3760/cma.j.issn.0578-1426.2018.04.004 [本文引用: 2]
2018 Chinese guideline for the diagnosis and treatment of rheumatoid arthritis
[J].DOI:10.3760/cma.j.issn.0578-1426.2018.04.004 [本文引用: 2]
Assessment of disease activity in rheumatoid arthritis using magnetic resonance imaging: quantification of pannus volume in the hands
[J].DOI:10.1093/rheumatology/37.8.854 [本文引用: 2]
Different approaches to synovial membrane volume determination by magnetic resonance imaging: manual versus automated segmentation
[J].DOI:10.1093/rheumatology/36.11.1166
Accurate quantitative assessment of synovitis in rheumatoid arthritis using pixel-by-pixel, time-intensity curve shape analysis
[J].
Assessment of synovitis in the osteoarthritic knee: comparison between manual segmentation, semiautomated segmentation, and semiquantitative assessment using contrast-enhanced fat-suppressed T1-weighted MRI
[J].DOI:10.1002/mrm.22401 [本文引用: 1]
Measurement of synovial tissue volume in knee osteoarthritis using a semiautomated MRI-based quantitative approach
[J].DOI:10.1002/mrm.27633 [本文引用: 2]
Neural networks for automatic scoring of arthritis disease activity on ultrasound images
[J].DOI:10.1136/rmdopen-2018-000891 [本文引用: 1]
Applying cascaded convolutional neural network design further enhances automatic scoring of arthritis disease activity on ultrasound images from rheumatoid arthritis patients
[J].DOI:10.1136/annrheumdis-2019-216636 [本文引用: 1]
Deep learning-based automated detection of human knee joint's synovial fluid from magnetic resonance images with transfer learning
[J].DOI:10.1049/iet-ipr.2019.1646 [本文引用: 2]
Fully automated segmentation of wrist bones on T2-weighted fat-suppressed MR images in early rheumatoid arthritis
[J].DOI:10.21037/qims.2019.04.03 [本文引用: 1]
基于改进U-Net的关节滑膜磁共振图像的分割
[J].
Magnetic resonance image segmentation of articular synovium based on improved U-Net
[J].
基于Dense-UNet++的关节滑膜磁共振图像分割
[J].
Magnetic resonance images segmentation of synovium based on Dense-UNet++
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}