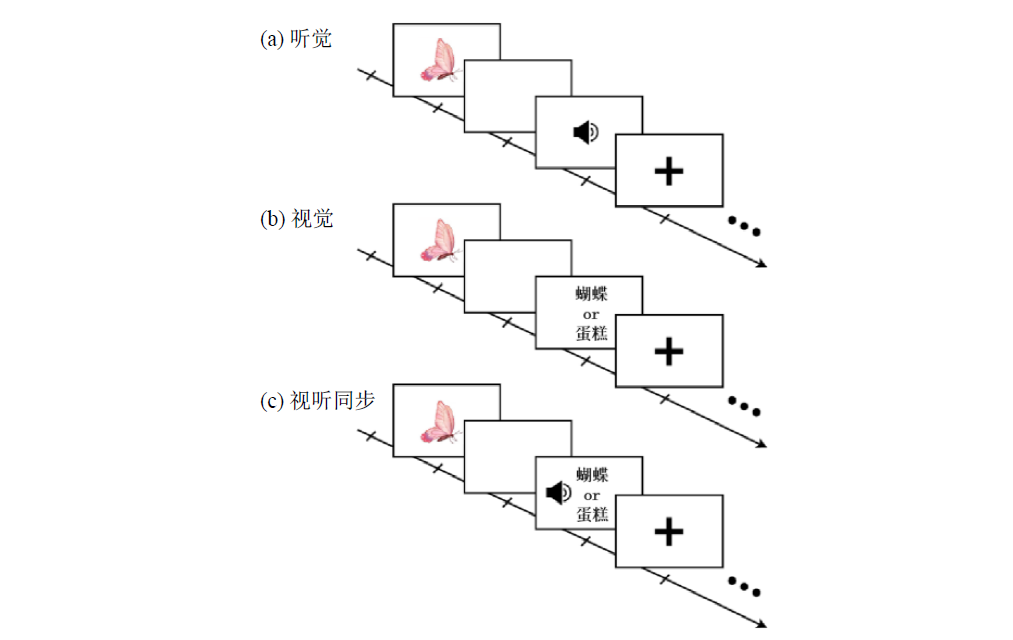
| [1] |
HÄMÄLÄINEN M, HARI R, ILMONIEMI R, et al. Magnetoencephalography—theory, instrumentation, and applications to noninvasive studies of the working human brain[J]. Rev Mod Phys, 1993, 65(2): 413-497.
|
| [2] |
MA H F, WU Y T, ZHAO W, et al. Research progress of magnetoencephalography in the functional mechanism of bilingual brain[J]. Chinese Journal of Biomedical Engineering, 2021, 40(4): 477-484.
|
|
马恒芬, 吴云涛, 赵文, 等. 双语脑功能机制的脑磁图研究进展[J]. 中国生物医学工程学报, 2021, 40(4): 477-484.
|
| [3] |
WANG X F, SUN X P, ZHAO X C, et al. Progress in biomagnetic signal measurements with ultra-sensitive atomic magnetometers[J]. Chinese Journal of Lasers, 2018, 45(2): 164-176.
|
|
王晓飞, 孙献平, 赵修超, 等. 超灵敏原子磁力计在生物磁应用中的研究进展[J]. 中国激光, 2018, 45(2): 164-176.
|
| [4] |
BOTO E, MEYER S S, SHAH V, et al. A new generation of magnetoencephalography: Room temperature measurements using optically-pumped magnetometers[J]. NeuroImage, 2017, 149: 404-414.
doi: S1053-8119(17)30041-1
pmid: 28131890
|
| [5] |
ZHANG X, CHEN C Q, ZHANG M K, et al. Detection and analysis of MEG signals in occipital region with double-channel OPM sensors[J]. J Neurosci Meth, 2020, 346: 108948.
|
| [6] |
CHEN C Q, ZHANG X, GUO Q Q, et al. Moving wearable magnetoencephalography measurement study based on optically-pumped magnetometer[J]. Chinese J Magn Reson, 2022, 39(3): 337-344.
|
|
陈春巧, 张欣, 郭清乾, 等. 基于原子磁力计的穿戴式脑磁图动态测量研究[J]. 波谱学杂志, 2022, 39(3): 337-344.
doi: 10.11938/cjmr20222975
|
| [7] |
ZHANG S, CAO N. A synthetic optically pumped gradiometer for magnetocardiography measurements[J]. Chinese Phys B, 2020, 29(4): 040702.
|
| [8] |
CHEN M J, LIAO S X, YANG H C, et al. Nuclear magnetic resonance and imaging of hyperpolarized 3He using high-Tc superconducting quantum interference device in microtesla magnetic fields[J]. Chinese J Magn Reson, 2010, 27(3): 386-395.
|
|
陈名杰, 廖书贤, 杨鸿昌, 等. 采用超导量子干涉组件在微特斯拉磁场下获取超极化3He的核磁共振波谱和影像(英文)[J]. 波谱学杂志, 2010, 27(3): 386-395.
|
| [9] |
AN X W, CAO Y, JIAO X J, et al. Research on cognitive mechanism and brain-computer interface application in visual-auditory crossmodal stimuli[J]. Journal of Electronic Measurement and Instrumentation, 2017, 31(7): 983-993.
|
|
安兴伟, 曹勇, 焦学军, 等. 基于视听交互刺激的认知机理与脑机接口范式研究进展[J]. 电子测量与仪器学报, 2017, 31(7): 983-993.
|
| [10] |
陈露. 视听双模态脑机接口中不同语义相关性的大脑视听信息竞争响应研究[D]. 天津: 天津大学, 2021.
|
| [11] |
GEUZE J, VAN GERVEN M A, FARQUHAR J, et al. Detecting semantic priming at the single-trial level[J]. PLoS One, 2013, 8(4): e60377.
|
| [12] |
TANAKA H, WATANABE H, MAKI H, et al. Electroencephalogram-based single-trial detection of language expectation violations in listening to speech[J]. Front Comput Neurosci, 2019, 13: 15.
|
| [13] |
MORTIER S, TURKEŠ R, DE WINNE J, et al. Classification of targets and distractors in an audiovisual attention task based on electroencephalography[J]. Sensors (Basel), 2023, 23(23): 9588.
|
| [14] |
PIRES G, BARBOSA S, NUNES U J, et al. Visuo-auditory stimuli with semantic, temporal and spatial congruence for a P300-based BCI: An exploratory test with an ALS patient in a completely locked-in state[J]. J Neurosci Meth, 2022, 379: 109661.
|
| [15] |
CHANG J L, ZHANG B L, TAN Z J, et al. Design and pilot study of word-picture matching semantic judgment task based on chinese high frequency nouns[J]. Chinese Journal of Rehabilitation Theory and Practice, 2018, 24(8): 917-923.
|
|
常静玲, 张斌龙, 谭中建, 等. 基于汉语高频名词下词图匹配语义判断任务的设计与运用范式[J]. 中国康复理论与实践, 2018, 24(8): 917-923.
doi: 10.3969/j.issn.1006-9771.2018.08.010
|
| [16] |
LU S, GUO T. A comparative study of pictorial and lexical semantic processing based on visual- auditory modality[J]. Journal of Guizhou Education University, 2023, 39(6): 19-26.
|
|
卢飒, 郭婷. 基于视听通道的图片和词汇语义加工比较研究[J]. 贵州师范学院学报, 2023, 39(6): 19-26.
|
| [17] |
CHEN K X, FAN X Y, CAO S P, et al. Probabilistic language pathways based HARDI tractography[J]. Chinese J Magn Reson, 2010, 27(3): 417-424.
|
|
陈可欣, 范馨亚, 曹书萍, 等. 基于高夹角分辨率扩散磁振造影神经径路追踪的人脑语言机率路径图谱[J]. 波谱学杂志, 2010, 27(3): 417-424.
|
| [18] |
GAO W J, LI Q, CHEN P Y, et al. The correlation between the structural properties of the arcuate bundle and the performance of language comprehension is analyzed by limiting spherical convolution[J]. Chinese J Magn Reson, 2016, 33(2): 269-280.
|
|
高雯菁, 李锵, 陈品元, 等. 应用限制球形卷积解析弓状束的结构特性与语言理解表现的相关性[J]. 波谱学杂志, 2016, 33(2): 269-280.
doi: 10.11938/cjmr20160209
|
| [19] |
MUELLER J L, HAHNE A, FUJII Y, et al. Native and nonnative speakers' processing of a miniature version of Japanese as revealed by ERPs[J]. J Cognitive Neurosci, 2005, 17(8): 1229-1244.
pmid: 16197680
|
| [20] |
WOLFF S, SCHLESEWSKY M, HIROTANI M, et al. The neural mechanisms of word order processing revisited: electrophysiological evidence from Japanese[J]. Brain Lang, 2008, 107(2): 133-157.
doi: 10.1016/j.bandl.2008.06.003
pmid: 18667231
|
| [21] |
HAGOORT P, BROWN C M. ERP effects of listening to speech compared to reading: the P600/SPS to syntactic violations in spoken sentences and rapid serial visual presentation[J]. Neuropsychologia, 2000, 38(11): 1531-1549.
pmid: 10906378
|
| [22] |
CORREIA J M, JANSMA B, HAUSFELD L, et al. EEG decoding of spoken words in bilingual listeners: from words to language invariant semantic-conceptual representations[J]. Front Psychol, 2015, 6: 71.
doi: 10.3389/fpsyg.2015.00071
pmid: 25705197
|
| [23] |
LI D, HUO L, WAN M Y, et al. Application of radiomics based on new support vector machine in the classification of hepatic nodules[J]. Chinese J Magn Reson, 2022, 39(3): 278-290.
|
|
李笛, 霍雷, 万梦云, 等. 基于新型支持向量机的影像组学在肝脏结节分类中的应用[J]. 波谱学杂志, 2022, 39(3): 278-290.
doi: 10.11938/cjmr20212916
|
| [24] |
WANG N, WANG Y J, LIAN P. Prediction of preoperative T staging of rectal cancer based on radiomics[J]. Chinese J Magn Reson, 2022, 39(1): 43-55.
|
|
王楠, 王远军, 廉朋. 基于影像组学的直肠癌术前T分期预测[J]. 波谱学杂志, 2022, 39(1): 43-55.
doi: 10.11938/cjmr20212908
|
| [25] |
YANG R, SONG L. Application analysis of machine learning algorithm in the field of motor imagery brain-computer interface[J]. Beijing Biomedical Engineering, 2023, 42(4): 432-438.
|
|
杨荣, 宋亮. 机器学习算法在运动想象脑机接口领域的应用分析[J]. 北京生物医学工程, 2023, 42(4): 432-438.
|
| [26] |
许晓燕. 基于深度学习的脑机接口算法研究[D]. 济南: 齐鲁工业大学, 2020.
|
| [27] |
CHOI Y J, KWON O S, KIM S P. Design of auditory P300-based brain-computer interfaces with a single auditory channel and no visual support[J]. Cogn Neurodynamics, 2023, 17(6): 1401-1416.
|
| [28] |
SENGUPTA R, JANAPATI R, KRISHNA D, et al. A comparative analysis of P300 based BCI in visual and auditory domain[J]. IBRO Neurosci Rep, 2023, 15: S894
|
| [29] |
GUO L J, ZHANG X Y, CHEN G J. Audio-visual hybrid brain-computer interface based on space-frequency domain features[J]. Computer Engineering and Design, 2020, 41(6): 1755-1761.
|
|
郭柳君, 张雪英, 陈桂军. 基于空-频域特征的视听混合脑机接口[J]. 计算机工程与设计, 2020, 41(6): 1755-1761.
|
| [30] |
DESOUZA J F, OVAYSIKIA S, PYNN L. Correlating behavioral responses to FMRI signals from human prefrontal cortex: examining cognitive processes using task analysis[J]. J Vis Exp, 2012, (64): 3237.
|
| [31] |
TONG W, YAN G L. Review of “Word Satiation” research paradigms and experimental tasks in language cognitive processing[J]. Journal of Tianjin Normal University (Natural Science Edition), 2013, 33(4): 87-96.
|
|
仝文, 闫国利. 语言认知加工“饱和”现象的研究范式及实验任务述评天津师范大学学报[J]. 天津师范大学学报(自然科学版), 2013, 33(4): 87-96.
|
| [32] |
PUGH K R, SHAYWITZ B A, SHAYWITZ S E, et al. Cerebral organization of component processes in reading[J]. Brain, 1996, 119(4): 1221-1238.
|
| [33] |
DIWADKAR V A, CARPENTER P A, JUST M A. Collaborative activity between parietal and dorso-lateral prefrontal cortex in dynamic spatial working memory revealed by fMRI[J]. NeuroImage, 2000, 12(1): 85-99.
pmid: 10875905
|
| [34] |
HAGOORT P. On Broca, brain, and binding: a new framework[J]. Trends Cogn Sci, 2005, 9(9): 416-423.
pmid: 16054419
|

 )
)